第一回 簡易PostScriptインタプリタを作ろう
第一回 簡易PostScriptインタプリタを作ろう
やる事
- ハッシュ、線形リスト、スタックの実装
- 簡単なインタープリタの実装
- 言語はPostScriptのサブセット
- 実行可能配列(関数リテラル相当)、ifelse、repeatくらいまで
- 3000行くらい。
PostScriptのサブセットを実装してみたいと思います。
最初はForthを実装しようとしたのですが、制御構造の実装がやや面倒なので、 その辺がよりシンプルで美しいPostScriptに変更します。(その歴史的な理由でフォルダ名などはforth_modokiになっています。すみません)。
PostScriptは触るとすぐわかるけど説明するとややこしい言語仕様なので、作りながら言語仕様自体の説明はしていきます。 なお、PostScriptは全く知らなくてもOKです。
この回の狙い
- 簡単なパーサーの書き方を学ぶ
- 言語の処理系を実装する事でプログラム言語自体の理解を深める
- 基本的なコレクションを実装する
- ファイルの分割とインターフェースを考える事を学ぶ
- そこそこのコードを書く過程で良いコードの書き方を学ぶ
- ついでにスタックマシンも学ぶ
01 intのパーサーを作ろう
とりあえずintのパーサーを作る所から始めてみましょう。 初回なので進め方の説明もします。
githubでの作業の進め方
- githubのアカウントを作る
- https://github.com/karino2/c-lesson/ をforkする
- 自分のc-lessonをローカルにcloneする
- ローカルで、karino-orignというブランチを作って、remoteにhttps://github.com/karino2/c-lesson.git を指定する
- 問題は毎回ローカルでブランチを作り、ブランチをgithubにはプッシュする(マスターはいじらない)
こんな感じで作業をしていきましょう。
今回の問題は、01_int_parserというブランチでやるとします。
int_parserの問題をやってみよう
sources/forth_modoki/01_int_parser/int_parser.c を修正しassertを通るようにしてcommitしてpushしてみて下さい。
初回なのでとりあえず自己紹介くらいのつもりでさらっとお願いします。 scanfは使わないでください(ASCIIから数字への変換を見る目的なので)
02 intのパーサーを作ろう(getc編)
01では文字列をパースしました。
パーサーを作る時には、バッファにいったん読み込むか一文字ずつ取るか、という選択が最初にあります。 今回はファイルから一文字ずつ取る(つまりgetcやfgetc相当の物を使う)、という前提でパーサーを書きましょう。
今回はcl_getc()という関数をこちらで用意するのでそれを使ってください。
パーサーとは何か
intのパーサーではそれほど考える必要もない事ですが、 今後だんだんと複雑にしてくので、ここでパーサーというものについて少し考えてみましょう。
パーサーというのは、PostScriptにおいては、文字を読んで行って、字句、というものに分割するものの事を言います。 字句というのはようするに「種類と値のペア」と思ってだいたい良い。 字句はトークンともいいます。
字句は数字とか記号とかを一単位とします。(以下具体例を見ていく方が分かりやすい)
パーサーとトークナイザ
PostScriptでは字句に分割するとほぼパースが終わるので区別がありませんが、より複雑な言語だと字句に分けるものをトークナイザ、それを文法に従い分類するのをパーサーと言う事があります。
C言語では古くからトークナイザはlex、トークナイズされた物を文法に合わせて解釈する事をyaccというツールで担当していました。今ではその互換のflexやbisonがそれぞれ標準的に使われていると思います(最近の事情はあまりウォッチしてないので推量で)。
lexは正規表現とその種別のIDを指定しておくと、文字列を読み込んで正規表現に従って字句に切って種別のIDを教えてくれるCコードを生成します。
yaccは(確か)LALR(1)の文法を記述したファイルを渡すと、それに合わせて字句の列を還元してくれるCソースコードを生成します。
lexもyaccもC言語のコードを自動生成してくれるコマンドです。
ただ個人的にはyaccに相当する物を必要とするような用途は、近年ではC言語の守備範囲より外になったと思っています。
そういった目的ではgolangあたりを使う方が良いでしょう。
また、かつてはこのlex-yaccの組み合わせが定番だったので両者の区別に意味はありましたが、近年は正規表現は言語に標準で組み込まれているのでlex相当の物はあまり出番がなくなりましたし、パーサーコンビネータを始めとする最近のパーサーの仕組みでは、トークナイザとパーサーの区別も曖昧です。
その辺の事情と昨今のC言語の実態を踏まえて、このシリーズでは以前はトークナイザと呼ばれていた物もパーサーと呼びます。文字列やバイナリを読んでいって何かしらの構造を再構成する物をパーサーと広い意味で呼ぶのは、
2018年現在では適切な表現だと自分は思っています。
一回の単位
使い勝手を考えると、一回parse_one()とか呼ぶと、一つ字句が返ってくるのが良い。
“1234 abc”とあったら、一回目のparse_one()では1234という数字を返し、次のparse_one()では’ ‘を返し、その次のparse_one()では”abc”を返すのが良い。
読んでしまった文字をどうするか
パーサーでは、例えば数字をパースするためには数字の一つ先の文字まで読む必要がある。 バッファに読み込んで作業するなら問題ないけれど、今回のようにcl_getc()で一文字ずつ読む場合、数字の次の文字を読んでしまった後に次のparse_one()にどう渡すか、という問題がある。
これはパーサーの性質による所だけど、標準的な文法では、いつも先読みは一文字までで大丈夫になっている。 興味のある人はLALR(1)の文法を調べると良いと思いますが、 今回はそんな難しい事は必要なくて、「一文字だけ先読みを許せばかなりいろんなものがパース出来る」という事だけ知識としてしっておけば良いと思います。
すると最後に読んだ文字、を返すようにし、次の呼び出しの時にそれを渡すようにしないといけない。 また、その文字が無ければ存在しない文字を渡す必要がある。これは’\0’で良いでしょう。
途中の場合は今回は考えない
また、パース対象が途中の物がありうるのか?というのもインターフェースを考える時に大切になります。 例えばユーザーが対話的に文字を入力する、というケースでは、 まだ終わってない状態でパースしたい事があるかもしれない。
そういう場合に最後のトークンは本来未確定なので、そこから再開できるようにインターフェースを考えないといけない。
ただ今回は、ハードコードした文字列でもファイルでも、いつも最後まで読み切れる、という前提でコードを書く事にします。
呼び出し元に返す必要があるもの
ここまでの話をまとめると、
- 字句のタイプ
- 字句の値
- 読んでしまった次の文字
の三つを返す必要があります。
実際の作業手順
次に実際にどう進めるか、という話をしていきます。 最新のレポジトリではsources/02_int_parser_getc/が出来ているので、 この中のint_parser_getc.cを書き換えます。
gitでfork元の更新を持ってくる
二回目なのでgitの解説を追加しておきましょう。 今回は02_int_parser_getcというブランチで作業する事にします。
まずこれを執筆中の2018/9/23日現在では、ここのサイトと同時に課題となるソースコードも更新している状態です。
そこで前問の状態から私がいろいろ更新しているので、新しく問題を解く時には、私の最新版を取ってきて、そこからブランチを作ります。(後日やる人はこの作業は必要ありません。知識として目を通すくらいで先に進んでください)
まず、karino-originに私の最新版を持ってきます。
git checkout karino-origin
git pull
次に、masterをkarino-originと同じ状態にします。
git checkout master
git merge karino-origin
一応github上のmasterを更新しておきます。
git push
次にこのmasterから今回用のブランチを作ります。
git checkout -b 02_int_parser_getc
このように、karino-originとmasterはいつも私のレポジトリの最新版と同じにして、 問題を解くときはその時点の最新版のmasterからブランチを作って下さい。
作業の進め方
まず字句のタイプを表すenumを作りましょう。NUMBERとSPACEでいいと思います。
次にparse_one関数を作りましょう。 字句の種類と値と先読みしてしまった文字を返す必要があります。
returnで先読みしてしまった文字を返し、字句の種類と値は引数で返しましょう。 返す用の引数はout_という名前にします。例えばint *out_val, int *out_typeなどです。
このparse_oneの型が決まったら一旦enumと合わせてgitterで見せて下さい。
次にこのparse_oneを実装して、それを使うコードを書きます。
今回はPostScriptを実装するので、連続するスペースは一つにしてしまって構いません。 parse_oneを’1 2’とスペースが二つある所に呼んでも、三回目は2を返してください。 二回目の値はスペース一つのフリをする、でOKです。
UnitTestを書こう
とりあえずparse_oneの実装が出来て動いたら、UnitTestも書けるようにします。 (本来は順番が逆で先にUnitTestを実装するのですが、今回は教える内容の都合でこの順番にしています。)
UnitTestとは成功してるとOKとだけ表示するテストです。 失敗するとどこで失敗したかを表示します。 そして関数一つとか二つとか、なるべく小さい単位のテストを書きます。
細かい書き方はおいおい説明していくとして、まずはUnitTestを書けるようにcl_getc()を拡張しましょう。
cl_getc()に外部から入力を指定できるようにする
現状はハードコードされたinputを元に順番に文字を返すcl_getc()ですが、 UnitTestの事を考えると外から文字を設定出来る方が望ましいです。
そこで、外部から文字を設定するAPIを足しましょう。
void cl_getc_set_src(char* str);
とします。これをヘッダファイルに足してcl_get.cの中に実装を書いてください。(posを0にリセットするのを忘れずに!)
これが終わったらいったん見せて下さい。
基本的なUnitTestを足そう
それでは次にUnitTestを足します。 テストは最初は”123”という内容に対してparse_oneがどうふるまうべきか、というテストを書いて、mainから呼ぶ事にします。
テストの関数の名前は
void test_parse_one_123()
としましょう。
mainはこんな感じにします。
int main() {
int answer1 = 0;
int answer2 = 0;
// ここから違う
test_parse_one_123();
// 入力を元に戻す
cl_getc_set_src("123 456");
// 以下は元どおり
// ...
// verity result.
assert(answer1 == 123);
assert(answer2 == 456);
return 1;
ここまで終わったら一回見せて下さい。
空白のあるケースのUnitTestを足そう
次にtest_parse_one_123_456を追加しましょう。”123 456”に対してどう動くか、というテストです。
ちゃんと間の空白もテストしてください。
以後はこのUnitTestで問題を出す事にします。 それを見ながら、UnitTestとはどういう物かをなんとなく学んでいって下さい。
03 intとシンボルと特殊文字のパーサーを作ろう
それではここまで書いてきたパーサーを、int以外にも拡張しましょう。 とりあえず、
- 「{」
- 「}」
- 「executable name」
- 「literal name」
の4種類の要素を追加する事にします。
まず最初の二つ、「{」はOPEN_CURLY、「}」はCLOSE_CURLYというenumとしましょう(curly braceで中かっこの意味)。
ここで見かけない言葉が二つありますね。executable nameとliteral nameです。
PostScriptの二つのname
nameとはPostScriptにおける変数名の事です。 abcなどですね。
PostScriptには二つのnameがあります。 executable nameとliteral nameです。
この二つが何なのかはあとで説明します。 現時点ではパースする対象としてそういう二つがあると思ってください。 パースに必要な事だけここでは説明します。
最初に例を挙げると
executable name
- abc
- hello
- x
- abc123
などがexecutable nameです。変数に使われます。
literal name
- /abc
- /hello
- /x
- /abc123
などがliteral nameです。スラッシュで始まって、あとはexecutable nameと同じです。
厳密な言い方をするとexecutable nameは、「ローマ字で始まってスペース以外が続く文字で構成された文字列」です。
「literal name」はスラッシュで始まり、そのあとローマ字から始まる文字列です。 ここはPostScriptはもっと変なものもnameに使えますが、サブセットという事であまり細かい仕様は決めない事にします。
簡単のため、nameは254文字以下としましょう。 255文字以上のnameは来ないものと仮定して、エラー処理などはしなくてOKです。 最初のスラッシュと最後のヌル文字も入れた256をNAME_SIZEとしてdefineしておくので、必要に応じて使ってください。
executable nameは、EXECUTABLE_NAMEというタイプで文字列をmallocして返す事にしましょう。
literal nameはLITERAL_NAMEというタイプで文字列をmallocして返す事にします。 この時、先頭のスラッシュは取り除いてください。
トークンの型を定義しよう
これまではout_valとout_typeという二つの変数で表していましたが、これを構造体にまとめる事にします。
以下のようにしたいのですが、
struct Token {
enum LexicalType ltype;
int value;
};
ただ今回、valueはintじゃないものも入ります。 具体的には
- int
- 一文字のchar(’{‘, ‘}’, ‘ ‘のどれか)
- mallocしたchar*へのポインタ
の三つのどれかになります。
charをintに入れるのは仕様上OKなのですが、ポインタは64bit CPUの場合入らない場合があります(C言語の仕様としては入らなくても入ってもOKなので実装依存)。
そこで、これらを全部入れる、unionを定義したいと思います。
unionを使って複数のトークンのどれかを表す構造体を作る
さて、union。 Cの入門書には必ず書いてあるけど、読んでも構造体との違いが良くわからないものの代表ですね。
ここでまた良く分からないunionの説明を繰り返してもいいのですが、どうせ読んでもなんだか良く分からないと思う。 という事でここでは、実際に使ってみながら勝手に学んでもらう、という方針を取る事にします。
今回は以下のように定義します。
struct Token {
enum LexicalType ltype;
union {
int number;
char onechar;
char *name;
} u;
};
これをどう使うのか、は、03_parser/parser.cの中のparser_print_all()を読んでみて下さい。
parse_one()を実装しよう
ここからは、parse_one()とそのUnitTestを実装してもらいます。
今回は私が構造体の定義やparse_one()のシグニチャなどを準備しておきました。 そこでまずは私の書いた内容を理解する事から始めてみてください。
03_parserというブランチを切って作業してください。
parser_print_all()を読む
まず大きな関数として、parser_print_all()というのがあります。 これはparse_one()を呼び出してトークンをprintする、という事をしています。
この中で、tokenとそのtoken.uがどう使われているかを見る事で、unionの使い方を理解してみてください。
freeしないの?
parser_print_all()は、token.u.nameをfreeしてません。これはメモリリークになります。
長く動き続けるプログラムであればfreeはすべきです。
そうで無い場合にどうするか?というのは意見が割れる所で、C言語においてfreeをすべきかどうかは定期的に論争が発生します。
このシリーズでは、まぁまぁグローバルに生き残る物や説明上それほど重要でないと思う時もfreeしない事にします。と思って書いて言ったらfreeする場所一箇所も無かった…
この辺は結構適当に決めるので、気になるなら自分でfreeしてくれてもOKです。
長く動き続ける組み込みのプログラムなどではリークは大問題なのでちゃんと全部解放出来ているのかをすごく時間をかけてチェックしますし、
この忘れは製品の回収騒ぎにまで発展し、結構な被害総額を生む事もあります。
だから組み込みで使われるC言語において、free忘れは重大違反だ…というとそうとも言い切れなく、組み込みで長く動く類のCプログラムはそもそもmalloc自体しない(そういうものが無いなど)という場合も結構あります。
Unixなどのサーバーで長くデーモンとして動くような物でもメモリリークは大問題となります。ですが、そういう用途でC言語を使う事は随分減りました。
C++であればそもそも手でdeleteを呼ぶのでは無く、スマートポインタなどを使ってスタックに置く方が正しいので、やはりfreeに相当するものを頑張ってチェックする、という機会はあまりありません。
カーネルの中やドライバなどでは相変わらずfreeし忘れは大問題です。この用途でC言語が使われる事は多く、またmallocに相当するものが必要になるものも結構ありますね。
この辺をやる人の場合は議論の余地なくfreeし忘れは大問題です。
C言語でどれくらいmallocしたものをfreeしなくてはいけないシチュエーションが多いか、は時代に依る話で、昨今は随分減ったというのが自分の認識です。
リソースの管理として終了が必要なものはあるのだから最初からしっかりクセをつけるべきだ、というのも一理あると思いますが、そこから先は宗教戦争になるので読者の皆様が好きにしたら良いでしょう。
二つのUnitTestを読む
次にUnitTestが二つだけ用意されています。 この二つを読んでみてください。 test_parse_one_number()は前回書いてもらった物とほとんど変わらないので、読めばわかると思います。
test_parse_one_empty_should_return_END_OF_FILE()は前回あまり明確に決まりを作らなかった、 空っぽのファイルを読ませたらどうふるまうべきか?という事についてのテストです。 今回は最後まで読んだ後にparse_one()を読んだら、END_OF_FILEというタイプを返すべき、という事に決めようと思います。
まずはUnitTestを通すだけのparse_oneを実装する
既に書かれているコードの内容を理解したら、まずmainのparser_print_all()をコメントアウトし、 UnitTestを通す事から始めます。 前回とほとんと同じ内容となるので、前回のコードからコピペしてきて書いて下さい。
ここまで終わったら一度私に見せてください。
executable nameのテストを足して実装しよう
executable nameは、ローマ字で始まって空白以外が続く文字としましょう。 テストとしては、以下で始めてください。
char* input = "add";
char* expect_name = "add";
int expect_type = EXECUTABLE_NAME;
テストが追加出来たらparse_oneを実装する前に一回このテストがfailする事を確認します。
そのあとにparse_oneを実装してください。
literal nameのテストを足して実装しよう
executable nameとほとんど同じですが、literal nameはスラッシュ、つまり’/’から始まる、という所が違います。
テストとしては、
char* input = "/add";
char* expect_name = "add";
int expect_type = LITERAL_NAME;
としましょう。expect_nameにスラッシュが無い事に注意してください。
このテストもfailするのを確認してからparse_oneを実装してください。
中括弧も実装しよう
以下同様にOPEN_CURLYとCLOSE_CURLYも実装してください。 全部が終わったら、最後にparser_print_allを実行してみて動く事を確認してください。
動かなかったら必ずその理由を明らかにするUnitTestを追加してから直しましょう。
out引数について(ローカルルール)
C言語一般で決まっている訳では無いが、個人的には採用しててこのシリーズでも従ってもらいたい規約を、ローカルルールとしてたまに提示します。 1つ目はout引数についてです。
C言語では、結果を一つしかreturn出来ないので、2つ以上の結果が必要な時には、ポインタ引数で結果を受け取る場合が多いと思います。 こうした結果を受け取る目的の引数の名前は、out_で始めてください。
out_で始めた引数は原則として結果を入れるだけで、入ってくる値を使ってはいけません。 配列みたいな時にはこの区別はやや曖昧ですが、その辺は自分の常識に従って適当にやってください。
これはC#のout引数を名前つけルールで真似している物です。 C言語はあんまりこういう規約を作りすぎるとC言語らしい単純さが損なわれていまいちですが、 ちょっとは入れた方が読むのが楽というのもあり、 この辺のバランス感覚は個人個人で違う所だと思います。
このシリーズではとりあえず私のバランス感覚でいろいろ書くので、ひとまず従って最後まで終えたあとに、 以後は自分で勝手に変えて自分なりの結論を出していただけたらと思います。
UnitTestの名前づけルールいろいろ
ここではUnitTestについてのちょっと応用的な話を簡単に書いてみたいと思います。 C言語はいろいろとUnitTestに向いてない部分もあるので、 原則を知った上でCではどう妥協するか、みたいな順番で考えるのが良いと思っています。
UnitTestの読みやすさの意義
UnitTestは一般に
- セットアップ
- テスト対象の呼び出し
- 結果の検証
の三ステップに分けられる事が多く、この構造がぱっと見わかりやすい方が良い。
また、テストは実際のソースよりも、時間がたってfailした時に「パッと見て何が書いてあるかわかる」事が重要です。
だいたいのケースで、UnitTestを見る時、というのは、何かを追加したり変更すると昔の変なテストが壊れる、 というシチュエーションになります。 読む人は今変更した場所や追加した部分については良く知っていて、けれど壊れたテストは知らない、という事になる。 そこで、何が起こったかをコードを読まずに見えるだけでわかるようにしておきたい。
UnitTestのローカル変数の名前つけ規則(ローカルルール)
一般的に決まっている訳では無いけどこのシリーズではルールとしたい事として、expect, input, actualの名前つけルールがあります。
ローカル変数として、UnitTestではだいたい
- 入力
- 結果
- 期待値
の3つが登場する事になるので、これには決まった名前をつけておきたい。 そこで入力をinput、結果をactual、期待値をexpectというローカル変数に、なるべく入れる事にしたいと思います。
さらに、UnitTestの開始はなるべくinputとexpectの2行から始まる事にしたいと思います。
こうする事で、最初の三行がいつも
- テストの関数名
- input
- expect
で始まるようにしておき、この三行を見るだけでなるべく何をテストしているのかわかるようにしたい。
なお、これは原則なので、actualが無い場合はそんな変数は要りませんし、expectがそのままハードコードの方が明らかに読みやすい時は一旦変数に入れなくても構いません。
ただ、慣れてくるとUnitTestを書く時、まずinputとexpectを書く、という事から書けるようになります。 これはAPIのデザインを考える時に良い習慣であるのと、 またUnitTestを書くスピードも上がるので、メリットは多い習慣だと思います。
inputが複数ある場合はinput1とかinput_hogeとか、適当に名前をつけて下さい。expectやactualも同様です。
スマートassert
何度も言いますが、UnitTestはだいたい
- setup
- テスト対象の実行
- 結果の検証
に分かれます。この概念的な構造がわかりやすいのが良いテストです。
さて、検証の所は複雑なコードになる事がちょくちょくあります。何を検証しているのか、ちょっと見わかりにくい。 そういう時は、何を検証しているのかがひと目でわかるようなassert_XXを作るのが良いです。 これをスマートassertと言います。
例えばassert_element_eqとか、assert_stack_numberとか、とにかく検証している事をわかりやすくした名前で、なるべくこのassertを並べるだけで検証の部分は読めるようにしておきたい。
変な構造体を一時的に定義して何かで取り出してそれの一部をチェックする、みたいなコードがたくさん続くのは避けたい所です。
callとverifyのコンベンション
何度も言いますが、UnitTestはだいたい
- setup
- テスト対象の実行
- 結果の検証
になります。 そこで、これらのテストを書く時のヘルパー関数もパターンが決まっているので、決まった名前の規約があります。
1と2を合わせてやるのを、call_XXXと呼びます。 2と3を合わせてやる、または1と2と3を合わせてやるのをverify_XXXと呼びます。
これはC言語だとネームスペース的な仕組みが無い為、特にcall_XXXは使うべきか微妙ですが、 知識として知っておいて良いと思います。
概念的に同じような事ばかりしていると感じたら、verify_XXXを作って共通化する事は良い習慣だと思います。
04 スタックを作ろう
数字とリテラルネームを出し入れ出来るスタックを作りましょう。
stack.cとstack.hというファイルに実装し、stack_push, stack_popという関数と、 stack_print_allを作って下さい。
スタックサイズは
#define STACK_SIZE 1024
くらいでお願いします。
ブランチ名は04_stackでお願いします。
まずインターフェースを決める
まず04_stackというディレクトリを作って、その中で作業してください。 今回はファイルから全部自分で作って下さい。ブランチもこれまで同様作ってください。
スタックには数字とリテラルネームの二つをpushしたりpopしたり出来る必要があります。
とりあえずstack_push()、stack_pop()の型が決まったらいったん見せて下さい。
次にUnitTestを書く
何もないときにpop呼んだ時、一つpushしたとき、一つpushしてpopした時、二つpushしてpop二回した時の内容をそれぞれチェックする位のテストを書いて見せて下さい。 なお、テストを書くのにstack_push()とstack_pop()以外が必要になったら適宜追加してください。
そのあとはそれを実装します。
なるべく、一度でテスト一つずつ通すように実装を進めます。
まず何もない時にpop呼んだ時のテストを通るだけのコードを書き、 次に一つだけpushがちゃんと動くように張りぼてっぽいものを書き、次に二つのpushが動くちゃんとした実装に直す、という具合です。
05 addだけのevalループを作ろう
ここまでパーサーとスタックを作ったので、PostScriptのコアとなるevalを書く事が出来るようになりました。 これを実装していきましょう。
PostScript入門
まずevalを作るにあたり、今更ですが、そろそろPostScript自体の話をしていきましょう。 なお、GhostScriptという物が入っている環境がある場合、gsというコマンドで対話的インタプリタが立ち上がっていろいろ試す事が出来ます。
数字だったらpush
まずPostScriptにはスタックというものがグローバルに一つあります。 で、プログラムは空白区切りでテキストを区切って読んで行って、 数字だったらこのスタックにpushします。
だから、
1 2 3
と書いてあったら、スタックに1をpushし、次に2をpushし、次に3をpushします。
文字の単語なら関数と思って実行
addとかsubとかにぶつかると、関数呼び出しと思って実行します。
addというのは、スタックから二つ数字を取り出して足し算して結果をスタックに積みます。 だから、
1 2 add
と書いてあるとインタープリタは先頭から読んでいって、
- まず最初に「1」を読んでスタックにプッシュします。
- 次に「2」を読んでスタックにプッシュします。
- 次に「add」を読んだら、これは数字じゃないので関数だと思ってaddを実行します。
addを実行すると何が起こるかはaddという関数の仕様という事になります。 PostScriptでは関数と呼ばず実行可能ネームと呼びますが、ここでは関数と言ってしまいます。なお余談ですが、親戚にあたるForthでは実行可能ワードと呼びます。
addは
- スタックから2つ値を取り出して
- それを足して
- 結果をプッシュする
という振る舞いをします。スタックにはこの場合1と2が入っているので、これを取り出すと、 スタックは空になります。 次に1+2を計算して、結果をスタックにプッシュするので、最終的には3が入ります。 疑似コードで書くと以下みたいな振る舞いです。
var a = pop();
var b = pop();
push(a+b);
以上を踏まえると以下のコードは何が起こるでしょうか?
1 2 3 add
答えだけ言うと、スタックには1と5が残ります。1が残る理由は分かるでしょうか?
1 2 add 3 add 4 add 5 add
と、
1 2 3 4 5 add add add add
は同じ結果になります(たぶん)。
3+2*(2+1)+4なら、
3 2 2 1 add mul add 4 add
とか書けます。数式からPostScriptに直すのは慣れればすぐ出来ますが、 PostScriptのコードから数式に戻すのはちょっと脳への負荷がありますね。
以後、必要になる都度他の要素は解説していきます。
外部サイト
必要な事は適宜解説していくつもりですが、ちゃんと一気に学びたい、というなら、 以下のサイトなどで学ぶと良いと思います。 PostScriptはすごくシンプルな言語仕様なので、他のプログラム言語の経験があれば主要な機能は10分くらいで学ぶ事が出来ると思います。凄い。
ただ言語の性質上、プログラム言語以外の解説が多いので手頃な解説が少ないという難点があります。
- PostScript 基礎文法最速マスター
言語自体の解説として割と良いが、実行可能配列の解説が後ろの方なのがこのシリーズ的には惜しい。 - PostScript Language Tutorial & Cookbook (なんかリンク切れになってしまったのでタイトルだけ)
いわゆるBlue Book。例がプリンタ周りの事が多いので名前ほど入門向けでは無いけれど、最後のBuilt-inのプリミティブの一覧が便利。 - PostScript Language Program Design (なんかリンク切れになってしまったのでタイトルだけ)
いわゆるGreen Book。英語が読めるならこの2.3から2章の終わりまでを読むのも良い。ただしプリミティブの説明は無いのでBlue Bookの最後と併用する。
今回実装する事
以上を踏まえて、とりあえずaddが動くようにしましょう。subやmulも実装してもいいんですが、 後で書き直す事になるのでやめておきます。
3 4 add
や、
3 7 add 5 add
などが動くようにevalループを書きましょう。
最後にスタックの中身が空じゃなかったら、その中身を出力するようにしておきます。
まず前の課題から、パーサーとスタックを持って来よう
05_evalのディレクトリの中を実装していきますが、パーサーとスタックは自分が作ったものを持ってきて下さい。 別のブランチで作った物をどう持ってくるのか?という問題があるかもしれませんが、いったん別のディレクトリにcpするとかの原始的な方法でOKです。 (わからなかったらgitterで聞いて下さい)
main関数は#if 0でコメントアウトしておいて下さい。
スタックのインターフェースをどうしたかが人に依るので、eval.cのUnitTestでスタックの中をチェックするコードは書いてません。 そこも書いてまずはリンクを通してテストがfailするのを確認します。
数字をスタックにプッシュするだけのテストを通そう
evalはparse_one()を呼んで、その中に応じて処理をswitchする感じになります。 03_parserで最初にparser.cに書いてあった、parser_print_all()を参考にしてみてください。 数字だったらpushする、は比較的簡単だと思います。
次にaddの処理をハードコードしよう
数字は比較的簡単と思います。 次はEXECUTABLE_NAMEですが、まずは
int streq(char *s1, char *s2);
という関数をstrcmpあたりを使って作ってください。イコールなら1、違ってたら0を返す感じです。
次に、nameが”add”だったら、スタックから二つ値をpopして足した結果をpushする、というコードを普通に書いてしまいましょう。 これでUnitTestは通るはずです。
将来的には関数ポインタなどを使う事になりますが、現時点ではここまでで次に進みましょう。
最小限のインタープリタが完成!
ここまで来ると、インタープリタとして最小限の機能が通る事になります。 cl_getc()をファイルから読み込むように直すのは簡単でしょう。(あとでやるのでまだやらなくてもOKです)
まだ足し算しか出来ませんが、それでもパースしてevalする、 インタープリタのコアとなる骨組みは出来た事になります。
ここまででも、結構複雑なプログラムを動かす事が出来ます。 例えば
1 2 3 add add 4 5 6 7 8 9 add add add add add add
とかやると、たぶん動くでしょう。ゆとりなので答えが幾つになるか知りませんが、なんか出ると思います(55だっけ?)。 やろうと思えばmulやsubやdivも実装は出来るでしょう(ですがこの辺は後でハッシュ実装したあとの方が都合が良いのでここではまだ実装しなくてOKです)。
インタープリタは実装した物がそのまま動く普通のプログラムと違って、 食わせたコードが動くので、実装した時点では考えてない振る舞いをさせる事が出来る所に、 ちょっとなんかソフトウェアを作った、って感じがしますよね(著者個人の感想です)。
とは言ってもこれではifもループも関数定義も無いので、まだまだインタープリタと他人に自慢出来る程ではありませんね。 という事で関数を作っていくべく、次はdefの実装に移りましょう。
06 原始的な辞書を作り、literal nameにdef出来るようにしよう
/hoge 123 def
としたら、以後
hoge
とすると123と書いたのと同じになるようにしましょう。 ここからは前回の05_evalに追加していく形で作業したいのですが、名前が05だとややこしいので、 interpreterというディレクトリを作り、ここに前回の05_evalをすべてコピーして、 以後このinterpreterというディレクトリで作業していきましょう。
前回の最後の状態から、新たに06_literal_nameというブランチを作り、そこで作業していってください。
literal nameをスタックにプッシュしよう
まず、リテラルネームはスタックにプッシュするようにevalを書き換えましょう。 ここからはnameをリークさせるかちゃんと解放するかで結構コードが変わって来ますが、 今後は一度mallocした文字列は解放しない、という前提で書いて行きます。 勉強目的ですしね。
さて、解放を考えないなら、literal nameをpushするのはintとほとんど変わらないと思います。 intの変わりにポインタを入れて、さらにタイプとしてliteral nameを表すenumを入れればいいだけでしょう。
解放したいならリファレンスカウントがオススメ
勉強目的ではリークする方がオススメですし、実際に使う時もリークで構わない事がほとんどだと思います。例えば真面目にVMを作る時も、そもそもコンスタントな文字列の扱いはmallocで別々に取ったりせずにコンスタントプール的なものをちゃんと作る事になりますし、
一見するほどこの手のコードでちゃんとfreeしなくてはいけないシチュエーションは多くはありません。
ですが、もし真面目にfreeしてみよう、と思ったら、いちいち必要に応じてmallocしたりfreeしたりを繰り返すよりも、リファレンスカウントを実装するのが簡単でオススメです。
循環参照でリークするのは皆の知る通りですが、PostScriptでそれが発生するのは稀なので、昔のJavaScriptのリークほどひどい事にはなりません。
リファレンスカウントを実装するなら構造体に文字列ポインタの他にref_countみたいな変数を持たせて、mallocした時に1にし、以後スタックにコピーする時などには+1し、スタックからポップする時やparse_oneで得た構造体が要らなくなった時などには-1します。0になったらフリーします。
リファレンスカウントを使ってリーク無くコードを書く方法にはCOMなどで長い歴史があり、
結論とでも言うべきルールも出来上がっています。これを参考にするのが良いでしょう。
英語だと例えばMSDN:The Rules of the Component Object Modelの「Reference-Counting Rules」に記述があります。
実装は簡単な割には動いているのを確認してリークなくしたりしていくのはまぁまぁ楽しいので、趣味として一回くらいやってみても良いと思います。
ただし、そこまでやるならC言語以外の選択肢を検討するタイミングかな、と個人的には思いますね。 C++ならshared_ptrとかありますしね。
defを実装する
今回は数値だけのdefを実装します。 defはちょっと難しいので少し丁寧に説明します。
そもそもdefとはどんなものか?
defはスタックのtopから二番目に入ってるリテラルネームに、topの値を束縛します。
コードの例を見てみましょう。
/hoge 123 def
これは、他の言語でいう、例えば
var hoge = 123;
とかと同じような意味です。 以後はこのhogeを、
hoge 2 add
とかいう風に、まるで123という数字のように使えます。
defは必ずスタックの二番目にリテラルネームが入っている、という前提で機能します。 入ってない時はprintfでそのむね出力して、あとは好きにして下さい。(無視して動いてもexitで終わってもOK)。
まずは辞書のAPIを考える
defを実装する為には、変数で値をルックアップ出来る何かが必要になります。 他の言語では辞書を使う所ですね。 そこでここでは、まず辞書のAPIを考えて、一番単純だが遅い実装から始めます。
辞書としては、スタックと同じ要素が入れられればいいでしょう。 スタックの時の構造体を使ってください。 ここではそれが
struct Element {
...
}
という名前の構造体だったとして解説を書きます。(別に違う名前で構いません。説明の都合です)
すると辞書のAPIとしては、
void dict_put(char* key, struct Element *elem);
int dict_get(char* key, struct Element *out_elem);
void dict_print_all();
の三つくらいがあれば良いでしょう。dict_getは、キーが無ければ0を、キーがあれば1を返すとします。
最初の実装:配列に入れて、ひたすらstreq
最初は、一番頭を使わない実装でいきましょう。 以下のような配列を使って、先頭から順番に入れていく、という実装にします。
static int dict_pos = 0;
struct KeyValue {
char *key;
struct Element value;
}
static sturct KeyValue dict_array[1024];
dict_putは以下のような感じで実装します。
void dict_put(char* key, struct Element *elem) {
if(すでにキーがdict_arrayに入ってたら) {
dict_arrayのその場所をelemで上書き;
} else {
dict_array[dict_pos] = KeyValue(key, elem);
dict_pos++;
}
}
もちろんこれは疑似コードなので、これをC言語に翻訳してください。
同じ変数に二回defした時に、ちゃんと前の変数を上書きするように気をつける、という事以外は、 別に注意すべき事も無いでしょう。
1024回よりもputされたら配列があふれますが、その時のコードは書かなくていいです(どうせすぐ書き直すコードなので)。
dict_get()は、
int dict_get(char *key, struct Element *out_elem) {
for(int i = 0; i < dict_pos; i++) {
if(streq(key, dict_array[i].key)) {
out_elemに結果を詰める。
return 1;
}
}
return 0;
}
という感じにします。 ただ、dict_putの所でこのiに相当するものが必要になると思うので、その辺はちゃんと書き直してください。
これに簡単なテストも書いて実装してみてください。
defを実装しよう
これが実装出来たら、次はdefを実装します。 例として、
/abc 12 def
というコードを考えましょう。 defが呼ばれる時点では、スタックには「/abc 12」の2つの要素が入っています。
そこで疑似コードで書くと以下のような事をします。
int val = pop();
char* literal_name = pop();
dict_push(literal_name, val);
これに相当する事をC言語でちゃんと実装してください。
eval時に、定義された変数が出てきたら、中身に置き換えるコードを書く
ここまででdefが実装出来た事になるのですが、これだと変数への代入相当だけが実装出来ただけで、 変数を「使う」コードが入っていません。そこで次にそれを実装します。
eval()のEXECUTABLE_NAMEの所で、辞書にそのnameが入っていたら、中身に置き換える、という処理をやります。 疑似コードで書くと以下のような感じです。
if(tokenがEXECUTABLE_NAME) {
if(streq("add", name)) {
....
} else if(streq("def", name)) {
....
} else if(nameがdictに入っていたら) {
int val = dict_get(name);
stack_push(val);
}
}
こんな感じのコードになります。
これで、以下のようなコードが動くようになりました。
/abc 12 def
abc abc
ここまでで一旦コードをpushして私に見せてください。
07 辞書の実装をハッシュテーブルに置き換えよう
さて、前回作った辞書。 おもちゃならあの実装でも十分ですが、少し効率が悪い。 というのも、dict_getでstreqをエントリの数だけ実行する事になるからです。
そこで次に、勉強の目的も兼ねて、もっと普通の実装に改善してみましょう。
普通は辞書の実装には、二分木(及びその改良版のバランスドツリー)かハッシュテーブルを使います。 今回はハッシュテーブルを実装する事にしましょう。
なお、以下の作業を始める前にちゃんと上の単純な実装でUnitTestを書いて、動く事を確認しておいて下さい。(ハッシュテーブルはバグりがちなので、テストをある程度書いてから書く方が良い)。
ハッシュテーブルの基本
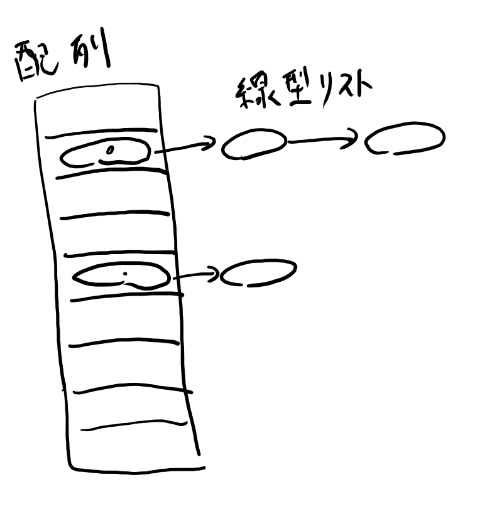
ハッシュテーブルは文字をキーにして値を保存するデータ構造です。
実装としては「ハッシュ関数+配列+線形リスト」で構成されます。 まず配列には線形リストの先頭が入ります。
説明の為、保存する値はintだけとし、以下のようなコードを前提に考えます。
struct Node {
char *key;
int value;
struct Node *next;
};
struct Node *array[1024];
実際に実装する時には1024はTABLE_SIZEとかマクロで定義しておいて下さい。
ある文字列を与えると、その文字列を0から1023のどれかの数字に割り当てる関数を用意して、 その配列から始まる線形リストのどこかに入れます。
どうやって0から1023の数字を生成するかはどうでもいいのですが、
- なるべくバラける事
- 同じ文字を入れたらいつも同じ数値になる事
の2つの条件を満たしている必要があります。 この文字から0から1023のどれかの数値を計算する関数がハッシュ関数です。
簡単なハッシュ関数の実装例
ここでは簡単なハッシュ関数として、「全ASCIIコードを足して1024で割った余り」をハッシュ関数としましょう。 あまりはC言語ではパーセントで計算出来ます。つまり以下のような感じになります。
int hash(char *str) {
unsigned int val = 0;
while(*str) {
val += *str++;
}
return (int)(val%1024);
}
この実装だと、ASCIIコードはだいたい70とかその辺の数字なので、3文字くらいでは210とか小さめのキーばかりが返ってくる為、あまり良いハッシュ関数ではありません。 ただ、簡単に実装出来るので今回はこれでいきたいと思います。 改善案としては、適当なランダムな数字、例えば179025684622をこのvalだけ右にビットローテートして1024で割る、とか、一文字足すごとに7777倍するとかいろいろ考えられますが、今回はやりません。
ハッシュ関数を使ったdict_push()の擬似コード
さて、こうして得られたarray[hash(key)]をリストのheadとして、あとは普通の線形リストのコードとなります。 dict_put()の場合なら、
void dict_put(char* key, int value) {
int idx = hash(key);
struct Node *head = array[idx];
if(head == NULL) {
headをallocする
head->next = NULL;
headのkeyとvalueをセット;
array[idx] = head;
return;
}
update_or_insert_list(head, key, value);
}
みたいな実装になります。update_or_insert_list()は通常の線形リストと同じ実装で、 すでにkeyのnodeがあったらそのvalueを上書き、なければ新しくnodeをつくって末尾に追加します。 線形リストは世の中にたくさん解説があると思うのでここでは解説しません。ググってみるなり本を読むなりしてください。(誰か良いサイトとか知ってたら教えてください。ここにリンク貼ります)
こういう風に
- hash関数で文字列から配列のindexを得る
- 配列から線形リストの先頭を得る
- 線形リストをたどってkeyと同じノードを探す
という三段階の作業をするのがハッシュテーブルです。
実際に実装してみよう
ではすでに実装してあったdict_push()とdict_get()をハッシュテーブルで実装しなおしてみましょう。 正しく実装すればさきほど書いてあったUnitTestが全部通るはずです。
普通ハッシュテーブルはあまり衝突しないくらい大きめの配列でやるのですが、今回は勉強も兼ねてある程度衝突するようにTABLE_SIZEは16でやってみましょうか(ASCIIコードを考えて衝突するテストケースも作ってみてください。その場合はハッシュ関数などのアルゴリズムに依存してる事をコメントするように)。
ここまででdefの基本的実装が終わりました。
PostScriptの辞書を実装したいなら
PostScriptではコレクションとして辞書を作って使う事が出来ます。
JavaScriptやPythonと同じですね。
今回のシリーズではやりませんが、もしこれを実装したいなら、今回作ったハッシュテーブルの辞書を少し変更するだけで実装出来ます。
現状の実装だとarrayをグローバル変数で持っているのですが、これをmallocで取るように変えて、幾つも辞書を作れるように変更するだけです。
辞書はPostScriptでは他の言語で言うローカル変数を実現する為にも使えます。
今回辞書を少し真面目にハッシュテーブルで実装した背景には、
PostScriptの辞書をサポートしたくなったらちょっとの変更で出来る程度には仕組みを理解しておこう、という気持ちがあったりします。
dictを解放する時の説明動画を作りました
線形リストのfreeの所はmallocに慣れていないと混乱しそうなので、動画を作ってみました。 良く分からない人は参考にどうぞ。
08 プリミティブを辞書に登録しよう
ユーザーが定義したものではない、処理系から最初から入っている関数などを「プリミティブ」と呼びます。 addとかdefとかの事です。Built-inと呼ぶ事もあります。
現状はevalの中でハードコードされていますが、 これではsubやmulなどを追加していくと、evalがどんどん読みにくくなってしまいます。 そこでこれらのプリミティブを追加してもevalのコードに影響がないように変更しましょう。
その為には、前回実装したユーザー定義のexecutable nameと似たような感じでaddやdefも扱います。
関数ポインタの話
プリミティブを登録するには、関数ポインタを登録する必要があります。 関数ポインタはC言語の入門書を読んだだけだとちょっと不安がある項目だと思うので、簡単にここで解説しておきます。
関数ポインタはシンタックスがややこしいだけ
関数ポインタは、C言語において関数を変数に入れる方法です。 といっても最近の言語を経験した人からすると、関数を変数に入れて渡したり出来るのはむしろ当然でしょう。 実際Pythonなどでは普通に変数に入れてよそに渡したり出来ます。
そこで最近の言語から入った人にとっては関数ポインタは、
- 名前が難しそう
- シンタックスが変
という2つを克服すれば良いだけの、割とちょろい話です。 1は「関数ポインタ」という言葉には大した意味が無いと思ってもらえば十分です。
という訳でここでは2の話をしておきます。
C言語では、関数の宣言で、名前の所をカッコでくくってアスタリスクをつけると関数ポインタの宣言となります。
例えば普通の関数が、
int hoge(int a, int b);
という宣言だった場合、この型と同じ型の関数ポインタは
int (*hoge)(int a, int b);
で宣言出来ます。 hogeを(*hoge)にすると関数ポインタになる訳ですが、ややこしいのはこのhogeが「変数名になる」事です。普通の変数とは大分シンタックスが違います。
比較の為に、普通のintのポインタ変数と並べてみましょう。
// intのポインタ変数
int* hoge;
// 関数ポインタのポインタ変数
int (*hoge)(int a, int b);
つまり、int (*hoge)(int a, int b)はhogeという変数を作るのです。
この変数に関数の関数ポインタを代入する事が出来ます。 例えば、以下のような関数があった時に、
int ika(int a, int b);
この関数を先程の関数ポインタの変数に代入出来ます。
hoge = ika;
このように、変数hogeに代入出来る訳です。 代入した関数ポインタは、普通にカッコをつけて呼ぶ事が出来ます。
hoge(3, 4);
関数ポインタといいつつ代入する時にアンパサンドが要らなかったり、呼ぶ時にアスタリスクが要らなかったりしますが、 いろいろ理屈をこじつけるよりは、C言語はこの辺いい加減だから、と割り切って覚えてしまう方が良いでしょう。
辞書に関数ポインタを代入する場合
さて、我々の目的としては、addやdefの処理をする所を関数に分離して、 その関数を辞書に入れたい。 辞書にはElementという構造体を入れるとして、enumとして種類をつけているとします。
C言語の関数の種類を足して、unionにフィールドを足せば辞書に入れられそうです。
まずはenumはELEMENT_C_FUNCという名前としましょうか。 そしてunionは、以下のようになります。
enum ElementType {
...
ELEMENT_C_FUNC
};
struct Element {
enum ElementType etype;
union {
...
void (*cfunc)();
} u;
};
これに代入する場合は、
elem.u.cfunc = add;
などのようになります。 呼ぶ場合は以下のようになります。
elem.u.cfunc();
関数ポインタも使っていくと分かる類の事だと思うので、この位の説明でとりあえずやってみて下さい。
addを辞書に登録しよう
では試しにaddを関数ポインタにして辞書に登録し、evalから抜き出してみましょう。 以下の手順になります。
- addを単体の関数にする
- 辞書のElemに関数ポインタも追加出来るようにenumなどを追加
- evalでElementの型を見てC関数なら呼ぶ
- mainでaddを辞書に入れる
順番に見ていきましょう。
1. addを単体の関数にする
すでになっていればいいのですが、現状はevalの中に埋め込まれいてる人もいると思います。 疑似コードで書くと、eval()の中に以下のような意味のコードがあるんじゃないでしょうか。 (C言語なのでstack_pop()はもっと複雑なはずです。あくまで擬似コードで)
if(tokenがEXECUTABLE_NAMEなら) {
if(token.u.nameが"add"なら) {
int a = stack_pop();
int b = stack_pop();
stack_push(a+b);
} else if(token.u.nameが"def"なら){
...
} else {
// ユーザー定義のname。辞書からnumberを取り出してスタックにプッシュ
...
}
}
まず、この”add”の時のif文の中を関数にします。
void add_op(){
int a = stack_pop();
int b = stack_pop();
stack_push(a+b);
}
// evalの中
if(tokenがEXECUTABLE_NAMEなら) {
if(token.u.nameが"add"なら) {
add_op();
} else if(token.u.nameが"def"なら){
...
} else {
// ユーザー定義のname。辞書からnumberを取り出してスタックにプッシュ
...
}
}
こうしてadd_opという関数を出来たら、次に辞書にこれを登録出来るように辞書の方を拡張します。 それは先程関数ポインタの方で軽く説明してあるので自力でやってみてください。
3 evalでElementの型を見てC関数なら呼ぶ
先程のevalの所のコードで、EXECUTABLE_NAMEの所の処理に、ELEMENT_C_FUNCの時の処理を追加します。 疑似コードで書くとだいたい以下のようになるでしょう。
// evalの中
if(tokenがEXECUTABLE_NAMEなら) {
if(token.u.nameが"def"なら){
...
} else {
// ユーザー定義のnameかプリミティブ。
struct Element elem = dict_get(token.u.name)
if(elem.etype == ELEMENT_C_FUNC){
elem.u.cfunc();
} else {
//ユーザー定義のname。辞書からnumberを取り出してスタックにプッシュ
}
...
}
}
これであとはadd_opを辞書に登録するだけです。
4 mainの先頭の方で関数を辞書に登録
疑似コードで言うと以下のようなコードを書いて、mainから呼んで下さい。
void register_primitives() {
dict_push(add_op);
}
これで今までのテストが全て通るはずです。試しに実行してみてください。
そのほかのprimitiveもこの形に直す
addが無事動いたら、primitiveを増やす時です。 まずはdefも関数として登録してください。
それが終わったらsub, mul, divも実装してみましょう。 今回は小数は出したくないので、divは整数の割り算であまりは切り捨てて下さい。
subはどっちからどっち引くのかがわかりにくいので書いておくと、以下のコードは2がスタックに置かれるのが期待値です。
5 3 sub
09 実行可能配列を実装しよう(ここが大変)
他の言語で言うと所のラムダ式とか関数リテラルと呼ばれる物を、PostScriptでは実行可能配列と言います。 実行可能配列はPostScriptの中心となる仕組みで、制御構造などのブロックとして使われたり、 変数に代入して関数として使われたりします。
ここではこの実行可能配列を実装してみましょう。
PostScriptにおける実行可能配列
まずは実装する実行可能配列というのがどういう物かを見ていきます。
まずは具体例
まず例としては、以下のようなコードが挙げられます。
/onetwo {1 2} def
このようにしたら、以後onetwoと書くと 1 2と書いたのと同じになります。
また、例えば以下のように書くと
/plusone { 1 add } def
以後 plusone と書いたら 1 add と書いたのと同じになります。
具体的な振る舞い
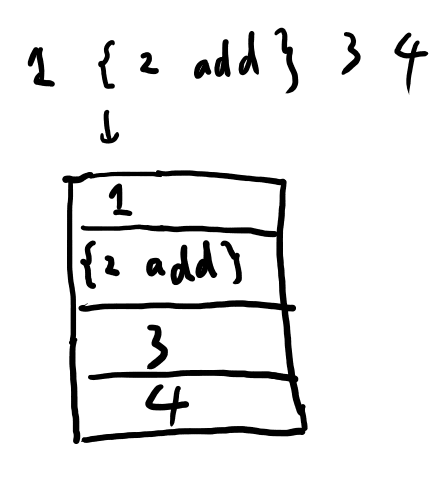
実行可能配列は、中括弧で始まって中括弧閉じで終わる物です。 間にはPostScriptのコードが書かれますが、evalされた時点ではこの中のコードは実行されません。
中の命令列をそのまま保持したまま、数字などと同様にスタックにプッシュされます。
この実行可能配列を実行する方法は幾つかありますが、 一番簡単なのは変数に代入して、その変数を評価すると実行出来ます。
つまり
/add3 { 3 add } def
という風にadd3という変数に入れて、これを
4 add3
というふうに実行する訳です。こうするとスタックには7が入ります。
つまり実行可能配列とは
- 開き中括弧で始まり閉じ中括弧で終わる
- 間にはPostScriptのコードが並ぶが、実行はその場ではされず、そのまま保持された状態でコード片のままスタックに積まれる
- 後で変数などを通して評価されると実行される
という物です。 実行の所はあとでifやrepeatが出てくるともう少し具体的な例が出せるので、まずは変数に代入して変数を評価するパターンだけを考えましょう。
具体的な実装の話
実行可能配列という物がどういう物かはなんとなくわかったので、次に実装方法を考えます。 まずは実装の選択肢から見ていき、その後注意すべき所を説明します。
実装方法の選択肢
ここは何種類かやり方が考えられる所です。
- 中括弧の中を文字列でそのまま持っておいて、実行したくなったら文字列をevalする
- パースしたトークン列をそのまま持っておいて、実行したくなったらこのトークン列をevalする
- (簡易)バイトコードの配列に変換して持っておいて、実行したくなったらバイトコードを実行する
- JITして関数ポインタにしておいて、プリミティブと同じように実行する
1はevalの実装はほとんどそのままで良いので簡単ですが、パーサーをいじって文字を返すようにしないといけません。 中括弧はネストする可能性があるので、ちょっとしたステートマシーンにする必要があります。 今回は文字列を扱いませんが、文字列も扱うと文字列の中に中括弧が出てくる場合もあるので、より難しくなります。 ただ全体的にはかなり簡単な実装方法と言えます。
2はパーサー自体はほとんどいじらなくても良く、evalもトークンを得る所だけちょっと細工すれば良いので、それほど難しい事はありません。 これが一番簡単かな?
3は論理的には結構2と違うのですが、実装してみると2とかなり似た物になります。 もともとPostScriptは言語がバイトコードに近いので、違いは中括弧が無くなるのと、ネストしている時に初回のeval時の処理がネストするくらいです(それが大違いなのですが)。 概念的にはこれはスクリプト言語をコンパイルしてバイトコードを生成する事になります。
4のJITはさらに本格的にした物ですね。これはmallocした領域にコードを書いて関数ポインタにキャストして呼ぶ事になりますが、実行可能ビットを立てるなどCPUやOSによっては追加で必要な作業が出てきます。 また、走らせる環境のマシン語の知識が必要となります。 今回の内容からすれば無駄に複雑な話なので却下で良いのですが、GCとかJITのようなより高度な機能を勉強したい時に、PostScriptはコアがシンプルなので簡単に追加出来て勉強に向いていると思います。
今回はあえてちょっと難しい3でやってみましょう。 バイトコードにコンパイルする、厨2魂を満足させてくれる響きだ。(著者個人の見解です)
簡易バイトコードのデータ構造
バイトコードはPostScriptの命令を表す要素の配列です。 一番簡単な物としては、パーサーが返すTokenか、スタックや辞書が扱うElementを使う事でしょう。
ここではバイトコードはElementの配列としましょう。 これまでexecutable nameがElementには無かったと思いますが、 バイトコードにする為にはexecutable nameも必要になるので追加しておきます。
実行可能配列のオブジェクト自体もElementに追加しましょう。 ここで問題になるのがElementの配列をどう保持するか、です。
通常C言語では配列の先頭のポインタを配列として保持します。 ですがこれだけでは長さが分かりません。 そこでどうにか長さを知らせる必要があります。
選択肢は幾つか考えられますが、良くあるのは以下くらいでしょうか。
- 終わりを表す特殊なElementを最後の印とする
- 先頭に長さを埋め込む
- unionの中にstructをネストしてintの長さを表すフィールドも作る
- ポインタのポインタにして最後をNULLにしておく
1と2が良くある気がします。 1は番兵とかセンチネルとか言われる物ですね。これでもいいかな、と思いますが、 今回は勉強の為に2で行こうと思います。 以下2以外の解説をしておきます。
4は要素自身が文字列などの可変長の場合は良くありますが、今回みたいなケースではあまりありませんね。
3は、unionは最大の要素のサイズがいつも使われるので、3を選んでしまうとバイトコートのサイズが膨れてしまいます。 1と2ならenumが1バイトの、32bitマシンならポインタやintが4バイトなので一命令5バイトですが、 選択肢3を使うと1+4+4で一命令9バイトになります。(細かい事を言うとメモリ上ではパディングがあるのでもっと大きいですが)。
このシリーズのここまでのノリなら9バイトでも別にいいじゃん、という気もしますが、普通は3は無いかなぁ。
一応選択肢3のコードを簡単に書いておくと、以下のようなコードです。
struct Element {
enum ElementType etype;
union {
...
struct {
Element *byte_codes;
int len;
} exec_array;
} u;
};
今回はC言語の勉強という事なので良くある定石を学ぶという意味でも2でやってみましょう。 以下2のやりかたについて説明していきます。
flexible arrayを使って連続領域に長さと構造体の配列を埋め込む
C言語では配列の長さが実行時にしかわからなかったり、インスタンスごとに変わる場合には、 以下のように構造体の最後に配列をサイズ0で埋め込むのがイディオムとなっています(なお、古いコンパイラ向けにサイズを1にしているコードも見かけるかもしれません)。
struct ElementArray {
int len;
struct Element elements[0];
};
この長さが0の配列宣言は特殊な意味があって、sizoeofの時にはこのElement型の配列の直前までのサイズとなります。(「確保の仕組み」の所の図参照)。 この長さが0の配列をflexible arrayと言います。
こうして、確保する時には配列の領域も足して確保します。例えば要素が3つの場合は以下のように確保します。
struct ElementArray *arr = (struct EelementArray*)malloc(sizeof(struct ElementArray)+sizeof(struct Element)*3);
構造体の型としてはarr->elements[1]などとするとエラーになりそうな物ですが、 C言語は確保した領域さえあれば実行時に宣言した時より先の所に触っても文句を言わないので、 問題ありません(仕様上はflexible arrayじゃない場合は宣言より先のアクセス動作は未定義らしいですが、駄目なコンパイラは自分は見た事無いし、何にせよflexible arrayなら問題無い事が保証されています)。
そこでこうやって先頭に長さを持たせて、その次に配列の型を書いておいてmallocの時に要素分だけ多く確保する事で型宣言時には表せない長さの変わる配列を表現します。
なお、仕組み上構造体の最後の要素でしかこのテクニックは使えないので、2つの可変長配列を一つの構造体に持つ事は出来ません。
ソースコードとしてはこのElementArrayのポインタをunionに持たせれば話は終わりです。
struct Element {
enum ElementType etype;
union {
...
struct ElementArray *byte_codes;
} u;
};
ですが、以下C言語の勉強という事で、良い機会ですのでflexible arrayについて、補足をいろいろ書いておきます。
確保の所の仕組み
mallocに渡している以下の式について補足します。
sizeof(struct ElementArray)+sizeof(struct Element)*3
最初のsizeofでは、以下の図のように、lenとパディングを含んだ値が返ってきます。
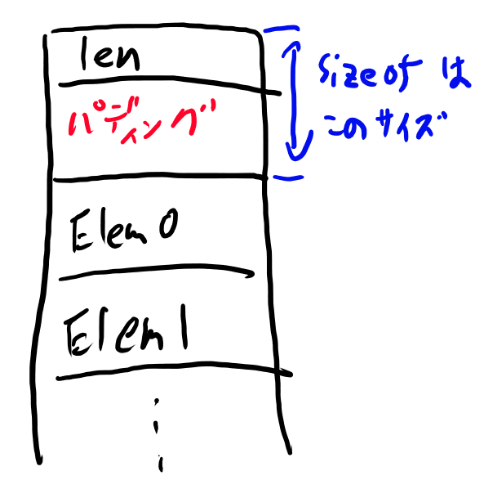
パディングは32bit環境だとこの場合は0、64bit環境だと4バイトになると思います。 これはCPUの制約からこうしておく方が効率的なのでCのコンパイラが環境に合わせて勝手に隙間を開ける為です。 詳細はこのシリーズでは踏み込みません。
struct Element elements[0];
と宣言に書くと、sizeofではこのサイズは一切含まれません。ちょっと特殊な振る舞いですね。 こういう0要素の配列は、今回のように構造体の最後に入れる時にしか使いません。
こうして、上記のmallocで、先頭の長さと以後の配列の両方を含んだ連続領域が確保されます。
配列の長さは確保したら以後は固定
このイディオムでは、配列の長さはmallocした時に決まります。あとから伸ばしたりは出来ません。 そういう用途には埋め込むのではなくてポインタ変数にします(後述のElementArray2参照)
静的な型としては配列の手前までしか無い
ElementArrayの型には、配列部分の長さは含まれていません。 この事から幾つかの通常のC言語の機能が動かない事になります。 少し考えればわかる事だとは思いますが、勉強の為、幾つかここで指摘しておきましょう。
例えば、構造体の代入はうまく動きません。
構造体の実体を代入する、というのがC言語にあります。 例えば以下のようなコードです。
void some_func(struct Element *elem1) {
struct Element elem2;
elem2 = *elem1;
// 以下elem2で何か作業
こうすると、elem2には、elem1のフィールドが全部コピーされますね。 ですが、前述のElementArrayのような可変長配列のトリックを使った構造体では、 この手の実体コピーでは、elementsのフィールドがコピーされません。 sizeofの範囲だけがコピーされます。
なお、今回のPostScriptの実装という点ではElementArray自身のコピーをする場所は無く、あくまでそれを保持したElementのコピーしか出番は無いはずです。なので問題ありません(ElementArrayはポインタ変数で保持するでしょう)。 知識として知っておけば十分でしょう。
また、ElementArray自身の配列を作っても、うまく++などで次の要素に行きません。 つまり、以下のコードは意図通りには動きません。
struct ElementArray *arrs
= (struct ElementArray*)malloc(sizeof(struct ElementArray)+sizeof(struct Element)*2
+sizeof(struct ElementArray)+sizeof(struct Element)*3);
// 一応これは動く
arrs[0].len = 2;
arrs[0].elements[1].etype = ELEMENT_TYPE_NUMBER;
// でも[1]はアクセス出来ないから以下のコードは駄目
arrs[1].len = 3;
arrs[1]はarrsにsizeof(struct ElementArray)だけ足したアドレスを指すので、0番目のelementsの領域を誤って指してしまう事になります。 だからこういう事は出来ません。
そもそもにこういうmallocを書く事自体無いと思うので実際に問題になるシチュエーションはほとんど無いと思いますが、 ポインタ変数の理解を深める為には良い題材と思うので少し考えてみて下さい。
選択肢3との違い
以下の2つは一見似ていますが、Elementのunionのサイズが違います。 何故だかわかるでしょうか?
選択肢2
struct ElementArray {
int len;
struct Element elements[0];
};
struct Element {
enum ElementType etype;
union {
...
struct ElementArray *exec_array;
} u;
};
選択肢3
struct Element {
enum ElementType etype;
union {
...
struct {
Element *byte_codes;
int len;
} exec_array;
} u;
};
選択肢2はunionの中にはポインタしか入っていません。 選択肢3はintとポインタの2つが入っています。
小さな違いのようですが、こうした違いをちゃんと理解するのはC言語の良い勉強になると思うので、良く違いを考えてみてください。
ポインタと可変長配列の違い
以下のコードとの違いはわかるでしょうか?
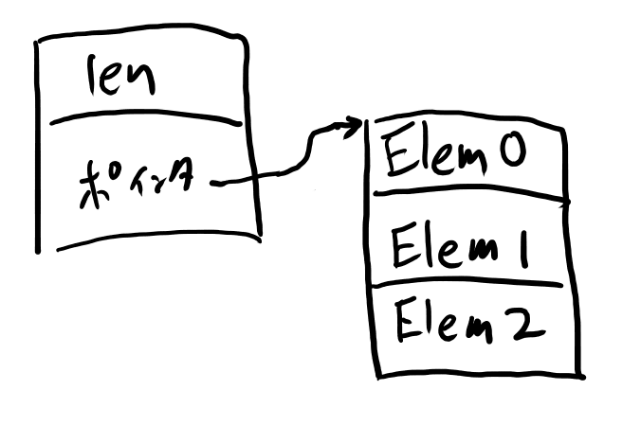
struct ElementArray2 {
int len;
struct Element *elements;
};
struct ElementArray2* arr = (struct ElementArray2*)malloc(sizeof(struct ElementArray2));
arr->elements = (struct Element*)malloc(sizeof(struct Element)*3);
この場合は以下のような図になります。
この実装だと二箇所のメモリ領域がとられて、elementsはこの2つ目のメモリ領域へのポインタになります。
一方で最初の方の実装では連続領域が取られるので、メモリ上の領域は一つです。 別にこのElementArray2の実装でも構わないのですが、
- freeなど二回しなくてはいけないので扱いが面倒
- 連続領域じゃないのでキャッシュに乗りにくいなど非効率
という違いがあります。
以上、いくつか可変長配列について細かい話をしました。 別に知らなくてもほとんどの場合問題無く使えると思いますが、 どういう連続領域が確保されてどうアクセスしているのか、 というのはC言語特有のトピックなので、説明を読んでおくくらいはしても良いと思って書きました。 別に理解出来ない所があっても気にせず進んでOKです。 何かトラブルが出た時になんとなく思い出してもらえれば、独力で原因を理解出来ることでしょう。
アラインメントがずれるよ!
当初はここの項目、ポインタの勉強も兼ねてもっと生のポインタで、int分余計にmallocして長さを先頭に埋め込めば良いと思って解説を書いていました。
ですが、書いていて64bitでアラインメントがずれる場合がある事に気づきました。(mallocしたのを4バイトだけずらしてsturct Elementのポインタにキャストしていたが、これでは8バイトアラインが保証されない!)
現在旅先で実際に検証した訳じゃないので動かない環境があるかはわからないのですが、
アラインメントのずれたアクセスをするコードは良くない、という事で解説を書き直しました。
頑張ってアラインメントを揃える話も書いてもいいかとも思ったのですが、
そこまで行くと自己満足の領域でC言語を勉強したい、という人の為にはならないな、という事でやめました。
同じ理由から、アラインメントについての解説も今回はしません。
それ以外のトピックとレベルが揃わなくなるし、学ぶ人の為にはならないと思ったので。
当面はそうした事が問題にならないお行儀の良いコードを書いて、もう少しレベルが上がってからその辺の事は勉強するのが良いでしょう。
そういえば昔同じような事をする時にアラインメント例外を踏んで、アラインするmalloc作ったなぁ、と懐かしく思いましたが今勉強している人からすればどうでもいい話ですね。
実行可能配列へのコンパイル
evalから呼ぶ、compile_exec_array()という関数を作りましょう。
これはparse_oneが”{“だった時に呼び出します。 結果としてout引数で実行可能配列のElementを返すようにしましょう。
compile_exec_arrayがやる事は、”{“か”}”が現れるまではparse_oneを呼んで、結果を配列に詰めていきます。 簡単の為、ローカル変数の配列に詰めていって、最後にElementArrayをmallocしてmemcpyしてu.byte_codesに入れますか。
その場合は、ローカル変数での配列のサイズの最大値が要りますね。 name定義の時のオペレーターの最大サイズをMAX_NAME_OP_NUMBERSとでも定義しておきましょう。 今回の用途なら256くらいでいいかな。
またはreallocを使ってElementArrayが自動的に伸びていくような物を作っても良いです。 少し発展的な話題なので、おまけとして解説だけしておきます。
おまけ:reallocを使った、自動的に伸びる配列
reallocを使って勝手にサイズが伸びていくような配列を自作する、という手があります。 その場合は、毎回少し大きめに確保しておいて、いっぱいになったらまた少し大きめに伸ばす、 という戦略になります。 少し大きめがどれくらいかは自由に決めて良いのですが、一般的にはいっぱいになるとそれまでのサイズの2倍にする、 というのが良くやられる戦略です。 reallocはそんな効率的じゃないので一つ増やすごとにやってちゃ駄目な訳です。
さて、普通なら、現在のサイズとどこまでうまっているかを持つ構造体を作る事になります。
sturct AutoArray{
int size;
int len;
struct Element *elements;
};
ですが今回はsturct ElementArrayという物がすでにあるので、これを持つのが良いでしょう。
sturct AutoArray{
int size;
struct ElementArray *var_array;
};
var_array->lenで、現在どこまで使っているかを、sizeでvar_array->elementsが現在どこまで確保されているかを表します。
以下では解説の為にあえて前者で解説しますが、実装するなら後者で実装してください。
さて、このような構造体に対して、以下のようなAPIにするのがいいでしょう。
void auto_array_init(struct AutoArray *out);
void add_element(struct AutoArray *array, struct Element *newelem);
使う側はこのadd_elementを呼んで行くだけで、最後にarray->elementsに伸びた配列が入る、という仕組みです。 実装としては以下のような感じでしょうか。
void add_element(struct AutoArray *array, struct Element *newelem) {
if(lenがsizeまで届いてしまったら) {
array->sizeを二倍に
array->elements = realloc(array->elements, array->size);
}
arrayのelementsに*newelemを入れる;
}
みたいな実装にします。 reallocは引数のポインタを伸ばすのですが、たまにその領域でそれ以上伸ばせない場合は、別のアドレスに必要なメモリを確保してそこに内容をコピーしてそちらのアドレスを返す、という事をする場合があります。 だから結果をarray->elementsに代入する必要があります。
こうしてみるとそんな難しくは無いんですが、今回の内容からすると本質的では無いのでやらなくていいかなぁ。ただローカル変数の配列に一旦取ってからmallocするのもそんな大変さは大差無い気もするので、どっちでもいいです。 もしやるなら関数名などももうちょっと真面目に考えてください。
reallocはメモリが足りない時は失敗する場合もありますが、今回はその場合の処理はしなくてOKです。
ネストした定義
さて、”}”が来れば無事終わりでreturnすれば良いのですが、問題は”{“の時です。
つまり、以下のようなネストしたケースです。
/abc { 12 34 /efg { add } def } def
PostScriptの仕様的に、これではローカル変数にならないのでこう書く意義はほとんどありません。 ただ後で出てくる制御構造と組み合わせるともう少し意味のある例が作れるので、サポートする必要はあります。
まずはネストが無い状態で実装を終えて、ネストが無い場合のテストが通る事を確認してからネストの対応に入ってください。
といっても実装は大した事ありません。compile_exec_arrayの途中で”{“にぶつかったら、compile_exec_arrayを再帰呼び出しで呼び出し、その結果をbyte_codesの配列に入れるだけです。
スタックオーバーフローにご用心?
compile_exec_arrayで、ローカル変数に例えば1024くらいのサイズの配列を取り、
さらにコードがネストしていた場合に再帰呼び出しで対応すると、
一回の再帰呼び出しごとにsizeof(Element)*1024だけC言語のスタックを消費します。
これは典型的な組み込み環境ではすぐにオーバーフローしてしまうでしょう。
今ググってみたら、Symbian OSのスタックサイズは8Kだそうです。PCなどではそこまで小さくは無いでしょうけれど、このサイズは低レベルなプログラムをしない人からすると意外な程小さい事も良くあります。(興味があれば自分の環境のスタックサイズもググってみてください)
C言語では関数呼び出しにスタックを使っています。そしてスタックのサイズは使ってるOSなりリンカなりが最初にこっそり決めています。
このサイズを超えると確保してないメモリを使ってしまったりします。
スタックオーバーフローは最近の環境ならちゃんと死んでくれると思いますが、
原始的な環境だと突然変な所に処理がワープしたり、何が起きたのか慣れてないとさっぱり分からない不思議な挙動になります。
また、mallocで確保出来なかった場合と違い、
プログラムの中で残りのスタックサイズを調べてあふれそうならエラーにする、
みたいな事も(C言語の枠組みでは)やりにくい。
うるさい事を言い始めると、そもそもに再帰呼び出しがあれば、だいたいの場合にスタックオーバーフローをさせる事が出来るので、
真面目にやる場合には再帰呼び出し自体が最初から深さの最悪値がちゃんと決まる場合以外では使うべきでは無い、
という事になるので、スタックに配列を取るかどうかは関係ない問題と言えば関係ない。
ただ256とか1024の配列をローカル変数にとって再帰呼び出しする時は、スタックオーバーフローしやすいので、
ちょっと不安になっておくのは実際にスタックオーバーフローが起きた時に混乱しなくて済むのでおすすめです。
スタックオーバーフローが起きたら、先程説明したAutoArrayみたいな方法でそもそもスタックを使わないようにしたり、グローバル変数やstatic変数で乗り切れる場合はそれらを使います(これらはスタックには取られない)。
そういうとC言語でスタックオーバーフローはいつも気をつけていないといけない気もしますが、昨今では悪意のあるユーザーからのインプットがあるようなC言語プログラムはそもそもセキュアに書くのが大変難しいので、自分の認識ではそういう事を考えないといけない時点でもうC言語の守備範囲外と思います。
実際、スタックオーバーフローをついたセキュリティホールは潰しても潰しても発見されてきた歴史があります。
いまどきのC言語プログラマとしては、スタックオーバーフローを不必要に恐れて冗長なコードを書くよりは、そういう事が起こりそうな用途では別の言語を使う、という選択が自分でちゃんと出来て、C言語に向いたシチュエーションの対象だけを短く書く、というのがC言語流だと思います。
実際の振る舞い
インタープリタとしては、中括弧に出会ったら実行可能配列を作り、それをスタックにプッシュする、という振る舞いをします。
だから、以下のコードではスタックには要素が1つだけ積まれる事になります。
{ 1 2 3 4 5 6 }
このコードで、「1 2 3 4 5 6を要素に持つ実行可能配列」が一つスタックに積まれる訳です。
以下のコードでは、スタックには2つの要素が積まれます。
{1 2 3} {4 5 6 7}
テストとしては、
{1}
{/abc}
{abc}
{1 2}
{1} {2}
{1 {2} 3}
くらいがあれば良いと思います。
実行可能配列の実行
さて、以上でスタックに実行可能配列を入れたり、それをリテラルネームにdefしたり出来るようになりましたが、 これでは実行する方法がありません。 そこで次はこの実行可能配列の実行をするコードを書きましょう。
期待する振る舞い
実行は一旦変数に入れて、その変数を評価させる事で実行します。 つまり、一旦以下のように変数に代入したあと、
/abc { 1 2 add } def
このabcを普通に置くと実行出来ます。
abc
インタープリタはこのトークンを読むと、辞書をルックアップして実行可能配列である事を知ります。 その時はこの実行可能配列を実行します。 つまり1 2 addが実行され、結果としてスタックには3が置かれる訳です。
eval_exec_arrayを作ろう
さて、これを実装する為には、exec arrayのstruct Elementを渡して実行する関数を作る事になります。 これはevalと凄く似ているけれど、parse_oneの所だけ配列の要素を順番に見ていく、という関数になります。 ただしすでにコンパイルされているので、”{“などの記号が出てくる事はありません。
これを実装する方法は幾つか考えられて、最初はparse_oneにラッパをかませてevalを共有するのが一番楽かと思ったのでそれでやってもらったのですが、思ったより大変で、そんなに楽ではありませんでした。 その時の様子に興味がある人は、parserのラッパ路線を参照ください。
今回はevalをとりあえずほとんどコピペして、eval_exec_arrayという物を作りましょう。
eval_exec_arrayは、大雑把には以下のようなコードです。
void eval_exec_array(ElementArray *elems) {
for(elemsからelemを取り出し) {
swtich(elemの種類) {
種類ごとにだいたいevalと同じ処理
}
}
}
こんな感じの処理をする事になります。
eval_exec_arrayさえ出来てしまえば、あとはプリミティブの所でC_FUNCTIONを呼んだのと似たようなコードを追加すれば良いだけなので自分で出来るでしょう。
なお実行可能配やC_FUNCTIONなどのような関数として使われるexecutable nameをPostScriptではオペレータとも呼びます。
概念的にはevalがインタープリタ、eval_exec_arrayはVMになります。 普通はトップレベルのところもexec arrayに変換してしまえばeval_exec_arrayに一本化出来るので、 両方持っている必要は無いのですが、勉強も兼ねて両方残しておきましょう。
ここで、あとの都合の為、実行がネストしたケースのテストも書いておいてください。 具体的には以下のコードです。
/ZZ {6} def
/YY {4 ZZ 5} def
/XX {1 2 YY 3} def
期待値はたぶん「1, 2, 4, 6, 5, 3」ですかね。
10 条件分岐とスタック操作とループを足そう
条件分岐、ループ、スタック操作を実装して行きましょう。これで完成です。
条件分岐
1 {1 add} {2 add} ifelse
としたら 1 addが、
0 {1 add} {2 add} ifelse
としたら 2 addが実行されるような、条件分岐を実装します。
ループ
4 {1 2} repeat
としたら、1 2 1 2 1 2 1 2したのと同じになるようなrepeatを実装します。 これは後述するwhileを使ってPostScriptで実装する事にします。
スタック操作
pop, dupなどのスタック操作も実装します。
ここまで来ると残った物はC言語として難しい要素は一つもありませんが、 せっかくここまで来たのですから、プログラム言語として一通り完成させておきましょう。
続:PostScript入門
あとに残った物はもうC言語としては難しい事はあまりありません。 そこで今回は、PostScriptの解説が主体となります。
そこでPostScriptのAPIについて最初に解説をしておきます。
スタック表記
PostScriptなどのスタック型の言語では、各プリミティブなどのオペレータの説明には、
- 呼ぶ前のスタックの状態
- 呼んだ後のスタックの状態
が大切になります。逆にこれさえ書いてあれば多くの場合そのAPIが何をするのかが想像出来ます。
そこでオペレータの説明を、以下の形式で書く事にします。
| 呼ぶ前のスタックの状態 | オペレータの名前 | 呼んだ後のスタックの状態 | 簡単な説明 |
例えばaddとかsubについて書くと以下のような形です。
| num1 num2 | add | num | 足し算 |
| num1 num2 | sub | num | 引き算 |
スタック部分の表記は、数字の場合はnumと書き、実行可能配列はprocと書く事が多いですが、厳密な決まりはありません。
Blue Bookの最後の所にこの形式でオペレータの一覧が書いてあります。 今回実装しない物も多く載っているので興味がある方は見てみてください。
PostScript Language Tutorial & Cookbook (なんかリンク切れになってしまったのでタイトルだけ)
我々が実装する物一覧
算術演算
| num1 num2 | add | num | 足し算 |
| num1 num2 | sub | num | 引き算 |
| num1 num2 | div | num | 割り算。PostScriptのidiv相当 |
| num1 num2 | mul | num | 掛け算 |
比較演算
| any1 any2 | eq | bool | イコール |
| any1 any2 | neq | bool | notイコール |
| any1 any2 | gt | bool | 大なり |
| any1 any2 | ge | bool | 大なりイコール |
| any1 any2 | lt | bool | 小なり |
| any1 any2 | le | bool | 小なりイコール |
スタック操作
| any1 | pop | - | スタック先頭の要素を捨てる |
| any1 any2 | exch | any2 any1 | スタックのトップ2つの要素を入れ替える |
| any1 | dup | any1 any1 | スタックの先頭の要素を2つに複製 |
| any_n any_(n-1) … any0 n | index | any_n any_(n-1) … any0 any_n | n番目の要素を複製してトップに置く |
| any_n any_(n-1) … any0 n j | roll | any_(j-1) any_(j-2) … any0 any_n any_(n-1) … any_j | nとjを取り除いた後のn個をjだけ回転する。なおjがnより大きい時はnの剰余で回転する。 |
rollは少し分かりにくいので補足しておきます。
例えば以下のようなコードがあるとします。
1 2 3 4 5 6 7 4 3 roll
この時、スタックトップの3と4をまず取り除いて、 残り1 2 3 4 5 6 7のうち、要素4つを3だけ回転します。つまり、4 5 6 7を3だけ回転するので5 6 7 4になって、
1 2 3 5 6 7 4
となります。 回転は一つずつやると以下の順番で変わっていきます。
- 7 4 5 6
- 6 7 4 5
- 5 6 7 4
制御オペレータ
| proc1 | exec | - | スタック先頭の実行可能配列を実行する |
| bool1 proc1 | if | - | bool1がtrueならproc1を実行。 |
| bool1 proc1 proc2 | ifelse | - | bool1がtrueならproc1を、そうでなければproc2を実行 |
| n proc1 | repeat | - | n回proc1を実行 |
| proc1 proc2 | while | - | proc1を実行し、スタックトップがtrueだったらproc2を実行、をスタックトップがfalseになるまで繰り返す。PostScriptには無い独自拡張。 |
PostScriptにおける条件分岐
PostScriptにはbool型があります。trueとfalseです。ですが、このシリーズでは手抜きとして、trueを1、falseを0で代用したいと思います。実装に難しい事は無い割に、コードが膨れがちだからです。
他の言語では制御構造は特殊な文法を持つのが普通ですが、 PostScriptにおいては実行可能配列の仕組みのおかげでほとんど条件分岐に特有な構文はありません。
ifというプリミティブは、スタック上に「条件、実行可能配列」の順番に入っている前提で、 条件がtrueなら実行可能配列を実行し、そうでなければ何も実行しません(どちらもスタックからはpopされる)。
例えば以下のPostScript文は、
hoge {1 add} if
他の言語で例えると以下のような意味になります。
if(hoge){
1 add
}
ブロックが実行可能配列という抽象だけで実現されているのは美しいですね。
ifelseというのもあり、これはスタックが「条件、ifブロック、elseブロック」という順番に入っているという前提で、 条件がtrueだったらifブロックを、条件がfalseだったらelseブロックを実行します。
PostScriptにおける比較演算子
PostScriptには、大なり、小なり、大なりイコール、小なりイコール、イコール、ノットイコールなどがあります。 それぞれ、gt,lt, ge, le, eq, neqです。
これらはスタックに2つ数字が入っている前提で、2つの数字をpopして比較して結果をスタックにプッシュします。
例えば
1 3 lt
なら結果のスタックにはtrueが入ります。
PostScriptにおけるスタック操作
indexだけ少し分かりにくいかも。n番目をコピーですね。スタックトップに来るのがポイント。 例えば
a b c d e 2 index
とすると、
a b c d e c
となります。
ここは良く間違える人がいるのでもう一つ例を足しておきます。 以下のようにすると、
a b c d e 1 index
次のようになるのが正解です。
a b c d e d
0番目から数えて、eが0番目、dが1番目、cが2番目です。
PostScriptにおけるループ(とその拡張)
PostScriptではrepeat, for, loopの3つのループとarrayに対するforeach相当の物があります。 今回はこのうち、repeatだけ実装し、さらにPostScriptには含まれていませんがwhileを実装しようと思います。 repeatはあとでwhileを使って実装するのでここではwhileだけ実装してください。
repeatはスタックが「カウンタ、実行可能配列」という状態で呼ばれ、 実行可能配列をカウンタ回数実行します。
例えば
3 {1 2} repeat
なら、スタックは「1, 2, 1, 2, 1, 2」になります。
whileはPostScriptにはありませんが、実行可能配列が2つスタックにある前提で呼ばれます。 それぞれ、condブロック、bodyブロックと呼びましょう。
condブロックを評価し、スタックのトップが1ならbodyブロックを実行してまたcondブロックを実行して、、、と続けます。 condブロックを評価した結果スタックのトップが0ならそこで実行を終えます。 実装を疑似コードで書くと、
body = pop();
cond = pop();
eval_exec_array(cond);
int val = pop();
while(val) {
eval_exec_array(body);
eval_exec_array(cond);
val = pop();
}
という感じの挙動とします。 これで例えば階乗(factorialと呼ぶ)は以下のように実装出来ます。(なおパーセントはそれ以降をコメントとする行コメントです)。
/factorial {
dup
%スタックをいつも 「途中経過、j」でwhileが評価されるとし、
%jを途中経過に掛けてjを1減らす、
{dup 1 gt}
{
1 sub
exch
1 index
mul
exch
} while
pop
} def
そのほか細々としたこと
- 改行を空白として扱う
- コメントの実装(パーセントから行末までを無視、空白と嘘ついて返してもいいです)
- cl_getcでファイルをセットしたらそちらから読むようにして、mainの引数で渡されたファイルを読むようにする(fopen-fcloseはmain側でやる)
これでインタープリタが出来ました。
11 PostScriptでいろいろ書いてみよう
PostScriptは、この言語でプログラムをする事自体がプログラム言語のコールスタックという物の理解を深めてくれます。 せっかくインタープリタを作ったのだから、少しいろいろ実装してみましょう。
- factorial.ps 上記のfactorialを実装し、最後に 10 factorial を実行(これだけサンプルとしてsources/ps/factorial.psに実装しておきました。以下はこれを真似て実装してみて下さい)
- sum_k.psでは数字を引数に1から指定された数までの和を求めるsum_kを実装して 10 sum_k を実行
- repeat.psでrepeatをwhileで実装する。カウンタはrepeat_contという変数に入れて実装。最後に 3 {1 2} repeat を実行(repeatのネストは動かなくていいです)
- k^2のシグマを求めるsum_k2を求めて検算出来そうなくらいの計算をさせる。
- フィボナッチ数列の第n項を求める。a_0 = 0、a_1 = 1で、a_(n+2) = a_n + a_(n+1) だそうです。 10 fibo とかやると第10項の答えが出るようなfiboを実装。
- Fizz Buzz。modの実装が要るのでやらなくてもいいです。やる人はmodをaddやdivなどと同様にC言語の%演算子を用いてプリミティブに追加すればいいでしょう。数字を順番にカウントしていくが、以下の場合だけ数字では無くて文字を出力。3と5で割れたら /FizzBuzz、それ以外で5で割れたら/Buzz、それ以外で3で割れたら/Fizz。今回は数字をスタックに積んでいって、FizzとかBuzzはリテラルネームをpushする事にしましょう。 15 FizzBuzz とやったら数字やリテラルネームを15までスタックに積んでいく事とします。15 FizzBuzzするとスタックの中は以下のようになるらしいです。
1 2 /Fizz 4 /Buzz /Fizz 7 8 /Fizz /Buzz 11 /Fizz 13 14 /FizzBuzz
- 与えられた数までに含まれる素数を求める。100 primeseries とすることで2から100までに存在する素数を求めるようなprimeseriesを実装。まず、ある数が素数かどうかを判定するisprimeを実装し、primeseriesで与えられた数までループする中でisprimeを呼んで素数と判定されたものだけスタックに積んでいきましょう。ある数Nが素数かどうかを判定するにはNの平方根以下までの数で割り切れるかを調べるのがよく用いられる方法ですが、今回は小数を扱っていないのでN/2以下までの数で調べるというのでよいでしょう。
あと、他人のコードも動かしてみましょう。 自分のコードは自分の処理系の癖を知ってて無意識に手加減してしまう事があるので。
これまでにこのコースをやった方の書いたソースへのリンクを貼っておきます。
- github:Oikawa124/c-lesson/PostScriptコード
- この
sum_k2はバグがあるかもしれません。
- この
- github:harukawa/c-lesson/PostScriptコード
- この
sum_kはバグがあるかも?(1 indexとすべき所が 2 indexになっているかも?)
- この
- github:yoheikikuta/c-lesson/PostScriptコード
PostScriptに見る、スタックと関数の関係
PostScriptのスタックを使ったネーム定義をある程度使いこなすと、他の言語における関数の引数と戻り値が、このスタックで表現されている事が分かってくると思います。
これはPostScriptを勉強するメリットの一つと思う所です。C言語なども内部では原理的にはスタックを介して引数をやりとりしますが、これはC言語からは見えにくいのでいまいち理解が難しい所です。
PostScriptならこれを直接扱うので、関数やその呼び出しという概念をより深く理解出来ます。
他の言語における関数呼び出しの引数は、PostScriptにおいてはexecutable nameを呼び出す前にスタックに積んだ物になります。
戻り値はexecutable nameを呼び終わった後のスタックに置かれる事になります。
この仕組みの為、PostScriptでは自然に可変長引数や多値の戻り値も自然にサポートされます。
C言語のスタックフレームは言語の上には出てこない所なのだけど、C言語はプログラマにスタックフレームを意識してコードを書く事を要求する言語です。
言語の上に出てこないので本を読んでも理解が難しい所で、それはこのシリーズの第二回でアセンブリをやる事でより深く見ていく事になりますが、PostScriptを触る事は一つその理解を助ける良い補助輪のような役割にもなっていると思います。
第二回でアセンブリからC言語の関数を呼ぶ時に、PostScriptでの経験が役に立つのを見る事になるでしょう。
11の終わりに
これくらい書くと、だいぶPostScriptの書き方にも慣れてくるんじゃないでしょうか。 慣れてくれば、ここまで実装した範囲でも相当いろいろな事が出来る事はわかると思います。 実際インタープリタとして必要なコアの要素は、ここまでの実装でだいたい含まれていると思います。
PostScriptには存在するけれど我らの処理系には無い物もいろいろとありますが、 それらは実装に難しい所はありませんし、C言語の勉強という本来の用途からは外れてしまうのでこの位にしておきたいと思います。
当初はここまでで第一回は終わりにしようかと思っていたのですが、 一人目にもうちょっと先までやってもらった所、思いのほかおもしろいコードになったので、皆にもやってもらおう、という気になり続きも用意する事にしました。
余力があったらチャレンジしてみて下さい。
テストの拡充
次の12から先はオプショナルですが、かなり手強くなるので、少しテストを増やしておきましょう。
まず、exec、while, repeat, ifelseは実行可能配列内とトップレベルの2つのテストを必ず用意しましょう。 例えば
3 {123} repeat
と
{3 {123} repeat} exec
の2つを用意する、という事です。
また、while, repeat, ifelseは、その次に進んでるかを試す為、その次の命令が実行されるかもテストしましょう。 例えば以下のようなコードの4のような奴です。
1 {2} {3} ifelse 4
実行可能配列の中に必要な物が揃ってないテストも書きましょう。
/a { {345} ifelse} def 1 {123} a
などです。なお最初のカッコの後に空白を開けてるのはjekyllのバグをついてしまうからで、皆さんは空白無しで構いません。
こういう時にif側とelse側のテストを全部完璧に揃えてやろう、と書くとテストの数が膨れ上がってしまい、途中で挫折してしまいがちです。まずはテストしたい項目に対して最低一つのケーステストを一通り揃える、 というのが大切です。この場合は実行可能配列内に必要な物が揃ってないケースをテストいしたいのであって、ifelseの両方で動くかをテストしたい訳では無いので、まずは一つ動くかをテストして他のテストを揃えていくのが大切です。
まず幅優先で最低限一通りテストを揃え、その後気になる所は追加していきます。
以下のテストも足しておきましょう。(最初にやった人が結構苦戦してたので)
/f { {1 3 add} exec 3} def f
以下のifのネストでifの後にもなにかあるケースは順番が壊れる場合があるので足しておく。(thanks for @maiyama18)
/b { 1 { 3 } if 2 } def
/a { b 1 } def
a
また、複雑な例も一つくらいは足しておきましょう。factorialもUnitTestの形で追加しておけば良いでしょう。
なおこのコースを最後まで終えた後に、ここに追加した方が良いという物があったらフィードバック募集します。
12 継続を使ってexecを再実装しよう
当初考えていた第一回の内容は11までで終わりでした。 ここまでで結構大変だった、と感じた人はここまでで終わりにして第二回に進んでもOKです。
ここまでの所には一箇所、言語処理系としてはちゃんと理解すべき所をごまかしている部分があります。 それは「実行可能ネームの実行にC言語の関数呼び出しのスタックを使用している」という事です。
それ自体は必ずしも悪いとは言えず、むしろPostScriptの処理系としては正しいと思いますが、 勉強という観点では理解してないでもコードが動いてしまう、という問題があります。
そこでここでは、これまでC言語のスタックを用いて実装されていたeval_exec_arrayを、自前のスタックに変えて実装する、という事をやってみます。
evalとeval_exec_arrayについて
さて、これまでは、evalとeval_exec_arrayはほとんど同じ処理をしていたと思いますが、 ここからはこの2つは大きく異なる振る舞いをするようになります。 すると、いくつかのCのプリミティブは両方で動くように実装出来なくなります。 テストは必ずevalで動くテストとeval_exec_arrayで動く物の2つを書いてください。
以下ではeval_exec_arrayの話をしていきますが、その時はいつもevalの方はどうだろう?という事も考えてみてください。
なお、今回はevalからeval_exec_arrayを一回呼ぶのは有りとします(whileやrepeatで使うはず)。
eval_exec_arrayを呼んでいるCプリミティブをコメントアウトする
これからeval_exec_arrayを大きく変更します。 そこで一旦、eval_exec_arrayを呼び出しているプリミティブを登録している所を、コメントアウトしましょう。
また、それに依存しているUnitTestもコメントアウトしておきます。
たぶんこの時点では、exec, ifelse, repeat, whileあたりが内部でeval_exec_arrayを呼び出していると思います。これらを一旦コメントアウトして、一つずつ実装しつつ追加していきます。
ネストした呼び出しの実行
さて、以下のようなコードを考えてみましょう。
/ZZ {6} def
/YY {4 ZZ 5} def
/XX {1 2 YY 3} def
このXXを実行すると、スタックには何が入るでしょうか? 答えは「1, 2, 4, 6, 5, 3」だと思います。
さて、何も考えずにeval_exec_arrayの中でeval_exec_arrayを再帰呼び出ししていると、 特に何も考えなくても上記のコードは動いてしまうと思います。 また、eval_exec_arrayの中で呼んでいるcfuncからもeval_exec_arrayが呼ばれるケースがあると思います。 while, repeat, ifelse, execなどがそうなっているでしょうか。
このネストしたeval_exec_arrayで何が起きているのか?という事を良く理解する為に、 eval_exec_arrayをネスト呼び出しせずに同じ機能を実装してみたいと思います。
そこでまず、上記のコードを実行する時に現在は何が起きているのかを考えてみます。 これはC言語のスタックフレームという物を理解する為の良い題材となります。
PostScriptの世界で何が起きているか
C言語のスタックフレームを勉強する為に、まずはPostScriptの世界で上記のコードでは何が起きているのかを考えてみましょう。
PostScriptの世界でXXを実行します。するとまず1をスタックにプッシュし、次に2をスタックにプッシュする。 ここまでは良いのですが、次にYYを実行しろ、と言われます。
YYはdict_getすると実行可能配列のようなのでこれを次に実行していく訳ですが、 このYYの実行が終わった後もまだXXにはやる事が残っています。そう、3をプッシュする事です。これをYYの実行が終わった後にやらないといけません。
つまり、YYを実行する時には、それが終わった後にXXの続きをどこから再開するかを覚えておいて、YYの実行が終わった後にXXの続きの実行を再開する必要があります。 下の図で言う、赤の矢印がどこに戻るかを覚えておいて戻ってくる、という事ですね。
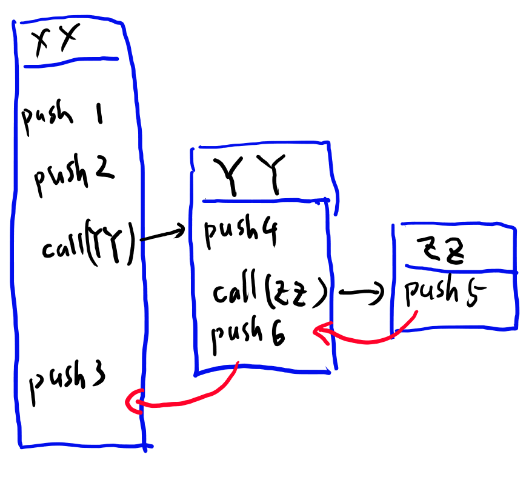
ただYYの中でもさらにZZで同じ事が発生するので、 ネストの数だけ現在実行中の場所をとっておく仕組みが必要です。つまりスタックが必要になります。
C言語のスタックフレーム
さて、これらの情報はC言語ではどこで処理されているでしょうか? YYの実行をしている時に、終わったらどこのXXから実行するか、というのは、 XXを実行しているeval_exec_arrayのfor文のインデックスが覚えています。 ここではこれをint iという名前だとしましょう。
XXのeval_exec_arrayの中からYYのeval_exec_arrayを呼ぶと、
- XXのeval_exec_arrayのi
- XXのeval_exec_arrayが現在どこまで実行されているか
の2つの情報がどこかに保存された上で、YYのeval_exec_arrayが呼ばれます。
一般にC言語の関数を一回実行すると
- 渡された引数
- ローカル変数
- 終わった後の戻り先
の3つが保存されます。
この関数の中から別の関数を呼ぶと、さらにこれら3つが保存されます。 これはスタック構造で保存されていて、いつも最後の関数の実行が終わったら、 一つ前の関数の状態が復帰出来るようになっています。
例えば以下のような疑似コードを考えましょう。
void eval() {
...
eval_exec_array(XXの実行可能配列);
}
void eval_exec_array(execarr) {
...
if(YYを実行する必要があったら)(
// 再帰呼び出し!
eval_exec_array(YY);
}
}
先程のPostScriptを実行すると、だいたいこういう事が起こると思います。
これは、以下のようなスタックとなります。
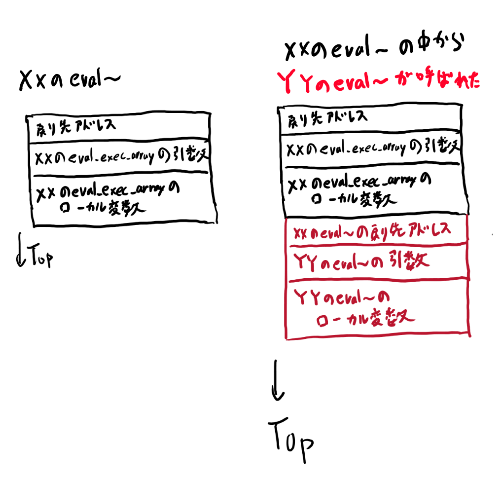
普段関数が戻る先をどう保存しているか、なんて気にしないかもしれませんが、 だいたいプログラムはジャンプでできているので、戻る、という場合は戻る先のアドレスがどこかには保存されているものなのです。 そしてC言語ではこのスタックがどうなっているのか、という事は、まぁまぁ意識してプログラムするプログラミング言語です。
これらのスタック構造によって保存される関数の情報をスタックフレームと呼びます。
以下のサイトの前半のC言語のところなども参考にしてみてください。
さて、では次にこれを、C言語の再帰呼び出しを使わずに実装してみましょう。
継続と継続スタック
プログラムにおいて、現在どこを実行しているか、という情報を「継続」と言います。 英語では「Continuation」と呼ばれています。
継続はSchemeなどの一部の言語には言語仕様として存在しますが、普通はインタプリタなどの内部実装に隠れているものです。 Cのスタックフレームでやっている事と同じ事を自前で実装する、というのは、 この継続を実装する事に相当します。 以下ではこれをやっていきましょう。
XXを実行していったら、YYを実行する必要が出てきました。 ただ、YYが終わった後に、XXの現在の位置に戻ってきて実行を再開したい(厳密には現在の位置の一つ次)。
「現在の位置」というのは、
- 現在どの実行可能配列の
- 何番目のElementを実行しているか
という事です。
このうち「何番目か」を表す物を、第二回のアセンブリの内容と近づける為、以下ではpcと呼びます。プログラムカウンタの略です。 実行可能配列はElementArray型とすると、以下のような構造体で、eval_exec_arrayが現在実行している場所が表せます。
struct Continuation {
struct ElementArray* exec_array;
int pc;
};
さて、YYの実行を開始する前にXXの現在位置をContinuation構造体に入れておけば、 終わった後にこの構造体の位置から実行が再開出来ます。
擬似コードで書くと以下みたいなコードです。
static struct Continuation *prev = NULL;
void eval_exec_array(XX) {
int i;
struct ElementArray *cur = XX;
for(curをの要素を一つずつ取っていく、要素はelem, インデックスはiとする) {
if(elemがYYだったら) {
prev = Continuation(XX, i);
cur = YY;
i = 0;
continue; // for文をやり直し
} else {
通常の処理
}
}
prevが残っていたら、curとiをprevの値にもどしてfor文の中に戻る
}
疑似コード度合いがひどくて読みにくいですね(^^;
なかなか複雑ですが、YYにあたったらfor文にYYを実行させ、その実行が終わったらXXの続きを再開する訳です。
ですがこれでは、ZZを実行する時に困ります。 prevにYYの場所を覚えてさせてしまうと、XXの戻り場所が上書きされて消えていまいます。
だからこのprevはスタック構造になって複数保存出来る必要がある訳です。
PostScriptのスタックと区別する為に、これをcontinuationのスタック、略してco_stackと呼ぶ事にしましょう。co_push、co_popなどで対応する命令を書きます。 (普通はこのスタックとpcを合わせた物を継続と呼びますが、今回はコードの都合で継続とそのスタックと呼ぶ事にします)
イメージ的にはprevを、以下みたいなコードにする訳です。
static struct Continuation co_stack[1024];
static int co_stack_pos = 0;
これらはcontinuation.cというファイルに実装してください。
すると、eval_exec_arrayはだいたいこんな疑似コードで書けます。
void eval_exec_array(XX) {
co_push(XXとpc=0);
while(co_stackに要素が入ってたら) {
struct Continuation* cont = co_pop();
while(contの実行可能配列から続きのelemが取れる間){
switch(elemの種類が) {
case 実行可能配列以外なら:
普通の処理をする;
case 実行可能配列なら:
1. 現在の位置と実行可能配列で継続をco_stackにふたたびco_push
2. elemのexec_arrayとpc=0の新しいcontをco_stackにco_push
3. 1つ目のwhileから抜ける // 注:1
}
}
}
}
つまりeval_exec_arrayはいつもスタックトップの継続から続きを実行していき、 その実行可能配列の実行が終わったらスタックの次の継続の実行を再開していきます。 これはC言語を始めとした多くのプログラミング言語の関数呼び出しと同じ仕組みを手動で実装してる事になります。
今回の疑似コードはこれまでよりも擬似度合いが高くて、そのままでは実装出来ない形になっています。 良く意味を理解した上で実装は疑似コードと大きく変えた、もっと自然な形で実装するのが理想です。
注1は、単にbreakとするとswtichから抜けるだけでwhileからは抜けません。 このまま実装するならgotoになりますが、関数化したりswitchでなくしたりなどでgotoを使わなくするのは可能なはずですので、考えてみてください。
なお、これを実装すると、ifelseなどがネストしている場合に動かないケースが出てきます。
C関数から実行可能配列を実行したい場合
これで実行可能配列がネストしているケースの実行で、eval_exec_arrayの実行がネストしなくなりました。 ですが、現状cfuncなどの中から、ifelseやrepeatなどの制御構造でeval_exec_arrayを呼び出しているはずです。
これは、eval_exec_arrayー>cfuncー>eval_exec_arrayと間に一つ挟まっただけで、やはりネストして実行されています。
これらの呼び出しもネスト無しで実行したい。 そこで一番簡単なケースであるexecを考えてみたいと思います。
execの実装をする
ここまではexecは、popした実行可能配列をeval_exec_arrayに渡していたと思います。 ですが実装を変えた事で、eval_exec_arrayを呼び出すと内側のeval_exec_arrayで全co_stackの中身が処理されて、その後外側のeval_exec_arrayに戻った時に変な状態になってしまいます。
そこでそもそもに、Cのprimitiveからeval_exec_arrayを呼ぶのは禁止にしたい。 これ無しでexecを実装する方法を考えてみましょう。
まず、eval_exec_arrayの中で実行可能配列の実行のコードはすでにある訳です。 execの時もこれと同じ事をさせたい。だがexecはeval_exec_arrayの関数とは別の関数なので、 eval_exec_arrayのローカル変数をいじったりは出来ません。
このeval_exec_arrayの中での細かい変更をしたい場合、関数で分かれているのはあまりメリットになっていない事に気づくと思います。 そこで、まずexecに関しては、eval_exec_arrayの内部でstreqで判断して処理してしまう事にしましょう。 (あとでexecは専用のオペレーションに変更します)
これでeval_exec_arrayの中からexec_op()が呼ばれる事は無くなったので、このregisterを戻す事が出来るはずです。
とりあえずifとifelseも同じようにeval_exec_array内にstreqをして実装してしまう事にします。(後で直します)
なお、この結果としてevalとeval_exec_arrayで同じような分岐が発生してしまうと思います。 これはトップレベルはインタープリタとして動かして実行可能配列はVMとして動かす、というハイブリッドな構成のせいですので、そういう物と思って進めて下さい。
13 jmpでifelseを再実装する
以降では ifelse の実装を解説をしていきますが、同様にして if の実装も可能なので、ifelse の実装の流れを経験した後に if もやってみてください。
さて、ifelse自体はこれまでと同じような方法でも実装出来ます。 詳細は説明しませんが、ようするに関数ポインタから戻った後にeval_exec_array側でexec相当の処理をさせる事さえ出来れば良く、これはグローバル変数などを使えば特に難しい事はありません。
ですが、次に実装するループはこれらよりも少し難しく、ローカル変数とjmpや条件付きジャンプが必要となります。 ループを突然実装すると大変なので、簡単なifelseを、次にも使えるjmpで再実装することで、次のループ実装の足がかりにしましょう。
jmpとjmp_not_ifを実装する
まず、以下の2つの命令を実装しましょう。
| num1 | jmp | - | num1だけ先の実行可能配列の要素の実行に飛ぶ(マイナスだと戻る) |
| num1 num2 | jmp_not_if | - | num1が0だったらnum2だけ先の実行可能配列の要素の実行に飛ぶ(マイナスだと戻る) |
これらのジャンプは、同じ実行可能配列内しか指さない事にします。 実行可能配列の「最後+1」をさしてる場合は、この実行を抜けるという意味になるとします。
これらのジャンプも、eval_exec_arrayの中で実行する方が良いでしょう。 cfuncとして登録するのでは無く、この2つはstreqして特別処理としてeval_exec_arrayの中で処理するのが良いでしょう。
普通はjmpifも実装するのですが、今回のケースでは使いみちが無かったのでnot_ifだけ実装する、という変則的な事になっています。(別にjmpifも実装したければしても構いません)。
余談ですがjmp_not_ifはARMのアセンブリではbneに、Javaバイトコードではifneという名前で似た物があります。
ifelseをjmpとjmp_not_ifで実装する
さて、jmpとjmp_not_ifがあれば、ifelseは実装出来そうです。 例えば以下のようなコードは
cond {123} {456} ifelse
ジャンプのアドレスを見やすいように縦に書くと、以下のようなコードに出来そうです。
cond
5
jmp_not_if
{123}
exec
3
jmp
{456}
exec
このように、例えばjmpで3だけ飛ばしたい時は
3
jmp
とjmpの引数をスタックに積むんですね。この2つで関数呼び出しのようになっている訳です。うーん、PostScript。
このように、いくつかの命令は、より原始的なジャンプやexecに置き換え出来ます。 実行可能配列を作る時に、このような変換をすれば、eval_exec_arrayの処理を減らす事が出来ます。
この変換はどこでやるのが良いでしょうか? コンパイル時のcompile_exec_arrayと、実行時のeval_exec_array内が考えられます。
実行時は実行の都度コードが生成されてしまうという問題がありますが、 完全に上記の実行可能配列を吐く事が出来るので簡単だというメリットがあります。 というのはcondも{123}も{456}もあるはずだからです。
まずは実行時コード生成で簡単に実装する方法から初めて、その後コンパイル時コード生成になおしてみましょう。
ifelseを実行時コード生成で実行する
実行時にコード生成すれば、eval_exec_arrayでifelseだったら上記の実行可能配列を作ってexecすれば良い、という事になります。
あとで変える為の一時的な実験なので、eval_exec_arrayの中でifelseだった時の処理を足してしまうのが手早いでしょう。
それなりに作業はあると思いますが、難しい事は無いと思います。
ifelseを静的コード生成で実行する
さて、コードの生成を実行時にするのは遅いですし、実行の都度mallocされてどんどんメモリを消費してしまうので無駄です。 本来はcompile_exec_arrayの段階でもなんとか出来るならした方が良いです。
ですが、コンパイル時にこれをやろうとすると、condや実行すべき実行可能配列がまだ存在しない可能性がある。 例えば以下みたいなコードがありえます。
/hoge { { 456 } ifelse } def
1 {123} hoge
この時、hoge用に実行可能配列を作る時には、まだ1や{123}は分かりません。
ですが、コンパイル時でも、工夫すればやりようはありそうです。 ようするに実行時に前述のバイトコードに相当するようなコードになっていればいいので、例えば
3
2
roll % {123} {456} condに
5
jmp_not_if
pop % condがtrue。この時点ではスタックは{123} {456}。123の方を実行したい
exec
4
jmp
exch % condがfalse。この時点ではスタックは{123} {456}。456の方を実行したい
pop
exec
となります。
execの結果スタックの状態が変えられてしまう可能性があるので、execの前にスタックの操作が終わっている必要があります。
複雑なコードではありますが、これをハードコードで吐けば良いので、実装自体は簡単です。
という事で、先程の動的コード生成のコードは削除して、compile_exec_arrayでifelseを変換してしまうことにしましょう。 こうすれば、eval_exec_arrayの方にはifelseが来る事は無くなります。
まずはコンパイラの中でifelseの静的コード生成をしてみる
例えば変更前がだいたいこんな感じのコードだったとします。
void compile_exec_array(...) {
struct Element array[MAX_NAME_OP_NUMBERS];
// parse_oneして種類によってarrayにいろいろ詰める
if(...) {
...
} else if(EXECUTABLE_NAMEだったら) {
arrayにそのEXECUTABLE_NAMEを詰める
}
// arrayに入ってる要素分mallocして中をコピーしてreturn
このparse_oneを呼んでいろいろ詰める所で、 EXECUTABLE_NAMEだった時の処理を変更します。
まずは、streqを使って、ifelseだった時だけ特別にその処理をやる事にしましょう。
void compile_exec_array(...) {
struct Element array[MAX_NAME_OP_NUMBERS];
...
} else if(EXECUTABLE_NAMEだったら) {
if("ifelse"だったら) {
arrayに以下のコードを詰める
3 2 roll 5 jmp_not_if ...
} else {
arrayにそのEXECUTABLE_NAMEを詰める
}
}
...
}
さて、これで無事動くはずですが、こんな風にオペレータを足す都度compile_exec_arrayが汚くなっていくのは辛いですね。
そこで関数に抜き出したいと思います。
ifelse_compile関数を作る
このコード生成を担当する関数はifelse_compileという名前にする事にします。 別に他の名前でもいいんですが説明の為何か名前が無いとややこしいので、この文書内ではifelse_compileと呼ぶ事にします。
さて、この関数にはどういう引数が必要でしょうか?
ifelse_compileのシグニチャを考える
ifelse_compileは心を無にして関数にすると、だいたい
- array
- arrayの現在位置
の2つが必要で、さらに最後に
- 変更したarrayの現在位置
を返す必要があります。
何も考えなければこうですね。
void ifelse_compile(struct Element *array, int *pos);
posを入力と出力で使うのはちょっとひどいから結果はreturnで返す、というのなら、以下みたいになります。
int ifelse_compile(struct Element *array, int pos);
これでもいいんですが、さすがにちょっとcompile_exec_arrayの実装の詳細をifelse_compileが知りすぎていて良く無いですね。
本質的には命令を順番に追加していければいいだけのはずです。 ですから、気分的には以下みたいなAPIが欲しい
void emit_elem(struct Elem *elem);
これでifelse_compileからはrollとかをへろへろ出していく、という事で良いはず。
void ifelse_compile() {
emit_elem(3);
emit_elem(2);
emit_elem("roll");
...
}
こんな感じにしたい。ただこれではarrayをうまい事渡せないので、それを持った構造体を最初に渡すくらいはしてやる、という事でどうでしょう。 これをEmitterという名前としましょう。
気分的にはこんな感じ。
struct Emitter {
Element *elems;
int pos;
};
void emit_elem(struct Emitter *emitter, struct Elem *elem) {
// emitter->elemsにelemを追加する
}
ただこれだとコードが読みにくくなりそうなのでちょっと変えた方が良いかも。
これでEmitterのポインタがあればさっきと似た感じのコードに出来そう?
void ifelse_compile(struct Emitter *emitter) {
emit_elem(emitter, 3);
emit_elem(emitter, 2);
emit_elem(emitter, "roll");
...
}
数字と文字列が混ざってるのでこのままは実装出来ないはずですが、 似た感じのコードになるようにemitterのAPIを考えてみてください。
Emitterは、例えば以下みたいに作ります。
void compile_exec_array(...) {
...
struct Element array[MAX_NAME_OP_NUMBERS];
// これまでのコード
struct Emitter emitter;
emitter.elems = array;
emitter.pos = i;
これでifelseのコンパイル処理を関数にくくりだす事が出来そうです。
辞書を2つ作る
さて、ifelse_compileという関数に出来たら、次はstreqしている所を辞書のlookupに変えたい。 ちょうどevalでプリミティブにやったみたいに。
そうするとevalの時の辞書とは別にもうひとつ辞書が必要になりそうです。
えいっとコピペして全部の関数名やグローバル変数の名前の最後に2とかつけてもいいんですが、 そりゃあんまりだ、と思うなら、辞書の配列を引数で渡せるように変更するのがいいでしょう。
現在、例えば以下みたいなコードになっているとすると、
struct Element* dict[TABLE_SIZE];
int dict_get(char *key, struct Element *out_elem);
以下のようにしたらいいんじゃないか。
struct Element* eval_dict[TABLE_SIZE];
struct Element* compile_dict[TABLE_SIZE];
static int dict_get_common(struct Element* table, char *key, struct Element *out_elem);
int dict_get(char *key, struct Element *out_elem) {
return dict_get_common(eval_dict, key, out_elem);
}
int compile_dict_get(char *key, struct Element *out_elem) {
return dict_get_common(compile_dict, key, out_elem);
}
これでこれまでのコードはそんな変更しなくてもいい気がします。 ただ、compile_dictの方はElementのu.cfuncの型が違うよ、とか言われるでしょうね。 unionでもうひとつ足す必要があるでしょう。
streqを無くす
さて、ここまでで以下のようなコードがeval_exec_arrayに入ったと思います(変数名などは多少違うかもしれませんが)。
void eval_exec_array(struct ...) {
if(streq("exec", elem.u.word)) {
// execの処理
} else if(streq("jmp", elem.u.word)) {
// jmpの処理
} else if(streq("jmp_not_if", elem.u.word)) {
// jmp_not_ifの処理
}
}
streqというのは、文字を一文字ずつ比較していくので比較的重い処理です。 それがこの実装では最悪4回も実行されてしまいます。 実行可能ネーム一つ実行するのに毎回4回もstreqを呼ぶのはあまり良くない。
もともと辞書は、だいたいのケースではstreqは一回で済みます。これも遅いですが、4回よりはだいぶ少ない。
特に”jmp”や”jmp_not_if”などは我らが勝手に入れる物です。 自分で入れた物をわざわざstreqで比較するのは無駄です。 最初から数値のIDなら、==一発で比較出来るはずです。
そこでコンパイル時に、これらは数字のIDに置き換えましょう。 Elementの種類としてはC_PRIMITIVEとは別のPRIMITIVEというのを作り、u.valueに各命令を表すenumを入れます。 enumはOP_で始める事にしましょう。 OP_EXEC, OP_JMP, OP_JMP_NOT_IFなど。
14. ローカル変数とループを実装しよう
さて、最後です。ループを実装します。 まずはwhileの実装を考えていき、どうしてローカル変数が必要になるのかを理解した後でこれを実現していきます。
whileを実装する
whileを実装します。 動的コード生成ならそんなに難しくないのですが、静的にやろうとするとローカル変数が必要になりそうです。 そんなに難しい訳では無いので、ここまで来たらやってしまいますか。
whileを動的コード生成で実装する
動的なコード生成なら、ここまでやってきた人なら、別段説明無しで実装出来てしまうでしょう。
例えば以下のようなコード、
{dup 5 gt} {hoge} while
というコードは、(ジャンプのアドレスを見やすくする為縦に並べて書くと)以下のように書けばいいでしょうか。
{dup 5 gt}
exec
5
jmp_not_if
{hoge}
exec
-7
jmp
実行時であれば2つの実行可能配列がスタックに入っているのでこのコードを生成する事は出来るでしょう。 まずはテストを通すべく、ひとまずこの方針で実装してみてください。 今回もあとですぐ消すので、eval_exec_array内でこそっと実行してみてください。
基本的に、上記の0行目と4行目以外は毎回同じで、 コード上は0行目と4行目は実行可能配列のポインタに過ぎないので、 このコード生成はここまで来た人なら余裕でしょう。
それでは次に静的コード生成を考えてみます。
静的コード生成での難しさを考える
さて、今回も少し頑張れば静的コード生成でも実装出来そうな気がします。 例えば、bodyの部分がスタックをいじらないのであれば、dupとexchとexecとjmpなどで実装出来そうです。
ですが、ループではスタックに数字をプッシュしたい事も多い。 こうするとbodyをexecした後のスタックの状態はwhileには分からないので、condがどこに行ったのかわからなくなってしまいます。
そこで、bodyを実行する前にcondの実行可能配列をどこかに退避しておく必要が出てきます。 これはローカル変数の出番です。
ローカル変数を実装しよう
ではローカル変数を実装していきましょう。まずローカル変数とは何か、どういうAPIか、という事から考えていきたいと思います。
ローカル変数とは何か
ローカル変数とは、現在実行している実行可能配列にローカルな変数、という事になります。 今の実行可能配列の実行が終わると無くなります。 そして別の実行可能配列の実行では上書きされない事が保証されます。
実装する場所としてはcont stack側のスタックになります。
これまでのcont stlackを以下とすると、
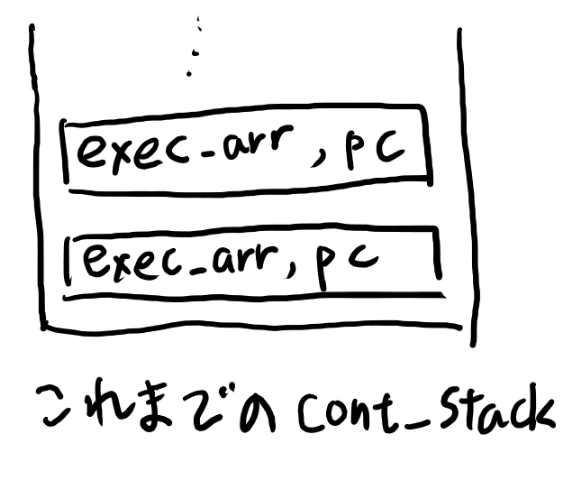
ローカル変数を実装すると以下のようになります。
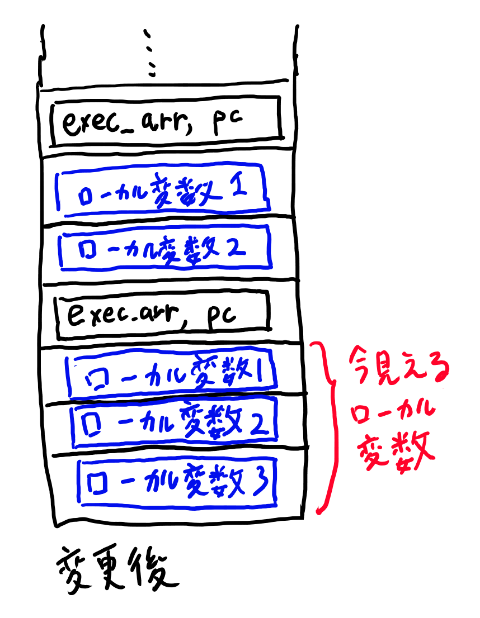
ようするにcont stackの方のスタックにも、Elementを詰めるようにする、という事です。
さらに、これまで、実行可能配列の実行が終わったらco_stackからContinuation構造体を一つpopしていたと思いますが、ここをContinuation構造体が出てくるまで全部popするように変更すれば良いでしょう。
感じとしては、以下のようなイメージです。
do {
elem = co_pop();
} while (elemがContinuationじゃない間);
という感じです。 continuationの前に積まれている物全てと、continuationを一つポップします。
つまりco stackにも入れる要素の種類を足す必要がありそうですね。適当にenumとか構造体を作って詰めてください。
ここまで来るとこのスタックはcontinuationのスタックというよりはC言語のスタックフレームに近い物になります。(引数が無い所が違うけれど)
ローカル変数のAPIを考える
ローカル変数は、基本的にはスタックからローカル変数に保存するAPIと、ローカル変数の中身をスタックに積むAPIの2つが必要となります。
以下のようなstoreとloadを考えます。
| any1 | store | - | any1をローカル変数に保存 |
| num1 | load | any | num1番目のローカル変数をスタックに積む(後述) |
loadが少しトリッキーなのは数字の意味ですね。これはcontinuationスタックのtopから何番目かを表す事にします。 これはバイトコードを書く時にちょっとややこしい事になりますが、実装は簡単です。
この2つはenumで実装してしまって構いません。 まずはこの2つを実装してみて下さい。
ローカル変数を使ってwhileの静的生成を考える
ローカル変数が実装出来れば、whileはたぶんこんな感じで実装出来るんじゃないか。
store
store % ここで 1 loadでbody部分が、0 loadでcond部分がスタックに詰めるようになる
0
load
exec
6
jmp_not_if
1
load
exec
-9
jmp
例によってここまで来るとあってるか全然分からないので、正解を実装出来たら教えてください(上のコードで実装できました by yoheikikuta)。 これをコンパイル時に生成すれば良いと思います。
なお、ローカル変数があれば、以前実装したifelseももうちょっと素直な実装に変更出来ると思います。
repeatを実装する
さて、最後にrepeatが残るのですが、普通にローカル変数をカウンタに使えば実装出来るでしょう。 と思ったけど変数を上書きする手段が無いですね。継続スタックから一個ローカル変数を捨てる、lpopでも作りましょうか。
たぶんそれ位で実装出来るかな?ちょっと自分で考えて実装してみてください。(私は考えてみてないので、原理的に不可能、とかあったら教えてください)
また、たぶん特定のローカル変数を上書きする、みたいな命令でも実装出来ると思います。lsetとか?ただこの流れならlpopの方が筋がいいですかね。どちらでもいいです。
15. ここまで実装したものを見直す
14までで第一回の言語処理系の実装は終わりです。お疲れ様でした。 最後にここまで実装してきた物がどういう物なのか、一般的な言葉との対応などを軽く交えながら振り返ってみたいと思います。
継続をあらわに実装するメリット
14を最後までやってみると、言語機能自体は11の段階までで実装した物と同じである事が分かると思います。 psファイルとしてできる事は別段増えてない。
ただ、12以降でやってきたように、自前のスタックと継続で言語処理系の実装をすると、幾つかメリットがあります。
- このco_stackをどこまで巻き戻すかで非局所脱出を実装出来る
- Cのスタックを消費しない
- C言語のスタックの理解が深まる
- 末尾呼び出しの最適化を簡単に実装できる
- コルーチンなどを実装出来る
いろいろありますが、やはり大きいのは、継続をあらわに実装するとインタープリタを途中で止めて再開出来るようになる、という事だと思います。 これはC言語の関数呼び出しの仕組みに頼っているとなかなか難しい。
非同期APIの実装が出来ないのは結構致命的なので、必要になった時にどう実現したらいいか、のやり方を知っているのは大切です。 意外と世の中の言語処理系を作ってみましょう、系の解説で非同期APIがちゃんと実装出来るevalを解説していない物は多かったりします。 そうした記事よりは大分深い理解に到達出来ているはずです。
今回はさらにコンパイル時のコード生成を本格的にやってみたら、思ったより大変になってしまいました。 もうちょっと楽なはずだったがローカル変数が必要になってしまうとは… ただ結果としてはVMに必要な要素はほぼ実装されたので、勉強目的としてはむしろやりすぎくらいの機能を持ったVMになっていると思います。
evalとcompileとeval_exec_array
ここまで解説に沿って実装してくると、だいたい
- eval
- exec_arrayに相当する物を作るcompile相当の何か
- exec_arrayを実行するeval_exec_array
という3つの物が存在していると思います。 関数名の詳細などは人によって違うかもしれませんが。
大雑把には、evalがインタープリタと呼ばれるもので、exec_arrayを作る所がコンパイラと呼ばれる物。 そしてeval_exec_arrayが、いわゆるVMと呼ばれる物になります。 この3つの構成要素について少し考えてみます。
インタープリタとVMの違いは曖昧
少し考えてみると、これらの境界は割と曖昧な事が分かると思います。
まず、evalでも、最初に入力を全部読んでexec_arrayに変換して、一番上でもeval_exec_arrayで実行する、という実装が可能です。 実際そういうふうに振る舞う言語処理系も世の中には多い。 そうしないとevalでの分岐とeval_exec_arrayの所の分岐で、同じようなコードを書かないといけないからです。
そういう形式の時には、何がVMで何がインタープリタか、という定義をあんまり真面目に考えても、現世的なご利益はありません。
それぞれが何をやっているかを理解していれば、境界の所をあまり気にしても仕方ないと言えます。
ただ、eval_exec_arrayの所は以下で見ていくように、コンパイル側とは結構分離された構成要素であるのは確かと思います。 その辺の事を以下で軽く考えていきましょう。
VMの命令セットを見直す
eval_exec_arrayに相当する物がVMと呼ばれる物だ、という話をしました。 このeval_exec_arrayについて、少し考えてみましょう。
eval_exec_arrayは今や、以下の機能を実行する何かとなっています。
- 数字やリテラルなどをプッシュするもの
- 実行可能ネームの実行
- exec
- ローカル変数
- jmpや条件付きjmp
これはかなり汎用的なもので、whileやrepeat、ifelseといった実際の言語機能とはそれほどは関係がありません。 例えばC言語のdo whileのような物を実装したり、unlessなどの新しい制御構造などを実装するとしても、 おそらくeval_exec_arrayをいじる必要は無いでしょう。 たぶんリスト内包表記のような物を実装する時でも、ここをいじる必要は無い。
だいたい今回実装した機能は多くのプログラミング言語の概念を実装するには十分な機能となっています。
コンパイルについて考える
実行可能配列を作る、というのは、eval_exec_arrayとは結構独立したコードになっていると思います。 実際、一旦実行可能配列を作ったら、それをファイルに書き出す事もできるはずです(ポインタや文字列をどうするかは本当は少し考える必要があるが)。
想像で良いので、実行可能配列を作る所を別のプログラムにする事を考えてみましょう。 入力のpsファイルを読んで、実行可能配列を作るだけのプログラム。これはコンパイラと呼ばれるプログラムになります。
文字列をパースしていって、数字とかリテラルネームなら、そのElementを実行可能配列に詰めていく。 開き中括弧が出てきたらまた再帰的に実行可能配列の生成を呼んで実行可能配列を作っていく。 ifとかwhileが出てきたらOP_PUSHとかOP_POPとかOP_DUPとかOP_EXCHとかOP_EXECをいろいろ吐いていく。
そんなプログラム、書いていけそうですかね? コンパイルだけなら、ここまで書いてきたうちどれが要らなくなるでしょう? スタックはたぶんいらない。eval_exec_arrayやprimitiveもいらないですね。 コンパイルの方のifelse_compileとかはいりそうです。 全体的には1/3行くらいになりそうですかね?もうちょっと多い?
これがコンパイラ、と呼ばれる物になります。
そうして実行可能配列をファイルに保存出来たら、これを別のマシンに持っていったりできる。
実行可能配列の実行を考える
そして別のマシンでは、この実行可能配列をメモリ上に復元して、eval_exec_arrayを実行する、というような事を考えてみます。 コンパイルの部分は別のプログラムとして、ただ実行可能配列だけを実行するプログラムを考えてみる。
どうやってファイルから実行可能配列を復元するかは置いておきましょう。メモリ上には復元出来ているとする。(ここを真面目に考えるなら第二回や第三回を終えてからの方が良いですが、イマドキのスクリプト言語ならPythonのpickleなど何かしらのシリアライズの方法はあるのでそれをイメージすれば十分と思います)。
実行可能配列を実行するだけだと、ここまで作ってきたコードのうち、どこがいらないでしょうか? コンパイルに関わる所はいらないですね。また、ifelseとかwhileはもう出てこない。OP_JMPとかになっているので。 parse_oneとかももういらない。 スタックは要りそう。辞書も要りそう(ただしコンパイルの方の辞書は要らない)。
コードとしては6割くらいになりますかね?もうちょっと多い?
このプログラムがVMと呼ばれる物になる訳です。
別のプログラム言語を考えてみる
VMはそのままいじらずに、コンパイラだけ全く別の言語用の物を考えてみる。 自分の知っている言語、RubyでもPythonでも良い。
その簡単なサブセットを考えた時に、どういう事をすればいいでしょう?
例えば
def add3(a):
return a+3
みたいな関数を、実行可能配列にするとする。するとだいたいは以下みたいな実行可能配列を作って、
{3 add}
それをadd3という名前で辞書に入れてやれば良さそうです。 そういう処理をCで書くのは、たぶんそんなには大変ではなさそう。
さらに以下のようなコードを考えてみる。
a = add3(5)
b = a+7
このようなPostScriptと見た目が大きく違うコードも、以下のようなコードになればVM自体は同じで問題無さそう。
/a 5 add3 def
/b a 7 def
もちろん一旦PostScriptを経由せずに直接実行可能配列にする方が簡単でしょうし効率的でしょうが。
よくある言語の文法を実際にちゃんと処理するならパーサージェネレータなどの勉強をする必要がありますが、 別に実際に作らなくても、普段使っている言語処理系がどんな感じのプログラムになっているか、 というのを考えられると、やっている事の理解が深まります。
普段書いているような、より自然な見た目の言語も、結局は実行可能配列みたいな物にして実行しています。 そう考えると、なんだか知らない魔法のような物として動いていた言語処理系も、 意外と何をしているのか想像がつくようになっていませんか?
そうした視点で物が考えられるようになると、新しい言語や言語機能などが登場した時も、中がどうなっているのか、という事を考えながら学んでいけるので、 より深い理解が可能となります。
第一回おわりに
ここまでで、第一回の内容は終了としたいと思います。
パーサーも書いてevalも書き、必要な辞書やスタックも書き、 インタープリタとVMが共存してコンパイラも必要となる、 かなり複雑な処理系を最終的には完成させた事になります。 行数としてはそれほどでも無い範囲に収まっていると思うのですが、いかがでしょうか?
PostScriptのコアはシンプルなので、言語処理系に初めての人でも隅から隅まで理解出来ると思います。 実行可能ネームの実行に相当する部分をちゃんと初心者でも理解出来るのは、このPostScriptくらいなんじゃないでしょうか。
C言語の入門書だと、なかなか複数のファイルに分けての作業をするのは難しいと思います。 ですが今回の処理系だとファイルは自然と辞書、スタック、eval、パーサーくらいには分かれると思いますし、 もう少し多くなるのが普通でしょう。 ヘッダファイルやリンク、staticをつけるかどうかなどは、 やはりこの位のサイズのプログラムを書かかないと、こうした機能のありがたみは分からないですよね。
mallocなども入門書を読むだけだと良く分からない所ですが、 今回はパーサーの所や辞書の所などで、それなりにちゃんと理解してないとクラッシュしてしまうので、 手頃な練習になっているんじゃないか、と思っています。
また、実行可能ネームの実行はそれなりに複雑なので、いい加減に書くとバグだらけで全然動かなくなってしまうと思います。 綺麗に書くとはどういう事かについて、それなりの規模で体験出来るのも良いと思います。 やはり難しいバグが出て初めてコードが良いかどうかが問われると思うので。
将来的に言語処理系自体は作らなくても、似た構造の物は結構多いものです。 何かをパースして内部表現を作り、それを評価する、というタイプのプログラムなら、 だいたい同じような構造になります。 一度言語処理系を書いた事があれば、そうしたプログラムなら割とスラスラ書けるようになっていると思います。
一応C言語の入門書は終えたが本格的なプログラムは書いた事無い、 という人でもやれるくらいを目指して作りました。12の継続から先はちょっとその範囲を超えているかもしれませんが。
第二回では、今回軽く導入したスタックフレームについてもう少し深く理解するのと、 バイナリ操作を練習する為に、アセンブリとOS無し環境でのプログラムについて扱います。
おまけ
以下は実装するの不要だな、とは思ったけど、補足として知識くらいは知っておいてもいいかな、 と思う事についてなんとなく書いていきます。
おまけ:シンボルの話
実装はしませんが、シンボルの話を最後におまけとしてしておきます。
シンボルというのはいろいろな所で使われる曖昧な用語ですが、今回議論するのはLispやRubyなどのシンボルです。
シンボルというのは、文字列と一対一に対応するintの値です。 PostScriptには自分の知る限りシンボルという言語機能はありませんが、LispやRubyなどでは言語で明示的にサポートされています。 これを用いるとPostScriptっぽくはなくなりますが、幾つかメリットもあるのでその話もしておきましょう。
シンボルってどんな物?
シンボルという考えの前提としては、プログラムの中で出てくるユニークな文字列というのはそんなに種類が無い、という前提があります。 実際、実行可能ネームやプリミティブを全部合わせても、ほとんどのケースでユニークなワードなんて256個も無いでしょう。
本格的なプログラムでも、intの最大値ほどのシンボルが出てくる事は実質無いと言って良いでしょう。
そこで、プログラムで新しい文字列が登場するごとにintの値を1から順番に割り振っていくと、その文字列をidで表す事が出来ます。 このidから逆の文字列を引く事も原理的には出来るはずです。
例えば以下のようなAPIがシンボルのAPIとして考えられます。
int string_to_symbol(char *s);
char *symbol_to_string(int symbol);
symbol_to_stringはどこかに確保されている文字列のポインタを返します。
簡単な実装方法
string_to_symbolを実装する為には、擬似コードとしては以下のような感じになります。
static int next_id = 1;
static Map<string, int> map;
int string_to_symbol(char *s) {
if(mapにsがあったら) {
return map.get_value(s);
}
map.put(s, next_id);
return next_id++;
}
Mapに相当する物をC言語で書いてやる必要がありますが、これは以前実装したハッシュや、二分木とその発展系のバランスドツリーなどが使われます。 コンパイル時しか使わないならニ分木で十分でしょう。
このmapをなめる事で、idから文字列を引く事も出来ます。 普通文字列からシンボルへの検索は高速で、逆は遅くても良い、というのがシンボルの性質です(デバッグ出力時くらいしか文字列には戻さない)。
シンボルを用いたliteral nameなどの実装を考える
literal nameをスタックにプッシュする時はシンボルの値、つまりintのidを詰めれば良いでしょう。 defの実装の時には、だいたい連続したintのidになるのだから、保存先はハッシュでは無く配列で良くなるでしょう。全部のシンボルがdefされる訳では無いので間が空く事もありますが、全体としては大したサイズにならなければシンボルのidをインデックスとしてしまって1024の配列でも作っておけばお釣りが来るでしょうし、 大規模なPostScriptを動かすとしてもintをキーにしたハッシュを使えば良いでしょう。
パーサーでexecutable wordが出てきたら、その時点でsymbolを引いて以後はその数値を使えばいいでしょう。 実行可能配列に詰める時もintが使えます。
さて、こんな事をするとどういうメリットが考えられるでしょうか?
メリット1:バイトコードから文字列がなくなる
これが一番のメリットと思います。バイトコードを作る時点で全部intの値に変換されるので、バイトコードとしては文字列のポインタは出てこなくなる。 すると、バイトコードをevalする方ではmallocなどの複雑なメモリ管理は要らなくなります。
これは、バイトコードにコンパイルする場所と、それを実行する場所を分けたいような時には重要になります。 例えば貧弱なOSが無いような環境でバイトコードを動かしたい場合、 どこか別のPCで一旦バイトコードを作っておけば、二分木やハッシュは実行する側では必要無くなります。
そこでかなり貧弱なチップの上でも簡単なスタックと配列くらい作れれば実行出来るでしょう。
メリット2: 文字列の重複がなくなるのでメモリ使用量が減る
同じ文字列が何度も出てくると、これまでの実装では毎回別々にmallocされてしまっていました。 例えば以下のようなコードを考えると、
/temp { add add add add add } def
addという文字列は5回確保されていまっていたと思います。
でもシンボルを使えば、一つの文字列ごとにmap上に一回確保されるだけで、以後同じ文字列が出てきたら数値に置き換えるので、 addは一回確保されるだけで済みます。
メリット3:実行時の比較が高速
シンボルは一回シンボルに変換されると、あとは==で簡単に一致しているかどうかが比較出来ます。 一方、ハッシュはかなり高速ですが、それでもハッシュのキーを計算するのに一回文字列をなめて、 さらに衝突があった場合の線形リストのサーチでも文字列を何回か比較します。
この比較が全てintの比較に置き換えられるので、高速になるのはわかるでしょう。
今回シンボルを実装しなかった理由
という事でシンボルを用いると良い事はいろいろあるのですが、今回はまぁいいか、と実装を見送りました。 大きな理由は3つで、
- ハッシュの所の実装の感動が薄れる
- PostScript的では無い
- どうせ次のアセンブラ実装する時には実装する
というものとなります。
1つ目はC言語の勉強としてはハッシュテーブルを自分で実装する、というのは結構重要だと思ってます。 この文字列をキーにしてなんでも引けるデータ構造を作れた、というのは覚えてもらいたい所なのですが、 間にシンボルが入るとintをキーにして物が引ける何かになってしまって、あんまりハッシュテーブルの凄さが伝わりにくい。 そのほかの用途でも文字列をキーにしたハッシュテーブルの実装が必要になる事はちょくちょくあるので、 そこはあんまり複雑にしたくなかったというのが1つ目の理由です。 なるべくオーソドックスなハッシュテーブルにしておきたかった。
二つ目はPostScriptは言語仕様の段階で非常に辞書的な仕様になっています。 もともとpsファイルはプリンターなどが一回だけ処理してプリントしていく物なので、 初回実行の速さが重要なインタープリタ的な物だと思います。 言語仕様も非常に動的で、さらに辞書とスタックだけでいろんな事が出来る、 というのがPostScriptの味だと思うので、シンボルなどの余計な要素を足すとPostScriptの良さが損なわれてしまうな、と思ったのです。 勉強で実装するならそのシンプルさと強力さの方が重要と思うので、 今回はシンボルという要素は導入しませんでした。
ただ今回作ったeval_exec_arrayなどは、文字列比較さえなくせばとても小さいプログラムにする事が出来て、 OSが無い環境でも簡単に動かせる、というのもPostScriptの魅力の一つだと思うので、 おまけとして記述しておきました。 実装には難しい事は無いと思うので、必要になったら自分で出来ると思います。
おまけ:マクロの話
C言語のマクロはプリプロセッサで実装されていて言語と統合されてませんが、 世の中には言語と統合されたマクロのある言語が結構あります。 lispやrustなどが有名ですね。
こうした言語のマクロとは何か、というのは、ここまで実装してみると厳密に理解する事が出来ます。 マクロとは、ようするにifelse_compileなどのXX_compileを言語内で定義してcompileの方の辞書に登録する機能です。
emitterが言語から触れて実行可能配列を組み立てるような関数を言語内で定義出来れば、それをコンパイル側の辞書に登録できるようにするだけでマクロがサポート出来ます。
実行もeval_exec_array側ではなくてcompile_exec_array側で実行されます。 静的コード生成でいろいろ実装してきた今となっては、難しい事は特に無いんじゃないかと思います。
ただ個人的には現代的な言語の主流としてはマクロを廃する方向だと思っているので、教養として知っていれば十分かな、と思います。
おまけ:Javaバイトコードの話
Java VMのバイトコードはPostScriptを理解したあとだと結構簡単に読めるので、 簡単にその話をしておきます。あくまで概要くらいですし、動作確認してないので動かなかったらごめんなさい。
まずJavaのバイトコードとPostScriptの違いは、オペレータに引数がある所です。 オペレータと引数を合わせて一つのトークンのように読んでいくと良いと思います。
例えば数字の1をスタックにプッシュするには ldc 1とします。 で、足し算はiaddなので、1+2は以下みたいなコードになります。
ldc 1
ldc 2
iadd
結果は3がスタックに置かれます。 結構似てませんか?
実行可能配列みたいなのはありません。 だからifelseよりは継続の所で作ったjmp_not_ifに似たジャンプ命令があります。
ifne ラベル
という形ですね。だから例えば、現在スタックのトップが1だったら何かする、みたいなのは以下みたいになります。
ldc 1
lcmp
ifne GotoEnd
// スタックは1
GotoEnd:
lcmpはlongのcmpです。普通に考えればicmpがあるべきですが、 intはもっと特化した命令がたくさんあるのでicmpは無いみたいです。(だからひょっとしたらlcmpだと動かないかも。動かなかったらすみません)
なかなか似てませんか?
staticメソッドを呼ぶ例も見てみましょう。 あまり細かくは説明しませんが、雰囲気は分かるんじゃないでしょうか。
getstatic java/lang/Math/PI D
ldc 4.0
ddiv
invokestatic java/lang/Math/sin(D)D
java.lang.MathからPIというフィールドの値を取り出しスタックに置きます。型はdoubleです。
次に4.0をスタックに置きます。
ddivでこの2つを割って結果をスタックに置きます。
最後にMath.sinを呼びます。引数は Math.PI/4.0 です。
ddivで割って結果をスタックにおいたままMath.sin呼ぶの、ちょっとPostScriptっぽく無いですかね?
オブジェクトを作ったりするとコンストラクタを呼んだりしないといけないとかあってもうちょっと面倒になるのと、あとローカル変数という新しい概念があったりしますが、それでも結構な量のコードがスタック関連になるので、PostScriptの経験は結構生きてくると思います。
今回14で実装したローカル変数もJavaバイトコードには良く似たistoreとiloadというのがあります(というより今回作ったのはこれを参考にした)。 istoreは引数にローカル変数のインデックス(0から255までの数字で、変数のidとして使う)を指定し、
ldc 123
istore 1 // 123をスタックからpopして、ローカル変数1に保存
iload 1 // ローカル変数1の中身をスタックにpush
今回我らが作った物と違う所としては、store側でも変数のインデックスが指定出来る所ですね。 このおかけで、わざわざlpopとかしなくても同じ変数を上書き出来るので、repeatとかを実装するのは簡単になります。 今回我々の実装でこうしなかったのは、ちょっとだけVM側の実装が面倒になるからですが、 真面目なVMを作るならJavaバイトコードのようにstoreでもインデックスを指定出来る方がいいでしょうね。
Javaバイトコードはよく出来ているので本格的なVMを勉強したい時にはおすすめの題材です。
以下参考文献など。
- JVM Spec, Chapter 3. Compiling for the Java Virtual Machine 仕様書の三章。具体例はこの辺が良く書けている。仕様書読める人は仕様書が一番。
- JVM Spec, 6. Instruction Set 具体的な命令については6章を読む。
- わらばんし仄聞記 Javaバイトコードの読み方 Javaバイトコードの入門としては短くて分かりやすいと思います。
- Introduction to Java’s bytecode reading バイトコードを実際に読む時の入門。コメントの形で解説が書かれているのでぱっと見解説があまり無いように見えるが、良く読むと結構いろいろ書いてある
- Reading Java methods in bytecode 同サイトのもうちょっと長い関数の解説。これも結構コメントで解説が書かれている。
- Amazon: JAVAバーチャルマシン (THE JAVA SERIES) 自分は昔この本読みました。今ならもっと良い本があると思いますが、この本は割とself containedで全部分かった、とは思えた気がする。
お疲れ様でした。次の第二回 簡易アセンブラとディスアセンブラを作ろうも良かったらどうぞ。