第三回 バイナリやアセンブリから見るC言語とリンカ
第三回では、第二回で学んだバイナリやアセンブリの知識を元に、C言語の理解を深めていきます。
オブジェクトファイルやリンクなどを理解し、実行時のローダーの基本を理解すると、コンパイルやリンク、実行した時などのエラーを自分で解決出来るようになって便利です。
また、C言語の実際の挙動を調べる為にコンパイラにアセンブリを生成させて、それを調べる、というやり方を学びます。
第三回は第二回 簡易アセンブラとディスアセンブラを作ろうの続きです。 第二回を終えている事を前提に解説します。
01 アセンブリからC関数を呼ぶ
第二回では、ARM向けのコードはフルアセンブリで書いてきました。
ですがC言語のメリットの一つは、アセンブリとの親和性の高さです。 具体的にはアセンブリからC言語の関数を呼んだり、逆にCからアセンブリの関数(?)を呼んだりできます。
ここでは、最低限のセットアップだけでCの関数をアセンブリから呼ぶ、という事をやってみましょう。
C言語の関数はアセンブリからどう見えなくてはいけないか?
C言語の関数がアセンブリからどう見えなくてはいけないのか?というのは、 実はC言語の仕様というレベルでは決まっていません。 決めるのは言語仕様では無く、ターゲットとなる環境が決めています。
各環境ごとのコンパイラが、C言語の仕様をターゲットの環境の定めるアセンブリのルールに変換する、という責任を持っている訳です。
ARMの場合は以下の文書が「C言語の関数は、アセンブリからどう見えないといけないか?」という決まりを説明したものになります。
読むのは面倒なのでここで必要な事だけ要約すると
- r0, r1, r2…と最初の方のレジスタを引数に使え
- r13にはスタックに使うアドレスをセットしておけ
- スタックはstmdb-ldmaiの方向に伸ばせ
という風になってないといけない、という事が書いてあります。
ドキュメントを頑張って読むよりは実際に見てみる方が早いので、以下、実際にやっていきましょう。
volatile使ってC言語側でprint_msgを作る
以下にある、
sources/casm_link/01_call_c/1_1_call_c
hello.cの先頭にあるコメントを読んで、同じコマンドを実行してみましょう。 いつもの通りHello Worldが表示されたと思います。
ここでvolatileというのは、C言語のコンパイラにUARTのアドレスなど特別な意味を持つ、という事を教える為のキーワードです。 これが無いとただ無意味にメモリに値をひたすら上書きしているだけ、とコンパイラは判断し、最適化で最後に書き込んだ値のコードしか残してくれません。
そこでvolatileというキーワードをつけて、ここへの代入はメモリとは違って意味があるので、最適化しないでください、とコンパイラに指示を出します。
hello_c.sを眺めてみる
以下ではhello_c.sとhello.cが実際にどう実行されていくかを見ていきましょう。
アセンブリ側は以下のようになっています。
.globl _start
_start:
ldr r13,=0x07FFFFFF
bl hello_c
loop:
b loop
まずldr命令でr13にスタックに使うメモリのアドレスを指定している。これは2.5でやった奴ですね。
そして次が新しい。bl hello_cという行。 blはr15を保存しつつジャンプする、という奴でした。 問題はhello_c。
これはラベルに見えるけれど、そのラベルはこのファイル内には無い。 どこにあるか?というと、hello.cの側にあります。
次にこちらを見ていきましょう。
hello.cを見てみる
ではC言語側を見てみましょう。
すると、以下のような関数が定義されています。
int hello_c() {
...
}
これが先ほどblしていたhello_cというラベルの正体になります。
もう少し詳しく見るべく、このCのソースがどういうアセンブリになるかをコンパイラに吐かせてみましょう。 その為には-Sというオプションを付けます。
sources/casm_link/01_call_c/1_1_call_cのhello.cをコンパイルしてアセンブリを吐く。
arm-none-eabi-gcc -O0 -fomit-frame-pointer hello.c -S -o hello_gcc.s
オプションの大文字のOは最適化を切る、という意味で、小文字の-oで出力先のファイル名を指定します。これでhello_gcc.sというファイルが生成される。omit frame pointerは生成されるコードを少しシンプルにする、というものです。あまり気にしなくてOK。
では中を見てみましょう。
最初の方に.eabi_attributeとかがずらずら出ますが、これらはあまり気にしないのがゆとり(自分も良く知りませんし、無くても最終的には同じバイナリになります)。
その次に、hello_cというラベルがある。
hello_c:
@ Function supports interworking.
@ args = 0, pretend = 0, frame = 0
@ frame_needed = 0, uses_anonymous_args = 0
@ link register save eliminated.
ldr r3, .L3
mov r2, #72
strb r2, [r3]
ldr r3, .L3
...
.L3ってなんだ?というと、最後の方に埋め込まれている、UARTのアドレスです。
.L3:
.word 270471168
270471168ってなんだよ、というと、0x101f1000の事です。
r3にこのアドレスを入れて、あとはひたすらアスキーコードをstrbでこのアドレスに代入している訳ですね。 ここまで進めてきた人なら、この程度のアセンブリを読むのはなんでも無いでしょう。
最後の所はちょっと興味深い。
hello_c:
...
mov r3, #1
mov r0, r3
bx lr
lrはr14の事です。bxはthumb命令が絡むので詳細は説明しませんが、ようするにbの事です。 r14はbl命令で飛ぶ時に、飛ぶ元のアドレスを自動で入れてくれるのでした。 なのでb r14で呼び出し元にreturnする、というような意味になります。
r3に一回代入しているのは意味が分かりませんが(コンパイラはたまにこういう意味の無いコードを生成する)、ようするにr0に1を入れて、b r14してます。
これがC言語の関数という物をコンパイラがコンパイルする時の基本になります。 まとめると以下のようになります。
- r13はすでに適切にセットされていると思う
- 関数名と同じラベルを作る
- 関数の最後ではr0に結果を入れてb r14する(つまりr14には呼び出し元のアドレスが入っている)
基本的にはこういうコードを生成しています。hello.cのソースと、生成したアセンブリを良く見比べて、この事を確認してください。
課題: アセンブリから文字列を渡して表示してみる
アセンブリ側からC言語の関数に何かを渡してみましょう。 以下の場所
sources/casm_link/01_call_c/1_2_call_c_msg
に、print_msg.cとmain.sというファイルが作ってありますが、main.sの方は未完成です。 これを完成させてください。(print_msg.cの先頭に実行すべきコマンドがコメントで書いてあります)
print_msg.cは以下のような中身になっています。
#define UART ((volatile char *)0x101f1000)
void print_msg(char *s) {
while(*s) {
*UART = *s++;
}
}
アセンブリは、main.sというファイル名のファイルに書いて行く事にします。 先ほどのhello.sを参考に書いてください。
ヒント:
どうやって呼び出したらいいか想像する為には、print_msg.cのアセンブリを吐かせてみましょう。 例えば以下みたいなコマンドで、tmp_print_msg.sというファイルにアセンブリが吐かれます。
arm-none-eabi-gcc -O0 -fomit-frame-pointer print_msg.c -S -o tmp_print_msg.s
変数を渡すのに関係ありそうな所を抜き出すと以下のようになっています。
print_msg:
sub sp, sp, #8
str r0, [sp, #4]
b .L2
.L3:
...
.L2:
ldr r3, [sp, #4]
ldrb r3, [r3] @ zero_extendqisi2
cmp r3, #0
bne .L3
nop
add sp, sp, #8
@ sp needed
bx lr
なかなか解読は大変ですが、r0を[sp, #4]に入れて、あとはこの[sp, #4]をC言語側の変数sのように使っているようです。spはr13の事です。
ですからr0に変数の先頭のアドレスが入っていれば良さそう?
Cの関数の呼び方まとめ
- r13にスタックとして使うアドレスをセット
- r0とかに引数をセット
- 関数名のラベルにbl
これでCの関数をアセンブリから呼べます。
逆にアセンブリの側で、上記のルールと同じに見えるラベルを用意してやれば、C言語の関数として呼ぶ事が出来ます。
02 分割コンパイルとリンク
次に分割コンパイルとリンカについて簡単に説明します。 C言語で開発をしていると、この辺のトラブルがちょくちょく出てくるので、基本的な事を知っておくと便利です。 また、分割コンパイルとリンクを理解すると、C言語から実行可能バイナリを生成する手順が良く分かるようになります。
ここでは以下のフォルダで作業します。
sources/casm_link/02_sep_comp/
コンパイラとQEMUのセットアップ
ここからはC言語の方をメインにしたいので、bare metalで面倒な時は普通にOSがある場合でいろいろ試したい。
ここまではversatilePBを使ってきたのでこの上にLinuxを動かしてもいいのですが、少し大変なので手抜きとしてuser modeを使います。 これは厳密にはOSの上で動かすのとは違うのですが、実行ファイル側はOS上で実行するのと同じなので、ここでの説明としては十分です。 (なお、必要な環境構築用のDockerfileを sources/casm_link/Dockerfile.CASM_LINK に準備したので使い方が分かる人はどうぞ)
sudo apt install qemu-user
sudo apt-get install gcc-multilib-arm-linux-gnueabi
OS上で(この場合はARMのLinux上)実行するバイナリを作る為には、コンパイルはarm-linux-gnueabi-gccという名前のコンパイラを使います。(ひょっとしたらsudo apt install gcc-arm-linux-gnueabiもいる?たぶん要らないと思うので誰か確認したら教えてください) (自分は必要ありませんでした。環境は Docker で構築した ubuntu 18.04.1 LTS by yoheikikuta)
objdumpなども同様です。少し名前が変わってるので並べておきましょう。
| bare metal | OSあり |
|---|---|
| arm-none-eabi-gcc | arm-linux-gnueabi-gcc |
noneがlinuxに、eabiがgnueabiになってる事に注意してください。
動作確認として、sources/casm_link/02_sep_compで、以下を実行してみましょう。
arm-linux-gnueabi-gcc hello_printf.c main.c
qemu-arm -L /usr/arm-linux-gnueabi ./a.out
これでHello Worldと表示されればOKです。
ここからは基本的にはこのOSアリ版を使っていきますが、たまに比較の為に以前のコードも見ます。その場合はbare metalでの話になるので注意してください。
分割コンパイルをしてみる。
まずは分割コンパイルをしつつ、その途中に出来るオブジェクトファイルなどを簡単に覗いてみます。
分割コンパイルのやり方
gccやclangというコマンドは、コンパイラと呼ばれていますが、 実際はコンパイル以外の事もいろいろやってくれます。
具体的には以下の四つの作業を順番に行います。
- プリプロセッサの展開
- コンパイル
- アセンブル
- リンク
これらは一気に行われますが、一つだけやらせる事も実は出来る。
例えば-Eのオプションをつけると、プリプロセッサの展開だけやってくれます。 プリプロセッサとはマクロとかincludeとかifdefとかシャープで始まるそういう奴です。 昔はC言語以外のスクリプトとか設定ファイルでマクロを使って、Cのプリプロセッサで処理させるとか結構やられてたので良く使いましたが、近年ではマクロのデバッグ目的でしか使わなくなりました。
コンパイルだけを行うのは-Sです。これは後述します。
アセンブルまでで止めるのは-cです。 このオプションを付けると、コンパイラが生成したアセンブリをアセンブラがバイナリに変換してオブジェクトファイルにします。
例えば以下のようにするとmain.oが出来ますし、
arm-linux-gnueabi-gcc -c main.c
以下のようにすればhello_printf.oが出来ます。
arm-linux-gnueabi-gcc -c hello_printf.c
main.cにはprint_somethingの実装も無ければstdio.hをincludeもしていませんが、-cをつけるとオブジェクトファイルを生成する事が出来ている事に注目してください。
アセンブルまでならすべての「シンボルが解決」されている必要は無いのです。 「シンボルが解決」とはなんなのか?について、以下で少し見ていきます。
nmでシンボルを確認する
シンボルを確認する方法は幾つかありますが、nmコマンドを使うのが一番普通のやり方だと思います。
例えば以下のように実行すると、main.oのシンボルが確認できます。
nm main.o
なお、この場合nmは現在実行しているマシンでの環境のnmが使われてしまいますが、nm自体は他の環境でも動くのでこれでも問題無いはずです。
厳密にはgccやobjdump同様、ターゲットの名前が前についた方を実行するのが正しい。
arm-linux-gnueabi-nm main.o
これを実行すると、以下のような表示が出るはずです。
00000000 T main
U print_something
nmの出力には三つのセルがあり、それぞれ、
- 値
- シンボルの種類
- シンボルの名前
が表示されます。一行目は値が00000000、種類がT、名前がmainという意味です。 二行目は値がありません。
種類はTがテキストでUが未解決、という意味です。 種類の詳細はググれば解説が出てくると思いますが、例えばnmのmanページなどに書いてあります。ただ必要なのはそんなに多くないので出てくる都度簡単には説明します。
Tはテキストセクションに配置されるシンボルという事ですが、この時点では定義されている、という意味くらいに思っておきましょう。テキストセクションについては後で解説します。
print_somethingはmain.cでは定義されてないので「この関数は使われてるけど、これが何なのかは僕は知らないよ~」という状態になります。これをシンボルが「未解決」と呼びます。
hello_printf.oの方も試してみると以下のような出力になると思います。
00000000 t $a
00000000 T func1
00000024 T print_something
U puts
ドルaが何かは私も知りません。あまり気にしないでいきましょう。
func1とprint_somethingというのがTなのでこのオブジェクトファイルで定義されている事になります。
そしてここから呼び出しているputsはstdio.hの中にある関数なのでこのオブジェクトファイルでは定義されていない、という事になる。
オブジェクトファイルとは何か?その1
オブジェクトファイルとは、大まかには二つの情報が入ったものです。
- シンボル
- バイナリ
バイナリはアセンブラや逆アセンブラを作った時に操作してきた、あのARMのバイナリです。 ですが、オブジェクトファイルの時点では、最終的なアドレスは決まってない。 このオブジェクトファイル内だけの相対アドレスとして、先頭が0番であるかのようにバイナリを生成します。
この辺の事はobjdumpをしてみると分かります。自分でやってみてください(あとで解説もします)
このARMバイナリの他に、シンボルという情報も入っています。 これは、このオブジェクトファイル内で定義されている関数の名前や、このオブジェクトファイルから参照されている関数の名前です。
この定義されている名前と必要な名前の情報を、リンクという過程で「解決」して一つのバイナリにくっつけます。
2つのオブジェクトファイルをリンクしてみる
リンクは、本当はldというコマンドで実行します。 例えば以下のようなコマンドで、とりあえずリンクをする事が出来る。
arm-linux-gnueabi-ld hello_printf.o main.o -lc --entry main
ただこれでは実行する時にld.so.1がどうとか、で怒られます。 C言語というのは、暗黙のうちにcrt0.oや幾つかのライブラリなどをリンクする事を前提にした言語です。 リンクをする時にはそれらを指定してやる必要がある。
これが最近は結構多いので、このldコマンドを直接使ってオブジェクトファイルを実行する事はあまり無くなりました。
gccコマンドなどを使えば勝手にこの辺の事はやってくれるので、以下のようにリンクもgccコマンドを使ってしまうのが簡単で良いでしょう。
arm-linux-gnueabi-gcc hello_printf.o main.o
これが実際にはどれだけの事をやってくれるかは、-vオプションを付けるとみる事が出来ます。
さて、リンクしたら先ほど未定義だったものが解決されているのを確認。
nm a.out
いろいろなライブラリなどがリンクされるので、知らないシンボルが大量に出てくると思いますが、気にしないで知ってる所だけ見ましょう。
すると以下みたいになってると思います。
000103fc T func1
00010444 T main
00010420 T print_something
U puts@@GLIBC_2.4
func1, main, print_somethingは解決されました。 putsはUのままですが、GLIBC_2.4というのが使われる事が分かります。
これは共有ライブラリとして実行時に解決されるのだと思いますが、その辺の事は今回は解説しません(C言語の入門からは少しはみ出てしまうので)。
なお、コンパイル時に-staticというオプションをつけると、この辺の物もリンクできます。 以下のコマンドで確認できます。
arm-linux-gnueabi-gcc hello_printf.c main.c -static
nm a.out
こうすると、前回よりもさらに大量にシンボルが出てくると思いますが、その中から頑張ってputsなどを探すとWになっている事が分かります。 この辺は自分もそんなには詳しくないので深入りはしません。
解決されてないシンボルのバイナリを眺める
次にmain.oをobjdumpしてみましょう。以下のコマンドになります。
arm-linux-gnueabi-objdump -S main.o
すると以下のような出力が得られるでしょう。
00000000 <main>:
0: e92d4800 push {fp, lr}
4: e28db004 add fp, sp, #4
8: e59f000c ldr r0, [pc, #12] ; 1c <main+0x1c>
c: ebfffffe bl 0 <print_something>
10: e3a03000 mov r3, #0
14: e1a00003 mov r0, r3
18: e8bd8800 pop {fp, pc}
1c: 00000000 .word 0x00000000
今となってはかなり見慣れた部分もあると思いますが、オブジェクトファイルだとちょっとこれまで見てきた物と違う所もあります。
- アドレスが0から始まっている
- 4行目のbl、ジャンプ先は自分自身になっている(ebfffffeが自身のアドレスになっているのはもう読者の皆様の方が詳しいでしょう)
- 3行目のldr、ロードしている先は1cになっているが、その1cの行(最後の行)は.wordで0が埋め込まれている
さて、次にリンクしてa.outをobjdumpしてみましょう。 リンクは以下の方法とします。
arm-linux-gnueabi-gcc hello_printf.o main.o
ずらすら出てきてしまいますが、mainの所を見ると以下のようになっています。
00010444 <main>:
10444: e92d4800 push {fp, lr}
10448: e28db004 add fp, sp, #4
1044c: e59f000c ldr r0, [pc, #12] ; 10460 <main+0x1c>
10450: ebfffff2 bl 10420 <print_something>
10454: e3a03000 mov r3, #0
10458: e1a00003 mov r0, r3
1045c: e8bd8800 pop {fp, pc}
10460: 000104d4 .word 0x000104d4
- blのとび先は10420になっている(ebfffff2)
- 最後の行の.wordには0x000104d4という謎のアドレスが入っている
一応次回予告的にこのアドレスの中身を見る方法も書いておきましょう。 それは-jと.rodataというオプションをつけます。
arm-linux-gnueabi-objdump -S -j .rodata a.out
すると以下のような出力になると思います。
Disassembly of section .rodata:
000104d0 <_IO_stdin_used>:
104d0: 01 00 02 00 48 65 6c 6c 6f 20 57 6f 72 6c 64 00 ....Hello World.
ふたたび、オブジェクトファイルとは何か?
オブジェクトファイル、というのは、ほとんど最終的なバイナリと同じ物が入っていますが、以下の点が異なります。
- 先頭のアドレスは0という事にしてすべてのバイナリが構成されている
- ファイルの外へのジャンプはいい加減なアドレスになっている(自身へのアドレス)
- グローバル変数などのアドレスは0から始まるという前提になっている
そして2や3は、あとで「解決」出来るようにシンボルのテーブルという付属のデータがある。 これがnmコマンドで表示される物です。
そしてリンク、という事をすると、このシンボルテーブルを使ってアドレスを「解決」します。 これは簡易アセンブラを作った時に、最後にラベルのアドレス解決をやったのと似た作業ですね。
分割コンパイルまとめ
- gccコマンドはコンパイルの他に、アセンブルやリンクもやる
- オブジェクトファイルの生成までやるには-cオプションを使う
- nmコマンドでシンボルという物の情報が見られる
- オブジェクトファイルはグローバル変数や自身のコードがアドレス0から始まっている、という前提のコードになっている
それでは以上を元に、リンクについてもう少し細かい話をしていきます。
03 リンク入門
ここまで見てきた分割コンパイルの話を元に、リンクという物について解説してみたいと思います。 リンクというのはC言語とプラットフォームの境界に当たる所なので、 以下の話はLinux特有の話とC言語全般の話の両方を含みます。
個人的にはC言語とUnixの境界を議論するのはあまり意味が無いと思っているので、このページでもあまり区別しません。
C言語と三つ(+一つ)のセクション
まず、C言語のコンパイル結果というのはアセンブリになるのですが、 このアセンブリは疑似命令などを使って、三つの「セクション」と言われる領域に分けてバイナリを生成します。
セクションには、まず以下の三つがあります。
- text
- data
- bss
textはプログラムのコードが置かれるリードオンリーな領域です。 dataとbssはグローバル変数が入る領域です。 dataとbssの違いは以下で見ていきますが、dataが初期化されるグローバル変数、bssが初期化されないグローバル変数を置く場所です。
bssとは何か、とか、なぜ初期化されないグローバル変数は扱いが違うのか、とかはあとで説明します。
また、ここでの話では出てきませんがもう一つ、rodataというセクションがあります。 これは文字列定数などを置いておく所です。textセクションでも文字列定数をおいておく事はできるので、一番単純には上記3つだけ考えれば十分です。 ですがあとでこのrodataもちょっと登場するので頭の片隅に入れておいてください。
さらに、ここに述べてないものもいろいろあります。 そういうのは私も良く知らないので、ちゃんと詳しく理解したくなったら、自分で調べる、くらいでいいでしょう。 最低限はtext, data, bss, rodataです。
では、以下で具体例を見てみましょう。
Cにおける宣言と定義
以下に、さまざまなグローバル変数や関数を置きました。
sources/casm_link/03_link_test
まずはmany_symbols.cとmain.cのコードを見てみてください。 それほど難しいコードでは無いのですぐに理解出来ると思います。
一応以下で実行も出来るはずです。
arm-linux-gnueabi-gcc many_symbols.c main.c
qemu-arm -L /usr/arm-linux-gnueabi ./a.out
C言語のグローバル変数と関数には、以下の二つがあります。
- 宣言 (externがつく奴)
- 定義
C言語はexternはあっても無くても同じような振る舞いをするので、あまりexternはつけないかもしれませんし、 宣言と定義の違いについて、あまり意識した事は無いかもしれません。 ですがリンクを考える時にはこの辺の違いが重要になります。
原則としては、最終的にリンクされたバイナリにおいて、定義は一か所、宣言はいっぱいあって良い。 どこか一つのファイルに定義があって、他のファイルからは宣言を書いて参照する、というのが基本になります。
以上の記述は原則なので例外があります。 原則は、
- 関数
- 初期化のあるグローバル変数
では正しい。 ですが未初期化のグローバル変数は少し例外的な扱いをします。
C言語の未初期化グローバル変数は、複数同じシンボルの定義があったら、それは同じグローバル変数だと思います。 この時のグローバル変数の行が定義なのか宣言なのかは、区別は曖昧です。
C言語は初期化がある場合と無い場合でグローバル変数の扱いがすごく違う、変な言語です。
以上の具体例を、many_symbols.cの中身を見る事で確認してみましょう。
ヘッダファイルのincludeについて考える
C言語では、ヘッダファイルのincludeというのをしますね。
これがプリプロセッサ、と呼ばれているのも知っていると思います。
さて、このinclude、何をやってるかというとそのファイルの中身をそのままコピーする、という事をやります。
この事はgcc -Eなどをしてみると、展開結果のテキストファイルを見る事ができるのでやってみてください。
で、このヘッダファイルの中には、宣言を並べておく、というのが基本になります。これをincludeすると宣言がコピーされるので、自分で宣言をするのと同じになります。
そしてどこかで定義されている関数を使う事ができる、という訳です。
これは自分でヘッダファイルを書く時も一緒で、ヘッダファイルには宣言を書くようにしなくてはいけません。
例えば初期化のあるグローバル変数をヘッダファイルに書いて複数のファイルからincludeするとリンクする時に怒られるはずです。
初期化の無いグローバル変数は上でも書いたように特別扱いされるのでなんとなく動いてしまうので、この辺をちゃんと理解してなくてもなんとなく動くヘッダファイルは書けてしまいますが、トラブルが起こった時は宣言と定義をちゃんと区別して調べると良いと思います。
また、ヘッダファイルをincludeしなくても手で宣言を書いてやれば動く、という事も知っている方が良いでしょう(お行儀は悪い方法ですが)。
例えばstdio.hをincludeする時には、どこかでこれを定義したオブジェクトファイルもリンクしています。
それはgccコマンドなどが勝手に追加しているデフォルトのライブラリという事になります。
デフォルトのライブラリ以外のライブラリを使う時には、includeを足すだけではなく、リンクの時にライブラリの名前も足さないといけないはずです。(なおこのシリーズではライブラリとオブジェクトファイルの関係はやりませんが、ライブラリはだいたいはオブジェクトファイルをくっつけた物、と思っておいてOK)
Cのコードと三つのセクションの対応
many_symbols.cには、シンボルにかかわる限り、以下の要素があります。
| 種類 | ソースの中での名前 |
|---|---|
| 未初期化のグローバル変数定義 | g_in_hello_uninit, g_text_uninit, g_large_buf |
| 初期化のあるグローバル変数定義 | g_in_hello, g_text, g_text_arr |
| staticなグローバル変数 | g_static_in_hello |
| staticな未初期化グローバル変数 | g_static_uninit |
| グローバル変数の宣言 | g_in_main |
| 関数の定義 | print_something |
| 関数の宣言 | func_in_main |
次に、many_symbols.cをコンパイルしてみてnmで見てみましょう。 以下みたいな感じです。
arm-linux-gnueabi-gcc -c many_symbols.c
nm many_symbols.o
すると、以下のような種類の出力になっているはずです。
| 種類 | nmでのシンボルの種類 |
|---|---|
| 未初期化のグローバル変数定義 | C |
| 初期化のあるグローバル変数定義 | D |
| staticなグローバル変数 | d |
| staticな未初期化グローバル変数 | b |
| グローバル変数の宣言 | U |
| 関数の定義 | T |
| 関数の宣言 | U |
Tはテキストセクションの事です。dとDはデータセクションの事です。 bはbssセクションという奴です。小文字はstatic、大文字は外からも見える物っぽいですね(私もあまり知らない)。
未初期化のグローバル変数は本来Bになるはずなのですが、C言語の特別扱いによりオブジェクトファイルの段階ではCという特殊なマークがされています。
これがオブジェクトファイルだけの特別な扱いなのは、リンクをしてみると分かります。
main.cとリンクしてみて、a.outをnmで見てみましょう。
arm-linux-gnueabi-gcc many_symbols.c main.c
nm a.out
ちゃんと未初期化のグローバル変数はBになっていると思います。
まとめると、以下のようになっています。
- 初期化ありグローバル変数はデータセクション(d, D)
- 初期化無しグローバル変数はbssセクション(b, B)
- ただしリンクされるまではC扱い
- 関数の定義はテキストセクション(t, T)
- 宣言だけだと未解決シンボル扱い(U)
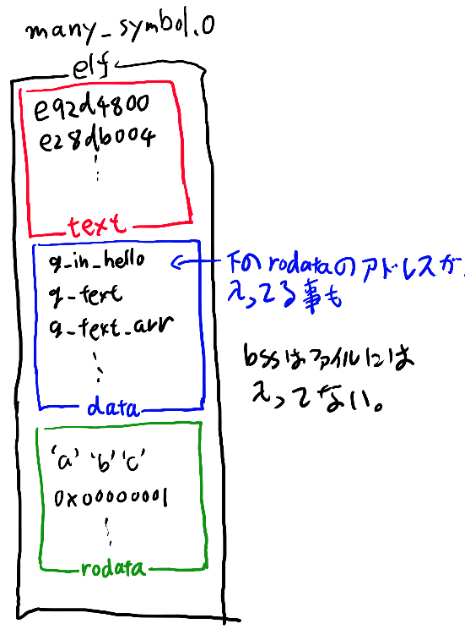
text領域でグローバル変数を参照する時は、data領域の先頭から何番目か、という情報だけでまずは書いておく。 data領域では配列などはそこに実際の値を埋め込んでおくが、ポインタなどの場合は実際のデータはrodataに書いておいて、そこへのアドレスが入っている場合もある。
data領域もrodataも、先頭から何番目か、というインデックスだけで参照する(つまりdataもrodataも0番にロードされるかのようなコードになっている)。
参考リンク
nmのシンボルの種類は公式ドキュメントを見ると書いてあります。https://sourceware.org/binutils/docs/binutils/nm.html
おまけ
many_symbols.cを-Sオプションでアセンブリを吐かせてみると、g_textとg_text_arrの違いが分かるかもしれません。(あとでちゃんと解説します)
elfとリンク
ここまで見てきたオブジェクトファイルやa.outファイルは、どちらもelfというフォーマットになっています。
ここからは、このelfにどういう形で結果が入るのか、というのを意識した方が分かりやすいので、簡単にelfの話をしておきます。
elfとは?
elfとは、実行ファイルやオブジェクトファイルを格納するファイルフォーマットです。 ここまでの作業で生成された、例えば.oファイルはelfファイルだし、a.outもelfファイルです。また、bare metalの時に例えばhello_arm.elfというファイルを一時的に生成していました。あれもelfファイルです。
elfはどういう物か、というと、ざっくりとは「zipファイルみたいなもの」と言えると思う。
zipファイルというのはWindowsのエクスプローラでフォルダを右クリックして圧縮する時のあれの事です。
zipファイルには中に様々なファイルやフォルダが入っていて、中身の種類というのはzipとは独立した概念ですよね。 例えばテキストファイルでもjpegファイルでもmp3ファイルでもzipの中に含める事が出来る。 zipを作った人が知らないへんてこなファイルフォーマットも別にzipに入れる事はできる。
elfもこれと同様で、いろいろなデータを含む事が出来るコンテナのファイルとなっています。 この中にARMの実行バイナリが入っていたりオブジェクトファイルのバイナリが入っていたりします。 elf自体は汎用のフォーマットなので別にARM以外のバイナリが入る事もあります。 また、アイコンや国際化の為のメニューのテキストなどのデータを入れる事もあれば、デバッグ用のソースコードのどこに対応したバイナリかを示す情報を入れたりとかも出来ます。
また、バイナリの他にそれをどこのアドレスにロードしてもらうか、とかの付加情報やシンボルテーブルなども入っています。
さらにobjcopyなどのコマンドで、自分の好きなデータを入れる事も出来たりします。 低レベルでなにかトリッキーな事をやりたい時に便利です。
readelfでオブジェクトファイルを調べる
elfのファイルを調べるにはreadelfというコマンドを使います。 readelfはmanが良く書けているのでmanのページを参照しつつ以下の解説を読んでいけば十分でしょう。readelfのmanページ
なお、readelfはobjdumpと多くの点で役割がかぶっているコマンドで、objdumpでもreadelfでも出来る事は多い。 どっちのコマンドでやるべきなのか?とかはあまり気にせずにググって出てきた方を使っていればよろしい。
さて、上で見てきたmany_symbols.oをreadelfコマンドを使って調べてみましょう。 readelfは大きくオブジェクトファイルを調べるオプションと実行ファイル(a.outとか)を調べるオプション、そして両方で使えるオプションの3つがあります。
まずセクションの情報を見るのは-Sオプションです。
readelf -S many_symbols.o
Nameという所にこのelfファイルに含まれるセクションの情報が載っています。 ここまで説明してきた.text, .data, .bssの他に.rodataなどのデータもあると思います。 また、.symtabなんていうのもありますね。 全部は自分も理解してないので説明は出来ませんが、なんとなく眺めておくと良いと思います。
このセクションの中身を見るには-xのオプションを使います。
例えば.rodataの中を見てみましょう。
$ readelf -x .rodata many_symbols.o
Hex dump of section '.rodata':
0x00000000 61626300 abc.
abc(とそのあとにヌル文字)が入っているのが分かります。 文字列の定数などのデータは.rodataというセクションに入ります。
.textも観てみましょう。
$ readelf -x .text many_symbols.o
Hex dump of section '.text':
NOTE: This section has relocations against it, but these have NOT been applied to this dump.
0x00000000 00482de9 04b08de2 08d04de2 08000be5 .H-.......M.....
0x00000010 08001be5 feffffeb 0c309fe5 003093e5 .........0...0..
0x00000020 0300a0e1 04d04be2 0088bde8 00000000 ......K.........
この中身は見覚えがありますか? objdump -Sと並べるとよりはっきりするでしょう。
$ arm-linux-gnueabi-objdump -S many_symbols.o
many_symbols.o: file format elf32-littlearm
Disassembly of section .text:
00000000 <print_something>:
0: e92d4800 push {fp, lr}
4: e28db004 add fp, sp, #4
8: e24dd008 sub sp, sp, #8
...
例えばe92d4800を、エンディアンを変えて上のreadelfの結果から探してみたりしてみてください。 このように、オブジェクトファイルはelfというフォーマットで保存されていて、 ARMのバイナリ(コード)は.textというセクションに入っています。
.symtabというのはシンボルテーブルだと思います(あんまり知らない)。 これをxしても自分のようなゆとりには解読できませんが、シンボルの情報を表示する専用のオプションがあります。それが-sです(小文字です)。
$ readelf -s many_symbols.o
Symbol table '.symtab' contains 24 entries:
Num: Value Size Type Bind Vis Ndx Name
1: 00000000 0 FILE LOCAL DEFAULT ABS many_symbols.c
...
6: 00000004 4 OBJECT LOCAL DEFAULT 3 g_static_in_hello
7: 00000000 4 OBJECT LOCAL DEFAULT 5 g_static_uninit
...
16: 00000004 4 OBJECT GLOBAL DEFAULT COM g_in_hello_uninit
17: 00000000 4 OBJECT GLOBAL DEFAULT 3 g_in_hello
18: 00000008 4 OBJECT GLOBAL DEFAULT 3 g_text
21: 00000004 0x400000 OBJECT GLOBAL DEFAULT COM g_large_buf
22: 00000000 48 FUNC GLOBAL DEFAULT 1 print_something
23: 00000000 0 NOTYPE GLOBAL DEFAULT UND func_in_main
24: 00000000 0 NOTYPE GLOBAL DEFAULT UND g_in_main
ごちゃごちゃ出ますが必要そうなのだけ抜粋しました。 一行目がファイル名。
Ndxという所に種類が入っているようで、初期化してないグローバル変数はCOM、未解決のシンボルはUNDと書いてありますね。COMはcommonの略。 また、print_somethingはサイズの所にARMのバイナリの大きさが書いてあったりもします。
1とか3とか5の意味は知りませんが、こんな情報がオブジェクトファイル(たぶん.symtab)に入ってて、nmとかはこういう情報を出力しているのがなんとなく分かります。
g_large_bufのサイズの所を見てください。これは配列の大きさですね。4バイトのintが、1024*1024だけある。
readelfで実行バイナリを調べる
ついでにa.outも観ておきましょう。 まず、readelf -Sの結果をなんとなく眺めます。
なんかいっぱい出てきますね。 readelf -xで.textを見てobjdumpと比べたりもしてみてください。
さらにa.outでは、readelf -lで少し違った情報を得る事が出来ます。
$ readelf -l a.out
...
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
...
LOAD 0x000000 0x00010000 0x00010000 0x004f8 0x004f8 R E 0x10000
LOAD 0x000f10 0x00020f10 0x00020f10 0x0012c 0x0013c RW 0x10000
...
このバイナリを、実行する時はどこに「ロード」するか、というのが書いてあります。
ARMのLinuxでは、0x00010000というアドレスにtext領域をロードするのが一般的なようですね。 なおx86だと0x400000が多い気がする。
Flgという所を見ると、R Eというのはread onlyで実行可能(executable)、RWは読み書き両方出来る、という意味です。
OSがプログラムを実行する時には、この辺の情報に従ってメモリ上にそれぞれのバイナリをロードした後に、コードの先頭にr15を移動させます。
PIEとASLR
このページで解説しているロードは、アドレスのrandomizationという物がない前提です。
一方で最近のOSではセキュリティの観点から、実際にロードするアドレスというのはランダムに決めるという機構が何かしらの形で実装されています。Linuxの場合、これをASLRといい、それに対応した実行バイナリはPIEと呼ばれるらしいです。
ローダーを勉強するならASLR回りの事を理解すべきですが、
自分がそもそも詳しくない事と、C言語の勉強という観点では決まったアドレスにロードするという原始的な仕組みで理解しておく方が良い事は多いと思うので、
このシリーズではASLRなんて物は無いかのように説明をします。
ですが、OSやバイナリ、低レベルプログラミングなどはいつかはちゃんと勉強した方が良いです。自分も最近の知識にアップデートしないとなぁ…
実行バイナリのロードの基本
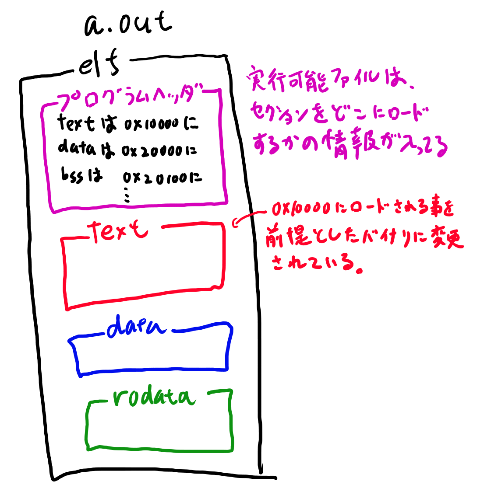
OSというのは、実行可能ファイルからプロセスを作り、実行します。 実行可能ファイルには、実行を開始する前にtext, data, bss, rodataなどをどこにロードしておいて欲しいか、という事が書かれていて、OSはそれに従ってメモリの中身を設定して実行を開始します。
具体的にはtextをメモリの0x00010000に配置し、dataやbssなどを0x00020000に配置します。
text領域にあるARMバイナリからすると、グローバル変数などはメモリ上の決まったアドレスにある、という前提でldrなどのバイナリが書かれています。 それは例えばグローバル変数が0x00020000から順番に置かれる、という前提で、ここからのアドレスを元にコードは書かれています。
例えばグローバル変数のg_var1, g_var2, g_var3がそれぞれ順番に4バイトずつで置かれているとすると、g_var1をldrする時は[0x00020000+0]、g_var2の場合は[0x00020000+4], g_varの時は[0x00020000+8]をldrしたりします。
text領域のARMのバイナリは、このように特定の配置にグローバル変数が設定されていると信じてコードを書いておきます。その通りに設定するのはOSの仕事となります。
text領域の中身がそういう風になるのはリンカの仕事です。
ロードの視点から見たリンカの仕事
さて、上で述べたようにロードは行われるので、リンカの仕事はそれで問題無いように実行可能ファイルを準備する事、となります。
オブジェクトファイルの時点では、自身の参照するグローバル変数やコードが最終的にどこのアドレスに置かれるかは分かりません。 テキスト領域などは複数のオブジェクトファイルに存在していて、リンクの時に初めてくっつけた時の順番が決まるからです。 オブジェクトファイルのコードの時点では、自分のアドレスを知る事は出来ません。
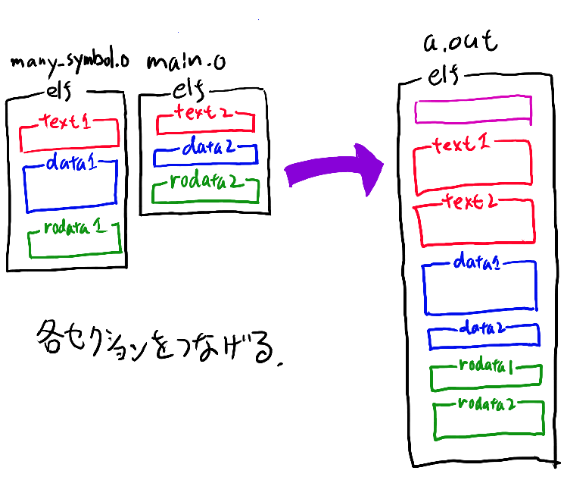
そこでオブジェクトファイルの時点では、textセクションもdataセクションもbssセクションも全部先頭が0番目になるようにロードされる、と仮定してバイナリを生成しておきます。 こうしておいて、実際にロードされるアドレスが決まったら、そのアドレスにバイナリの中身を変更していきます。 これもリンカの仕事です。
例えばtext2のセクションの中身を書き換える時は、text2, data2, rodata2などがどこにロードされるかの情報を使ってtext2の中のバイナリを書き換えていきます。 例えば「data2の先頭のアドレス」はdataセクションがロードされる先頭のアドレスに、さらに「data1のサイズ」を足した物になっています。 この情報を使ってtext2のグローバル変数の参照を書き換える訳です。
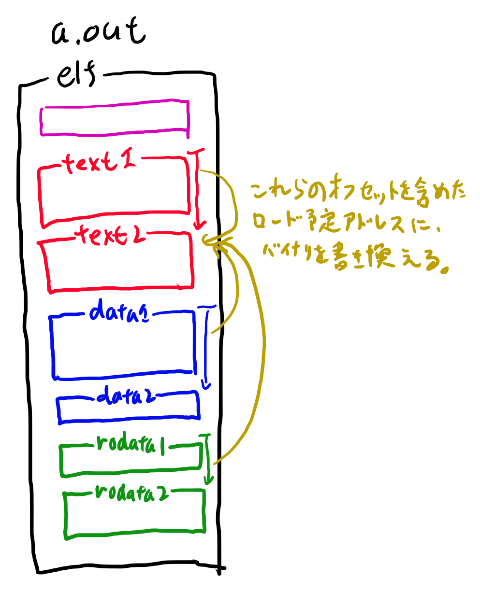
text2のアドレス更新の模式図
この時についでに他のファイルのシンボルを参照している命令なども解決します。
これは第二回で、簡易アセンブラでラベルの解決をした時と似た処理になります。 線形リストで解決が必要な所を覚えておいてあとからbなどを書き直したと思いますが、あれと同じ感じで、テーブルに書き換えが必要な部分を書いておいて、最後にそのテーブルをなめてバイナリのオフセットとかを表している部分を解決していきます。
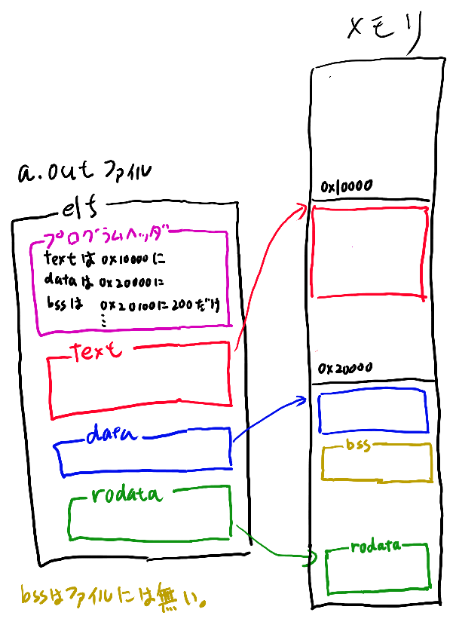
dataとbssの違いを考える
実行可能バイナリが実行される時は、メモリにロードされる、という話をしました。 その時に、bssというのは初期化されない変数なので、実際にはメモリを割り当てさえしてやれば、中身を何かの値にする必要はありません。(なおC言語はこの場合ゼロとなる、という決まりになってるのでbssは中身が全部ゼロに初期化されます。これは全領域を同じ値で埋めるのでサイズさえ分かっていれば行なえます)
メモリ上ではちゃんとその範囲を用意してやる必要はあるのですが、elfファイルにはその領域を用意してやる必要は無い。 例えば
int g_large_buf[1024*1024];
という未初期化の配列があったとすると、ファイルに1024*1024だけ0を詰めておく、というのは、無駄な気がします。 別にファイルに入れておかなくても、サイズさえ分かってればロードする時に1024*1024の、全部0で埋めた領域だけ用意してやれば良い。 という事でelfのファイルにはbssの領域は要らない、という事になります。
これがbssとdataという二つのセクションがある理由です。
dataは初期の値をどうせ埋めておく必要があるので、実際にロードされるのと同じ順番で、初期の値が詰め込まれています。 ロードする時はファイルの該当するセクションを、メモリの特定のアドレスにロードする必要があります。
hello_arm.binをどうやって作っていたのか見直してみる
ここで、第二回でhello_arm.binをどうやって作っていたのかを見直してみましょう。 なお、これはOS無しの環境で実行するバイナリなので、ローダーとかがありません。 だから最後のbinファイルを直接メモリのどこかのアドレスにロードして実行するだけで、セクションとかはありません。
まず、以下のようなコマンドを実行していました。
$ arm-none-eabi-as hello_arm.s -o hello_arm.o
$ arm-none-eabi-ld hello_arm.o -Ttext 0x00010000 -o hello_arm.elf
$ arm-none-eabi-objcopy hello_arm.elf -O binary hello_arm.bin
一行目は.sというアセンブリのファイルからオブジェクトファイルを作っています。
二行目のldでリンクを行って、実行可能バイナリであるhello_arm.elfというファイルを作っています。 この時引数で -Ttextというオプションを指定して、テキスト領域を0x00010000から始める、という風なバイナリになるように、リンカに指定しています。 このバイナリではセクションは一つしか無いので分かれている必要は無いし、結果もbinに直接吐けば良いはずですが、使っているldなどのコマンドがもっと一般的なケースを基本に動く為、textセクションしか無いバイナリ、という事にして生成している訳です。
なお、hello_arm.sではグローバル変数などは使っていないのでdataやbssという概念は必要ありません。(必要な場合はこれらを適切にロードする必要があるのでqemuにコマンド一つで実行、とはいかない)
そして最後のobjcopyでこのelfファイルから、textセクションの部分をバイナリとして生で取り出してhello_arm.binというファイルに書き出しています。 hello_arm.binはelfファイルでは無く、単純にARMのバイナリが書かれているだけです。
これではグローバル変数などを使ったコードは動きませんが、フルアセンブリで手で書いていればこれで十分です。
アセンブリ言語におけるセクション
第二回で我らが作った簡易アセンブラは最終バイナリを作っていましたが、実際のアセンブラはオブジェクトファイルを作ります。 最終バイナリを作るのはリンカの仕事でアセンブラとは別のプログラムです。
アセンブラとは、本来はアセンブリ言語からオブジェクトファイルを作るものです。 そしてオブジェクトファイルとは、ここまで見てきたように、おおざっぱには
- ARMのバイナリであるtextセクション
- 初期化のあるグローバル変数を並べてあるdataセクション
- シンボルテーブル
などの集まりをelfのフォーマットに保存した物です。
これらをアセンブラが作る為には、アセンブリ言語でこれらを指示する必要があります。 これらの指示は疑似命令として実装されています。
ARMのアセンブリ言語では、セクションを表すのに、疑似命令の.textとか.dataなどを使います。 .textと書いてある行があると、そこから先はtextセクションに置く、という前提で処理され、.dataと書いてある行があるとそこから先はdataセクションに置くという前提で処理されます。
C言語とセクションの関係がアセンブリの世界ではどう表現されているかを見る為に、many_symbols.cをコンパイルしてアセンブリを見てみましょう。
arm-linux-gnueabi-gcc -S many_symbols.c
こうして生成されるmany_symbols.sを見ると(ごちゃごちゃとなんだかわからない物がいっぱい書かれていますが、注意して探してみると).dataと.textというのが何か所か出てきているのが見つかると思います。
また、.commというので未初期化変数を指定しているのも分かります。
なお、アセンブラは.textと書かれている場所が何か所か出てきたら、全部つなげて一つのtextセクションとして出力します。 .textと.dataはアセンブリ言語の上では隣の行であっても実際は遠くに配置されるので注意が必要です。
コンパイラの生成するアセンブリは付加情報としていろいろな物を吐くので、全部を理解する必要は無いと思います(少なくとも自分は知らないのも結構ある)が、ここまでの話くらいの理解は持っておく方が良いでしょう。
リンカについてのサイト
最後に自分が良く書けているなぁ、と思ったサイトを紹介しておきます。
この位知っておけばいいだろう、という踏み込み具合がちょうどよくて分かりやすいページだと思います。 ダイナミックリンクライブラリやC++も入っていたり、私が説明した事の先を知るのにちょうど良いくらいのページです。
04 コンパイラの吐くアセンブリをいろいろ見てみる
ここからは、コンパイラの吐くアセンブリをいろいろとみてみる事で、C言語の理解を深めていきたいと思います。 C言語で分からない事があったらアセンブリを読んでみる、は強力な調査方法です。
コンパイルというと普通はアセンブルまで含めてしまうのが一般的ですが、ここではアセンブリを吐くまでをコンパイル、と呼ぶ事にします(本来の用語の使い方だと思います)。
コンパイルの手順
コンパイルする時のコンパイラとしてはgccとclangの二つの選択肢があります。 基本的にはclangで解説をしていきたいのですが、何故clangで解説したいのかを理解する為に、まずは両者の生成するアセンブリコードを比較してみましょう。
sources/casm_link/04_c_sources/hello_puts.c
をコンパイルしてみる事にします。
gccでコンパイルしてみる
以下のコマンドでアセンブリを生成する事が出来ます。 これまでもなんどかやっていますね。
arm-none-eabi-gcc -O0 -fomit-frame-pointer hello_puts.c -S -o hello_puts_gcc.s
生成されるコードが一番簡単になるように、-fomit-frame-pointerつけましたが、これはあっても無くても良いです。
こうしてhello_puts_gcc.sというファイルにアセンブリが出力されるので見てみてください。 いろいろ付加情報が生成されますが、必要な所だけ見ていくのがこの手の作業のコツです。 例えばprint_somethingのあたりだけ見てみると以下のようになっていると思います。
print_something:
str lr, [sp, #-4]!
sub sp, sp, #12
str r0, [sp, #4]
ldr r0, [sp, #4]
bl puts
nop
add sp, sp, #12
@ sp needed
ldr lr, [sp], #4
bx lr
ちょっと第二回で説明してない機能もありますが、頑張ればだいたい何やってるのかは理解出来るとは思います。
別にこれを解読していってもいいのですが、その前にclangの生成するコードを見てみましょう。
clangでコンパイルしてみる
clangの場合も、正当派なやり方では、ARM向けのクロスコンパイラを用意する必要があります。 apt-getでは取れなさそうで自分でビルドする必要がありそうです(あまり詳しくないのでどこかに定番のビルド済みバイナリがあるのかもしれませんが)。
ですが、ターゲット環境向けのgccがあれば、このgccをバックエンドとして使う、という抜け道があります。
具体的には以下のような手順です。
clang -m32 -emit-llvm hello_puts.c -c -o hello_puts.bc
llc -march=arm hello_puts.bc -o hello_puts_clang.s
clangの所でbits/libc-header-start.hが無いと言われたら、以下で32bit用のヘッダファイルを入れて下さい。
sudo apt-get install gcc-multilib-arm-linux-gnueabi
(追記: sudo apt-get install gcc-multilib だったかもしれない。ちょっとうろ覚えなので両方試してみてください)
llcの所でllvmが無いぞ、とか言われたらこちらもapt-get installしてください。
幾つかignoring processorというメッセージが出ますが、ちゃんとアセンブリは生成されると思います。
これで生成されるprint_somethingのコードが以下。
print_something:
.fnstart
@ %bb.0:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
str r0, [sp]
ldr r0, [sp]
bl puts
mov sp, r11
pop {r11, lr}
mov pc, lr
pushとpopが使われているのが、stmdbとldmiaに慣れた身にはやや辛いですが、コード的には大分こちらの方が手で書くアセンブリに近いと思います。 という事で以後はclangの方のアセンブリを読んでいきたい。
そこで上記の二行のコマンドを実行するmycomp.shというシェルスクリプトを用意しました。 良かったら使ってみてください。
読む時のtips
初めてコンパイラの生成するアセンブリを読む時の、簡単なヒントを。
- sp, lr, pcはそれぞれr13, r14, r15の事。(http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.kui0097a/armcc_cihigdfh.htm)
- 疑似命令はasのドキュメントを読むのが良い(ただ要ら無さそうなのは適当に推測して調べないのも大切) (https://sourceware.org/binutils/docs-2.27/as/Pseudo-Ops.html#Pseudo-Ops)
では以下ではclangの生成するアセンブリを読んでいきましょう。
関数の基本と引数と戻り値
あとは自力でアセンブリを読んでいけ、でもいいと思うし実際読めると思うんですが、 最初は慣れる為にもちょっと解説をしていきましょう。
C言語ではプログラムは関数を構成単位に書かれる事が多いと思います。 そして関数をアセンブリにする時には似たようなパターンが繰り返し現れるので、良く表れるパターンに慣れておくと、調べたい事の本体に集中出来るようになって、アセンブリを読むコストが減ります。
引数一つ、戻り値無しの関数呼び出し
まずは一番簡単な関数のケースとして、引数が一つだけの関数呼び出しの例として、 先ほどのhello_puts.cのprint_somethingのコードを読んでみましょう。
C言語では以下のようなコードが、
void print_something(char *str) {
puts(str);
}
アセンブリではこうなっています。
print_something:
.fnstart
@ %bb.0:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
str r0, [sp]
ldr r0, [sp]
bl puts
mov sp, r11
pop {r11, lr}
mov pc, lr
順番に見ていきましょう。 まず.fnstartという疑似命令は何なのか私は知りません。
そして関数では、「その関数で使う予定のレジスタは関数を抜ける前に元に戻す」という約束になっています。これは第二回のスタックを使って関数を作る話と一緒ですね。
だからだいたい
- 関数の先頭で、その関数で使う予定のレジスタの「元の値」をスタックにpush
- 関数の最後で、使ったレジスタを「元の値」に戻す為スタックからpop
という処理が行われる事になります。 また、pushとpopはr13(つまりsp)に対して行われる為、r13だけはpushで保存してpopで元に戻す、とはいきません。
その辺の事情を考えて関数の前半を見ると以下のようになっています。
push {r11, lr}
mov r11, sp
r11とlrを保存しています。lrはblした時に勝手に現在のr15が書かれるレジスタの事でした。だからこの関数の呼び出し元のアドレスが入っている訳です。
そしてprint_somethingはputsを呼び出すので、この時にbl命令が使われてlrが上書きされてしまうので、bl呼び出すをする前に元の値を保存しておく必要があります。 だから最初に保存している訳ですね。
次のr11にはspを保存しています。これはspはpushでは保存しづらいので(r13のwritebackだった事を思い出してください)、レジスタに代入しておく訳です。
関数の最後の所ではこの値を元に戻してreturn相当の事をしているはずです。 見てみましょう。
mov sp, r11
pop {r11, lr}
mov pc, lr
まずspを戻し、次にr11とlrを戻しています。 これでprint_somethingの中で使ったレジスタは全部元の値に戻りました。
最後にpcにlrを代入しています。これで呼び出し元に戻るのでした。
以上で関数の最後にやってる事も理解出来たと思います。 C言語のコンパイル結果を読む時のコツとしては、この関数の先頭の処理と最後の処理をそれ以外の所とは分離して読む事です。 最初と最後はたぶん似たような事やってるんだな、と読み飛ばしておいて、必要になったらちょっと確認する、くらいが良い。
そうして本題の所を読むと以下のようなコードになっています。
sub sp, sp, #8
str r0, [sp]
ldr r0, [sp]
bl puts
スタックをさらに8バイト広げてr0を詰めて、その詰めた値をr0に読みだしているように見えます。 たぶんこの上三行は意味が無い処理だと思う(もし何か意味があったら教えてください)。 コンパイラはいろいろな事情で、簡単なケースでは意味が無いコードを生成するのは良くある事なので、動作が理解出来ていて意味が無い、と感じた時は気にせずに先に進むのが良いと思います。
そして唯一の意味があるのは以下の行。
bl puts
C言語の関数を呼ぶ時は
- r0に引数を入れて
- 関数名のラベルにbl
するのが関数呼び出しなのでした。 今回のr0はそもそもにprint_somethingの引数がr0なので、そのまま渡せばよい。 だから関数名のラベルにblすれば良い、という事でputsにblしている訳です。
だから元のアセンブリは、
print_something:
.fnstart
@ %bb.0:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
str r0, [sp]
ldr r0, [sp]
bl puts
mov sp, r11
pop {r11, lr}
mov pc, lr
以下のように三つに分けて考えると良い。
まず使う予定の物を使う前に保存する所
print_something:
.fnstart
@ %bb.0:
push {r11, lr}
mov r11, sp
本体
sub sp, sp, #8
str r0, [sp]
ldr r0, [sp]
bl puts
後始末(使ったレジスタを元に戻してreturn)
mov sp, r11
pop {r11, lr}
mov pc, lr
特に機械の生成するアセンブリはこのような意味に分けて分かりやすく、みたいなのが無く全部だーっと出てしまうので、頭の中で意識的にブロックのような物に分けて読んでいくようにしましょう。
結果を返す場合とメモリレイアウト
次にもうちょっと普通の関数っぽい奴を読んでみましょう。
題材としてはsum.cです。 これをコンパイルしてアセンブリを読んでみましょう。
まずcのソースコードを読みます。
int sum(int begin, int end) {
int res = 0;
for(int i = begin; i <= end; i++) {
res+=i;
}
return res;
}
ちょっと普通っぽい関数になりました。 注目するのは
- 中で関数は呼び出していない
- 引数が二つにローカル変数一つ
- 最後に結果を返している
という所です。
ではmycomp.shを使って、アセンブリを表示してみましょう。
sum:
.fnstart
@ %bb.0:
sub sp, sp, #16
str r0, [sp, #12]
str r1, [sp, #8]
mov r0, #0
str r0, [sp, #4]
ldr r0, [sp, #12]
str r0, [sp]
b .LBB0_1
.LBB0_1: @ =>This Inner Loop Header: Depth=1
ldr r0, [sp]
ldr r1, [sp, #8]
cmp r0, r1
bgt .LBB0_4
b .LBB0_2
.LBB0_2: @ in Loop: Header=BB0_1 Depth=1
ldr r0, [sp]
ldr r1, [sp, #4]
add r0, r1, r0
str r0, [sp, #4]
b .LBB0_3
.LBB0_3: @ in Loop: Header=BB0_1 Depth=1
ldr r0, [sp]
add r0, r0, #1
str r0, [sp]
b .LBB0_1
.LBB0_4:
ldr r0, [sp, #4]
add sp, sp, #16
mov pc, lr
この位の長さになるとちょっと辛いですね。
長いアセンブリを読むのは辛いので、なるべく必要な所以外は読まないように頑張るのが良いのですが、今回は勉強目的なのでまぁまぁ真面目に読んでいきます。
まずは最初の所。
sum:
.fnstart
@ %bb.0:
sub sp, sp, #16
今回は退避するレジスタがr0くらいなのでpushとかは使ってないようです。 最初にspを16だけ引いている。これは何をやっているか、という事を考えるには、第二回のスタック回りの話を思い出す必要があります。
良い機会なので、ここまでの話を総合して軽くプロセスのメモリ配置の基本の話をしておきます。
まず、実行可能バイナリをOSがロードする時は、以下のような感じにセットアップします(最近の事情はもうちょっと複雑ですが、C言語の理解としてはこの位で十分でしょう)。
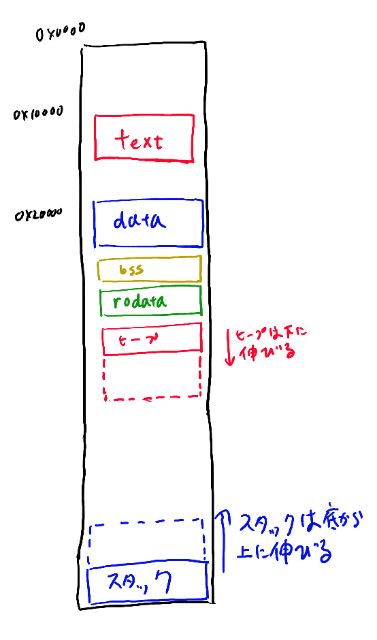
まずtext, data, bss, rodataなどをメモリ上の特定のアドレスにロードします。 ここまでは実行可能ファイルを読めばどれだけのサイズが必要かが全部決まる所です。
その次に、ヒープの領域を用意します。ヒープというのはプログラムが実行していく過程でどんどん増やしていく領域です。 プログラマの視点からするとmallocするたびに下に伸びていく、と思っておくとだいたいはOK。
そしてスタックは、図の上では一番下の所から始めて、必要に応じて上に伸ばしていきます。 ARMではC言語の関数はstmdbを使う、という約束だったので、db、つまり保存する前にdecrementする、つまり4引きます。引くというのは図で上に伸びるという意味になります。
上ってどっちやねん!?
スタックが伸びる方向は、例えば0x80000000から、0x7ffffffc、0x7ffffff8、とだんだんと低いアドレスに進んでいく訳ですが、これは上なのか、下なのか、というのは結構論争があります。
数字が大きくなる方が上と思えばスタックは「下に伸びる」というのが正しい。
一方で図で描く時は普通0を上にするので、図の上では上に伸びていく。
この辺は実際の動きを理解していればどうでも良いのですが、
どうでも良いがゆえにいつまでたっても結論が出ない話です。
私はスタックは上に伸びる派として日々活動しています。(第一回では下に伸ばしてた気もするけれど)
それを踏まえて、sumの最初の処理をもう一度見てみましょう。
sum:
.fnstart
@ %bb.0:
sub sp, sp, #16
spを16引いている、という事は、スタックを上に変数4つ分くらい伸ばしている、という事になります。 スタックはいつも上側はまだ使われていない領域なので、上にずらせば間の所は自由に使って良いという事になります。
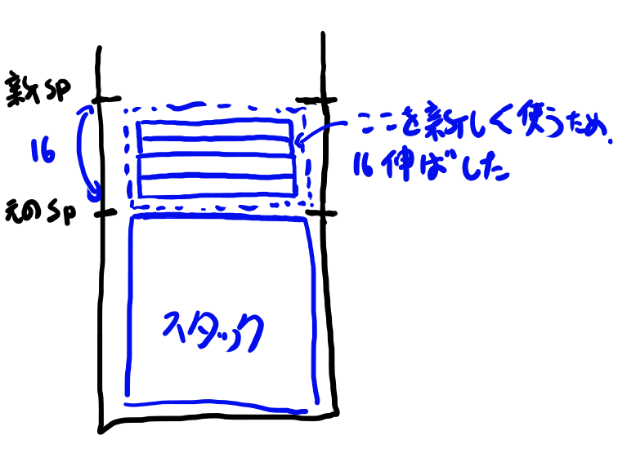
その開けたスタックに何を入れているか、というのがその次のブロックになります。 以下のようなコードです。
str r0, [sp, #12]
str r1, [sp, #8]
mov r0, #0
str r0, [sp, #4]
ldr r0, [sp, #12]
str r0, [sp]
元のスタックポインタをorigin_spと便宜上呼ぶとすると、 spはorigin_sp-16です。
そこで一行目を見ると、sp+12にr0を入れる、となっています。 sp+12というのはorigin_sp-4という事になります。 つまり元のspの一つ上の箱に、r0を入れる、という意味です。
r1はorigin_spの二つ上の箱に入れる。
r0に0を入れて、origin_spの3つ上の箱に入れています。 さらにorigin_spの4つ上の箱にも何を入れていますね。
元のCコードとの対応で行くと、以下のコードのうち
int sum(int begin, int end) {
int res = 0;
for(int i = begin; ...
4つの箱はbegin, end, res, int iの4つの変数に対応しています。
ちょっと自分で以下の問の答えを考えてみてください。
- [sp]には何をstrしたのか?C言語の言葉で答えよ(beginとかresとかの変数名を答えて下さい)
- [sp], [sp, #4], [sp, #8], [sp, #12]はC言語の変数名ではそれぞれ何か?
この後にはfor文の最初のループ条件の所のブロックと、その中身のブロックの処理があります。 ここの解説は省略しますが、自分で頑張って読んでみてください。 for文はいつもこのパターンのアセンブリになるので、一度慣れておくと次から読む時には比較的楽に読めるようになります。
そして最後は以下になってます。
ldr r0, [sp, #4]
add sp, sp, #16
mov pc, lr
まずr0にreturnする値を入れる。 そしてspに16を足して、元の値に戻している(一時的に伸ばしたスタックを縮めて元のサイズにしている)。 そして最後にpcにlrを入れてreturnしています。
という事で簡単にまとめると以下のようになります。
- spから16とか引くと、まだ使われてないスタックの領域を確保した事になってローカル変数とかに使える
- 最後に元に戻す時はspに足せばよい
- 関数から値をreturnする時はr0に結果を入れる
これで基本的な解説は終わりです。
C言語の関数まとめ
以上をまとめると、C言語の関数というのは以下のような構成のアセンブリになります。
- 必要ならスタックにレジスタの値を保存していく(push)
- 必要ならspから幾つか数字を引く事で上に伸ばしてローカル変数の分の領域を用意
- いろいろ作業
- 1と2の反対をやる
- r0に返す値を入れる
- mov r15 r14して呼び出し元に戻る
3だけが関数に特有の処理となるので、慣れてきたら1,2と4, 5, 6は読み飛ばして3だけに集中するようにしましょう。
いろいろ見てみよう
ここまで理解出来たら、あとは好きに気になるC言語の機能を簡単な関数で書いてみて、コンパイルしてアセンブリを読む、という事をやっていけば、C言語で分からない所はだいたい無くせると思います。
また、Cでプログラムをしてて良く分からない挙動で悩んだ時も小さなコードで同じ事をやる関数を作ってみてアセンブリを吐かせて読んでみれば、なぜ動かないのかはだいたい理解出来るはずです。 実際Cのプログラマの多くは普段からそうやって良く分からない言語の機能や振る舞いを調べています。
という事であとは自由に見ていけば良いのですが、どういう風にやっていくのか、 の具体例として、いくつか面白い例を簡単に紹介しておきましょう。
引数がいっぱいある場合
さて、引数をr0, r1, と順番に使っていくのは分かったのですが、いっぱいあったらレジスタが足りなくなるはずです。 仕様書をちゃんと確認すればいくつまで、という制限も書いてあるはずですが、少なくともr13はスタックポインタなので使えないから、このやり方では13個の引数を渡せば間違いなく限界は超えているはず。
という事で13個の引数を持つ関数をコンパイルしてみましょう。
sources/casm_link/04_c_sources/many_args.c
になります。
Cのソースコードは以下のようになっています。
int many_sum(int a1, int a2, int a3, int a4,
int a5, int a6, int a7, int a8, int a9,
int a10, int a11, int a12, int a13) {
return 2*(a1+a2+a3+a4+a5+a6+a7+a8+a9+a10+a11+a12+a13);
}
13個の引数を足して、なんとなく2倍してみました。2倍する事に特に意味はありません。
呼ぶ側は以下のようになっています。
int main() {
int res = many_sum(13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1);
printf("result is %d\n", res);
return 0;
}
せっかくなので順番を逆順に、13から始めて12, 11とだんだん減らしていく順番にしました。
これをmycomp.shを使ってアセンブリを生成してみましょう。
アセンブリはぶわーっといっぱい出てきて知らない命令なども多くあると思います。 この手の物を読む時のコツは、「なるべく必要な所だけを読む」という事です。 その為には必要な所を「探す」という技術が必要になってきます。
以下簡単にヒントを出すので自分で読んで行ってみてください。
まずmany_sumを呼んでる側、つまりmainの方から見てみましょう。 どうやって引数を渡していますか? この辺まで来れば解説は要らないと思うので、自分で読んでみてください。
a1からa4まではレジスタで渡しているようです。 a5からa13まではどう渡していますか?図で描いてみてください。
次にmany_sumの方のアセンブリリストを見ます。 そこでは4つ箱を作っていますね。 そこには何を入れているでしょうか?
many_sumと前のmain側の両方でスタックに何を入れたのか、を、一つの図に図示してみてください。
doubleを渡すとどうなるか?
ファイルを分けるのが面倒になってきたので以下のファイルにまとめて書いてみました。
sources/casm_link/04_c_sources/various_args.c
doubleというのはどういう物なのか、軽く見てみましょう。 まずはmain_double_addの方を見ると、何かわからない数字を入れていますね。
浮動小数点のコードを読む時は、実際の値を知るのは結構難しい。 ただ、8バイトで一つの変数を表している事に着目して、どこがdoubleの変数を表しているかを追っていくと良いと思います。
構造体の実体を渡すとどうなるか
以下のソースで、
sources/casm_link/04_c_sources/various_args.c
main_struct_bodyとmain_struct_pointerのコードを比較してみてください。 構造体に詰める所は両者同じですが、そのあとが大きく違うと思います。
main_struct_bodyでは何をやっているのでしょうか?struct_arg関数側も見てみてください。 struct_pointer_arg関数とはどう違うでしょうか?
この時、main_struct_bodyでは、
struct ManyField st;
というローカル変数の為にスタックにプッシュしている、いわばmain_struct_body用のスタックフレームの操作と、 次のstruct_argに渡す為の引数の為の操作があると思うので、 この二つを区別する事を意識して、struct_argに渡す方がどうなっているかを読み取ってみてください。
ポインタのプラプラについて
sources/casm_link/04_c_sources/pointer_array.c
ここで、intarrayとstructArrayでは、同じptr++でも生成されるコードが違っています。 iterate_array_ptr()とiterate_struct_array_ptr()を比較しましょう。
この手のアセンブリを生成させて読む時のコツとして、生成させるアセンブリがなるべく目的の所だけになるようにする、というのがあります。 例えばprintfは複数の引数をとるのでレジスタ回りの操作が多くなって読みにくくなる。
だからこのコードのようにprint_oneなど、引数一つの目的の出力だけさせる関数を別に作って、これを呼ぶようにすると生成されるアセンブリをシンプルに出来ます。
また、main関数にいっぱいずらずら書くと読みにくいので、目的の事だけする関数をうまく定義してそれを呼ぶようにします。
関数はアセンブリでもラベルで簡単に識別出来るので、調べやすいアセンブリを作る時には、狙ったアセンブリだけを含んだ関数を作るように意識しましょう。
sizeofがどうなるか
sources/casm_link/04_c_sources/sizeof.c
sizeofは静的に分かるサイズを返しているだけです。 静的に分かる、というのは、アセンブリの時には定数になっている、という意味です。
C99からは可変長配列というのが入っています。この場合をvar_arrayという関数で試してみました。 この場合は定数にはなってませんが、引数を足したり引いたりといった単純な演算で求めていて関数呼び出しなどはしていない事が分かります(なお自分は計算は全部は追ってません)。
文字列の配列とポインタの違い
C言語は文字配列と文字列ポインタが、凄く役割は似ているのに結構違う事で有名です。 これはアセンブリで見ないと分からない所ですが、ここまで来るとちゃんと理解出来ます。
sources/casm_link/04_c_sources/string.c
まずはstring_arrayが実際にascizのラベルになっているのに対し、 string_ptrが.L.strへのアドレスのポインタになっている事を確認してください。
また、string_arrayのascizがdataセクションなのに対し、.L.strはrodataになっている事も確認してください。
次に、一見同じ結果を返しているprint_string_arrayとprint_string_ptrですが、アセンブリでは一回ldrが多い事を確認してください。 どうしてこの違いが生まれるか、分かりますか?
スタックウォークしてみよう
C言語では、スタックの呼び出し元というのを知る方法はありませんが、アセンブリの世界の情報を駆使すれば出来る事が知られています。 これはクラッシュした時のスタックトレースを表示したり、メモリリークを起こしているmallocを呼び出している関数を特定したりGCを実装するのに便利です。
ただしアセンブリの実装に激しく依存する方法なので、移植性はありません。 ここではARMのclang向けの方法を調べてみましょう。
このシリーズの最後の課題となりますが、最後にふさわしい難しさで、C言語とアセンブリの間を行ったり来たりしないと実装出来ないと思います。
ちょっと手ごわいので順番に見ていきます。
前準備
今回は、以下のファイルでやっていく事にします。
sources/casm_link/04_c_sources/stack_walk.c
今回の機能は生成されるアセンブリに依存する為、実行バイナリをちゃんとclangのアセンブリから作って試す事にします。
以下のコマンドで試してみてください(qemu実行まで一行にしてしまってもいいです)
./mycomp.sh stack_walk.c && arm-linux-gnueabi-gcc stack_walk.s
qemu-arm -L /usr/arm-linux-gnueabi ./a.out
やりたい事はfunc3を直して、func2のローカル変数a3をprintfで出力する事です。
今回の奴はかなり難しいので、答えも用意しておきます。意味が分からなかったらカンニングしてみてください。
sources/casm_link/04_c_sources/stack_walk_answer.c
まずはCのコードを読む
まずはCのコードを読んでみましょう。 大して意味の無いコードですが、基本的には、
- main
- func1
- func2
- func3
という順番に呼び出されています。 func3は「mainの中から呼び出されたfunc1から呼び出されたfunc2から」呼び出されています。
この時に、func3からfunc2のローカル変数を覗く、という事をやってみましょう。
呼び出し回りのアセンブリを読む
アセンブリを読んでみましょう。といっても関数呼び出しのあたりと、呼ばれた関数の先頭あたりを追っていきます。
具体的には以下のようになっているでしょう。(疑似命令とかコメントは削除してます)。
main:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
...
bl func1
func1:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
...
bl func2
func2:
push {r11, lr}
mov r11, sp
sub sp, sp, #16
...
bl func3
func3:
sub sp, sp, #4
関数はだいたい
- r11とlrをpushする
- その時点でのspをr11に入れる
- ローカル変数分、spを引く
という処理で始まります。 pushした時点でのr11は、前の関数のr11だ、という事がポイントです。
このr11は前の関数の、ローカル変数用に引く前のspが入っている事になります。 図にすると以下みたいな感じになっています。
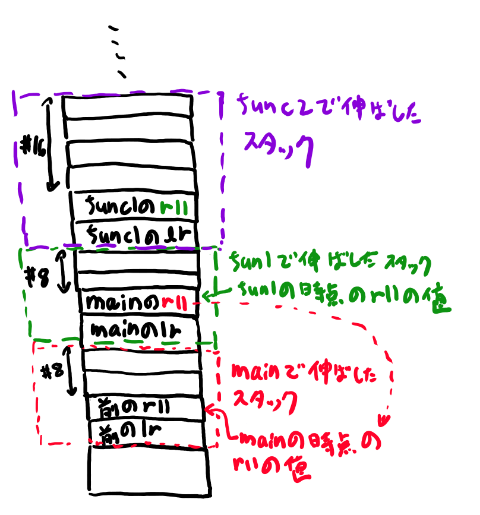
mainのr11は、main関数の中ではスタックに入れられず、そこから呼び出されたfunc1でスタックに入れられる事に注意してください。
いつも各関数の中では、最初に「前の関数の」r11とlrをスタックにpushする事から始まります。 そしてr11をこの新しく詰めた所のアドレスになるようにしています。 r11の中身が、前のr11の値が入っているアドレスになっているので、どっちのアドレスかややこしくなっていますが、頑張って読み解いてみてください。 スタックに入る前のr11の値と、それをスタックに入れた物を区別して読むのがコツです。
なお呼び出し元の関数が何なのかを知りたい時は、lrに呼び出し元のtext領域のアドレスが入っています。 この値がなんの関数なのかはリンク時にmapファイルというのを吐かせると分かりますが、解説はしません(必要になったら調べてみてください。また、デバッガ向けにmapファイルよりも詳細な情報が埋め込まれている事も良くあります)。
辿り方
さて、スタックを辿るにはスタックポインタをC言語の世界で得る必要があります。 C言語の世界でなんとかスタックポインタを得る方法は、大きく二つあります。
- インラインアセンブリ
- ローカル変数や引数のポインタから無理やりずらす
今回は2の方法でやってみましょう。
例えば以下のような関数があったとします。
int func3 (int a4) {
return a4*3;
}
唐突ですが、この&a4はどこのアドレスを指すでしょうか? これはアセンブリからCの関数がどう見えないといけないか、という仕様の問題なので、以前触れた以下の文書をちゃんと読めば答えが書いてあるはずです。
ですが、そういうのはめんどくさいので、適当にアセンブリを出力させつつ、調べていって動くコードをでっちあげます。 (なおそういうゆとりっぽいやり方が嫌で全部を完璧に理解して一発で動くコードを書きたければそれでもいいです。以下のやり方と比較して好きな方を選んでくれてOK)。
基本コンセプトは、ローカル変数か引数にアンドをつけてポインタを取り出し、それを整数として足したり引いたりしてスタックの中身を覗き見る、という事をやります。
ポインタはアンドをつけると取れます。
&a4
このポインタを整数として演算する為には、これをさらにintにキャストします。
((int)(&a4))
これを足したり引いたりアスタリスクをつけたりして目的のアドレスの中身を読みだします。
開始と目標のアドレスをプリントする
まずは読みたいアドレスとして、func2のa3のポインタをプリントしてみます。 つまり以下の行をfunc2の側のどこかに入れます。
printf("func2's a3 address = %x\n", (int) &a3);
その次に、同様にa4のポインタのアドレスを出力します。
これに何を足したり引いたりすれば良いかは、ハードコードでは答えが出せるようになったはずですが、さすがにそれでは意味が無いので、もう少し意味のある方法で辿っていきます。
func3のr11をスタックに保存させて、それを読みだす(ここが最難関)
次にfunc3のアセンブリを読みます。 先頭はprintfを削除するとこうなっているはずです。
func3:
sub sp, sp, #4
一方でfunc3から何か関数を呼ぶと以下のようになるはずです。
func3:
push {r11, lr}
mov r11, sp
sub sp, sp, #8
最後のspから8を引いている所は人によっては4かもしれませんし12や16の人もいるかもしれません。 とにかく、何か関数を呼ぶと、先頭のpushが追加されるはずです。 (なぜ関数を呼ぶとこれが追加されるかは自分で考えてみてください)。
そこで何か関数を呼んでおいて、このpushしたr11の値を取り出す事に挑戦します。 このpushしたr11はfunc3に入る前にセットされたr11なので、func2のr11になります。
printfは引数が二つなので生成されるアセンブリが読みにくいので、print_addressという関数を用意しました。 これを使って、r11の中身を表示するようにしましょう。
まず、a4の値に4を引いたり8を引いたりして、それにアスタリスクを付けて生成されるコードを眺めます。例えばまず以下のコードをfunc3に入れてアセンブルしてみて、
print_address((int)&a4);
print_addressに渡しているr0が何なのか、アセンブリを読んで確認します。
次にこれを+4したり-4したり+8したり-8したりして、r11をpushした所と同じになるように調整します。(いちいちmycomp.shでアセンブリを生成させて読みながら合わせます)。 例えば-8するなら以下みたいなCのコードをコンパイルします。
print_address(((int)&a4)-8);
こうやって適当に動かしてみて無事合ったら、それを(int*)にキャストしてさらにアスタリスクをつけます。 例えば以下みたいなコードです。(8は適当です。実際の値にしてください)。
print_address(*((int*)((int)&a4)-8));
括弧がいっぱいあって意味が分かりませんね。自分もこんなの読み解けません。 順番に書いて行く事は出来るけど解読は難しい。 なので皆さんも上のコードを解読しようとする前に、自分で書いてみてください。 やるべきことの手順をまとめておくと以下のようになります。
- a4のポインタをintにキャストする
- 足したり引いたりする
- その結果をintのポインタにキャスト
- アスタリスクをつける
出来上がるコードは上のような、括弧だらけの難解なコードになるはずです。
こうしてfunc2のr11の中身が取れました。
func2のr11からa3のポインタを取り出し、値を取り出す
func2のr11のアドレスの値が取りだせれば
- それをintにキャストする
- 足したり引いたりする
- intのポインタにキャスト
- アスタリスクをつける
という手順でa3の値が取り出せるはずです。 2の所は多少の試行錯誤が必要ですが、たぶんここまで出来た人ならそう時間はかからないでしょう。
スタックの辿り方まとめ
- ローカル変数とか引数とかのポインタから前の関数のr11を取り出す
- r11の中身から、一つ前のr11のアドレスが分かる
- それを繰り返してどんどん上の関数に辿っていける
- 目的の関数のr11まで来たら、それに足したり引いたりして目的のローカル変数が取れる
これで頑張ればスタックを辿る事が出来るようになったと思います。
課題: stack_walk2.cでmain_msgを出力せよ
最後の課題として、もっとたくさん上に戻る必要がある事をやってみましょう。
stack_walk2.cのfunc3を書き直して、func3の中でmain_msgを出力してください。
ここまでの説明だけでは関数は一つしか辿ってないので、自分でアセンブリを調べて戻る方法を考える必要があるかもしれません。 たぶんここまで来れば自分出来るんじゃないか?と思うのですが、相当難しいので出来なくても不思議はない。(そんなの最後に出すのはどうなの?)
おわりに
以上でこのシリーズも終わりとなります。 個人的にはこの位やれば結構C言語プログラマとしては悪くないんじゃないかな、と思うのですが、どうですかね?
C言語には、入門書だけを読んでも良く分からない部分がある。 例えばヘッダファイルや分割コンパイルのあたり。 構造体の定義の順番や関数の定義の順番などである程度コンパイルエラーやリンクエラーを経験しないと、その辺の事というのはいまいちちゃんと学べない。 でもそうした経験を得る為には、ある程度の規模が必要で、それは入門書には収まらない。
また、プログラムの書き方というのは、作文とかと似ていて、書いて添削されて成長する、という部分があると思っている。 添削は企業や何かのコミュニティなどで経験を積むのが普通と思うけれど、 その場にどれくらい恵まれるか、そこの品質などはかなり運の要素があると思う。 一方でこれまでの自分の経験から、必要な最初の添削はそれこそ二週間とか三週間くらいで十分で、そんなにずっとやる必要は無い、とは感じていた。 この位なら、Stack overflowの質問に答えるようなノリで、オンラインで暇な人がやっても出来るんじゃないかな?とは以前から思っていた。
今回の試みは、この
- ある程度の規模を書いてみないと分からない事を伝える
- 最初の添削をして学ぶ部分をオンライン(gitter)で提供する
という要素を満たしつつ、C言語で入門書には載ってないが、OSなどの専門書に進むのに必要となる基本を一通り埋める、という事を目指しています。 だいたい埋められているんじゃないか。
当初自分が考えていた事はトップページの「教えようと思っている事」に書いてあるので、ここまで終わった後に読むとどのくらい最初の段階で考えていたのかが分かって面白いかもしれません。
内容としてはOSやコンパイラなどの個々の専門書に進む前に最低限やらないといけない事、よりは少し多くを含められたと思っています。 当初考えてたよりは3割増しくらいの分量になってしまいましたが、 その分、入門書の次にやるのに無理が無い範囲に収められたんじゃないか。(内容は相当高度かつ多岐に渡りますが…)
また、この埋めるべき所は、「C言語の入門者」と、「普通のベテランCプログラマ」の間の溝にもなってると思っています。 ベテランプログラマといってもピンキリで、しかも平均的なプログラマはとてもレベルが低いのでここでいう「普通」は平均とは程遠い水準ですが、それでも凄いプログラマという程の無茶な設定は控えて、その間の溝を埋めるように内容を考えました。
普通のベテランCプログラマは、入門書を読んだだけの人よりも、より難しい物を作って、多くのバグが生まれて苦労した経験を持っています。 普通のベテランCプログラマは、普通の入門書には出てこない、gcc -Sとかは日常的に読んでトラブルシュートしたり出来ます。 変なmakefileのお化けみたいなので作られたでかいシステムのビルドエラーを自分で原因究明して直していったり出来ます。
このシリーズでは、それら「普通のベテランCプログラマ」より「ちょっとだけ深く」いろいろな事を経験する、という難易度調整をしたつもりです。 gcc -Sを見るくらいしかやった事が無いベテランCプログラマよりはちょっとだけ深くアセンブリをやりました。 第1回の12よりあとの継続などのコードは、普通のベテランCプログラマが体験した事のある一番ややこしいコードよりもちょっとだけややこしいコードだと思います。 スタックウォークも理屈は知ってるが自分で書いた事は無い、くらいが普通のベテランCプログラマの実情じゃないでしょうか。
このシリーズを終えれば、経験はベテランに劣るけれど、その分ちょっとだけ難しい事も分かってる、くらいになるのが、目指した所でした。 結構野心的な目標ですが、なかなか健闘したんじゃないか。
分量としては、間に自分がフランス行ったりで止まったりとかちょこちょこあるけど、最初の人がだいたい4ヶ月くらいはかかるくらいの分量だったようです。 連続で集中して取り組めればもっと短いとは思いますが、ちょっとこの分量だとそれは非現実的かな、と思うので、それなりに継続的に取り組めてもだいたい四か月位に落ち着くんじゃないでしょうか。
自分は当初、どこかの温泉宿などで一週間くらいの合宿でやる内容、を想定してましたが、そうやって一日みっちりやる前提でも二週間くらいの分量かもしれませんね。
もともとは「なんか暇なんで誰かプログラム教えて欲しい人います?」とtwitterで言ったのが始まりで、しかもその時自分はPythonとかKotlinを想定してたのでまさかC言語を教えてくれと言われるとは思ってなかったので、もちろんこんな内容を話す事は考えてませんでした。受けてる側もこんなのが出てくるとは思ってなかったでしょう。
仕事しながらこれ全部やるのは相当大変だな、と思いますが、幸い最初にやってた人は学生だったようなので最後まで終えられそうです。 ただ学生だってこれ全部やるのは相当大変だと思うんですよね。 そもそもに、詰め込んだ内容をぱっと思いつく物だけ列挙しても、
- そこそこの規模のコードを書いて、正しいコードの書き方を学ぶ
- 線形リスト、ハッシュ、スタック、二分木など一通り自分で書く
- Javaのバイトコードとかをやる時に必要となる基本的なVMの動きを知る
- asyncなどの最近の言語機能を知る時の背景となる処理系の動きを知る
- 組み込みボードとかで実際に作業する時の低レベルな所で必要な知識と経験を得る
- 分からない言語機能などが出た時にアセンブリ読んで自分で調べられるようになる
くらいはすぐ出てくる。全部含めたらなかなか膨大で、こんなの全部やるとか相当大変ですよね。 ましてやもともとこんなのやると予定立ててなかった人が、ばんと突然目の前に積まれてやるというのは相当に困難だったと思います。
まぁ作る側も結構大変だったので、お互い良く頑張りました、という事で(笑)
教材作るのに比べればgitterで採点するのはそんな大変じゃないので、回りでこういうの好きそうなのが居たら勧めてもらえたらと思います。 そんなにたくさん教えたいとも思ってないですが、せっかく作ったのでもう4~5人くらいはやってもらいたい気もしている。
C言語、低レベルと親和性が高い割にはそこそこ大規模な物も作れて、なかなか面白い言語ですよね。 オブジェクトファイルとかtext, data, bssとかOS側の理解も深まるし、勉強目的にも、使うという点でも、ちょうど良い重さの良い言語だと思います。 このシリーズはいかにもC言語っぽい内容なので、C言語の奥深さと面白さは割と伝えられたんじゃないかなぁ、と自分では思ってるのですが、いかがでしょう?
何にせよ、お疲れ様でした!こんだけやったら大したもんですよ!(ほんと)
おまけ: JITしてみよう(かなり難しめ)
ラスボスを倒した後にはオメガと神龍倒さないとね!と言われたので(嘘)、 オメガと神龍に相当する、ラスボスより強い奴を用意する事にしました。
だいたい倒せない奴ですが、やりこむと倒せる奴です。
という事でクリア後にやりこみたい人向けに、JITの課題も作る事にしました。 これまでにやったのを全部使う感じです。
スタックウォークまでは、これまでの人生で自分が実際に必要になった事が何度かありますが、このレベルのJITは、自分の場合は勉強目的で書いた事と読む必要があったくらいがせいぜいで、必要に迫られて書いた事はありません。
そういう訳でここの内容は「C言語を教えて欲しい」という人に書かせる必要があるラインは超えていると個人的には思います。
そんな出来なくてもいい奴ですが、これ書けたら凄いね!
インラインアセンブリ入門
肩慣らしとして、軽くインラインアセンブリに入門してみます。
JITにはインラインアセンブリは要らないのですが、デバッグに便利なのと、普段の業務でもちょこちょこ使う事があるので、知っておいて損は無い。
フォルダとしてはsources/casm_link/05_inline_asm 以下で作業します。
Hello inline asm
まずは以下のファイルを見てください。
sources/casm_link/05_inline_asm/hello_inline.c
まず、以下のような関数があります。
int addmul3(int a, int b) {
return (a+b)*3;
}
aとbを足して3を掛けます。
その下に、以下のような関数があります。
int addmul3_inline(int a, int b) {
int res;
asm("mov r2, r0");
asm("add r2, r2, r1");
asm("mov r3, #3");
asm("mul %0, r2, r3" :"=r"(res));
return res;
}
このasm、というのが「インラインアセンブリ」と言われるものです。
Cコンパイラというものは、「C言語を読んでアセンブリを生成する」プログラムです。 インラインアセンブリというのは、このC言語のコンパイラに「ここの部分はそのまんまアセンブリとして結果ファイルに書いてください」という機能です。
だから、最後のasm以外はほぼそのまんまです。中身を抜き出すと以下のようになってます。
mov r2, r0
add r2, r2, r1
mov r3, #3
mul %0, r2, r3
ARMのC calling standardによれば、r0とr1は引数が入っているのでした。 だからこのコードは、「r0とr1を足して3を掛けて、結果を%0に入れる」という事はここまで進めてきた人なら分かると思います。
%0とは何か、というと、C言語の世界とのつなぎの為に必要になる所で、次に説明します。この時点では%0は「int res;」を表している、と思っておいてください。
これがインラインアセンブリです。addmul3_inlineがaddmul3と同じように動く事を確認してください。
拡張アセンブリと制約子
さて、%0ってなんやねん、というと、アセンブリとC言語の変数をつなぐ部分です。
何故こんなものが必要なのか、というのを考えるにあたり、以下のような関数を見てみましょう。
int addmul3_inline_notwork(int a, int b) {
asm("mov r2, r0");
asm("add r2, r2, r1");
asm("mov r3, #3");
asm("mul r0, r2, r3");
}
これはgccやclangでは、最後のr0がreturnの値にはなりません。 (VC6はいけた記憶もあるんだが…記憶違いかしら?)
mycomp.shを使って生成されるアセンブリを見ると、該当箇所は以下のようになっています。
@APP
mov r2, r0
@NO_APP
@APP
add r2, r2, r1
@NO_APP
@APP
mov r3, #3
@NO_APP
@APP
mul r0, r2, r3
@NO_APP
ldr r0, [sp, #8]
最後の行に注目してください。 せっかく用意したr0の値を、sp+8の中身で上書きしてしまっています。
これは、C言語のコンパイラがインラインアセンブリの中身を理解していない為、addmul3_inline_notworkはintを返すと言っているのにreturnが無い誤った関数だと思ってしまう為に起こります。 最後に変な値を返すコードを自動で生成してしまっている訳です。
これを防ぐ為には、いろいろな方法がありますが、Cの変数に結果を受け取ってreturnするのが一番良くやられるやり方です。 この時にコンパイラにアセンブリがこの変数に結果を受け取ります、という事を教えてやる必要がある。
このインラインアセンブリとC言語の変数の間をやりとりする為の仕組みが「拡張アセンブリと制約子」という仕組みです。
インラインアセンブリのうち、特定のレジスタを%0とか%1で書いておき、そのあとに「ここの%0にはC言語のこのローカル変数のレジスタを入れてね」とコンパイラにお願いする事が出来ます。
さきほどのaddmul3_inlineの、該当する行を見てみましょう。
int res;
// ... 中略...
asm("mul %0, r2, r3" :"=r"(res));
mulの結果のレジスタを%0と書いています。 そのあとにコロンをつなげて、”=r”と書いてあり、そのあとに括弧で使いたいC言語の変数を書いています(この場合はres)。
“=r”が制約子と言われるものです。rがレジスタを表し、”=”は書き込みで使う、という意味になります。 この辺はARMではあまり意味が無い記述なので、深入りはしません。 レジスタの制約が多いCPUの時にはこの辺が必要になります。
コロンというのがC言語にしては珍しいですね。 変なシンタックスなので、ここは丸暗記してしまいましょう。以下のような書き方です。
:"=r"(なんか変数名)
全体としては、以下のような形です。
asm("パーセントを使ったアセンブリ文" :"=r"(Cの変数名));
これで%0の部分がCの変数のレジスタに置き換えられます。
ちゃんと勉強したい人はGCC-Inline-Assembly-HOWTOの5. Extended Asm.などを読みましょう。
このように、movやmulといったアセンブリの結果をC言語の変数に受け取る事が出来ます。
インラインアセンブリで足し算
次に、ちょっと複雑な例としてラベルやジャンプのあるケースを見てみましょう。
sources/casm_link/05_inline_asm/sum_inline.c
を見てみてください。
まずは以下のソースから。
int sum_till(int a) {
int sum=0;
for(int i = 0; i < a; i++) {
sum+=i;
}
return sum;
}
0+1+2+3+…+(a-1)を計算するコードです。 今見て思いましたが0は足す意味無いですね。ゆとりなのでそういう事は気にしない。
で、これのインラインアセンブリ版は以下のようになっています。
int sum_till_inline(int a) {
int res;
/*
Use r1 as loop counter.
Use r2 to store temp result.
*/
asm("mov r1, #0");
asm("mov r2, #0");
asm("loop:");
asm("cmp r0, r1");
asm("beq end");
asm("add r2, r2, r1"); // sum+=i
asm("add r1, r1, #1"); // i++
asm("b loop");
asm("end:");
asm("mov %0, r2" :"=r"(res));
return res;
}
loopとendというラベルを使っているのが新しい所ですが、まぁここまで来た読者には説明は要らないですかね?
こんな感じで書けます。自分でも書いてみますか。似たような課題を一つやってみます。
課題: sum_range_inline.cを完成させよ
sum_range_inline.cのsum_range_inlineの実装を埋めて、テストをパスするようにしてください。 気まぐれでendの所も足すようにしたので注意してsum_rangeの方を見てみてください。
JIT入門
ではここまでの知識をもとに、一番簡単なJITをしてみます。 以下のファイルでやります。
sources/casm_link/05_inline_asm/hello_jit.c
JITとは何か、というのを考えるにあたり、ちょっと第二回の知識を復習したいと思います。
まず、以下のバイナリは見覚えありますか?
0xE3A01068
第二回の「3 バイナリを理解しよう」から持ってきました。
頑張って解読すると、以下らしいです。
mov r1, #0x68
この辺は第二回やってた時は結構見ただけで分かる人もいたと思いますが、少し離れてるともう分からないですよね。 E3Aはmovか?68は即値っぽいなぁ。01はr1か?みたいな。ゆとりの私には無理。
ただ解読できるかはおいといて、こうやって命令にはバイナリが対応しているのでした。
そしてC言語の関数としては、例えば以下のような関数、
int some_func() {
return 5;
}
を考える場合、ようするにこの関数は、以下のようなアセンブリになるのでした。
mov r0, #5
mov r15, r14
ではこの二つのアセンブリをアセンブルすると、バイナリとしてはどうなりますか?というと以下のようになります。
0xe3a00005;
0xe1a0f00e;
第二回の簡易アセンブラで作ってみてバイナリエディタで見たりしてみてください。
JITというのは、ようするにこのバイナリを配列に突っ込んで、関数と見立てて実行する事です。 C言語はそんな事が出来てしまうやばい言語です。
配列と関数ポインタへのキャスト
さて、まず上の二つのバイナリを配列に詰めてみましょう。
int buf[2];
buf[0] = 0xe3a00005;
buf[1] = 0xe1a0f00e;
これを関数ポインタにキャストすると、C言語は関数だと思い込んで実行し始めます。(ただし実行可能属性がついてないのでLinuxではクラッシュする、後述)。
まず関数ポインタの変数の定義の仕方から見てみましょう。
関数ポインタはC言語の入門書には書いてあるはずですが、だいたい読んだ時は何を言っているのか良く分からない項目だと思うので、シンタックスをちょっと細かく説明します。
引数無し、返値がintの関数ポインタの変数、funcvarを定義するには以下のようにします。
int (*funcvar)();
括弧が多くてややこしいですが、funcvarが変数名です。 イメージとしては、以下のような感じ。
FUNC_TYPE funcvar;
シンタックスはややこしいのですが、基本的な作り方としては、以下のように考えるとよと思います。
- まず目的の関数ポインタと同じ型の、普通の関数の宣言を思い浮かべる
- 関数名の所を括弧でくくる
- 関数名の前にアスタリスクをつける
これで関数ポインタの変数が宣言出来ます。やってみましょう。
/* 1. まず目的の関数ポインタと同じ型の、普通の関数の宣言を思い浮かべる */
int some_func();
/* 2 関数名の所をかっこでくくる */
int (some_func)();
/* 3 関数名の前にアスタリスクをつける */
int (*some_func)();
こんな感じです。引数がある場合は例えば
int some_func(int a, double b);
とかなら、以下のようになります。
int (*some_func)(int, double);
仮引数の名前(aとかb)はあっても無くても平気なはずですが、普通関数ポインタの場合はこれら無しにする風習です。理由はしりません。
さて、関数ポインタとしてfuncvarという変数を定義します。
int (*funcvar)();
これに何かをキャストする場合は「関数ポインタの変数の宣言の変数名から変数名を抜いた物を括弧でくくる」というシンタックスになります。
例えば意味が無いですが、123を関数ポインタにキャストする場合は以下のようになります。
funcvar = (int (*)())123;
以上を踏まえて、先ほどのbufをキャストしてみましょう。
funcvar = (int (*)())buf;
これで関数のように呼べます。
int res;
res = funcvar();
ですが、Linux上でこれを実行するとクラッシュしてしまうはずです。 (なおOS無しのbaremetal上なら少し工夫すれば実行できると思います)
これはLinuxにはメモリに保護属性というものがあるからです。
メモリの保護属性と実行可能領域
Linuxはメモリを確保する時に、三つの保護属性のフラグを指定できます。 READ, WRITE, EXECの三種類です。
READは読み取り可能、WRITEは書き込み可能、EXECは実行可能です。
ロードの時、実行バイナリはtext, data, bss, rodataの四つくらいのセグメントがあって、 それぞれ別々にメモリにロードされる、という話をしました。 この時に、詳細の振る舞いはおいといておおざっぱには、
- textにはREADとEXECの保護属性
- bssとdataにはREADとWRITE
- rodataにはREAD
がつくと思っておいてOKです。(アドレス解決とかがあるので詳細は違うのですが)。
こうしておく事で、ユーザーの入力などに悪意のあるバイナリを入れてバッファオーバーフローなどで実行させるのを防ぐ事が出来ます(基本的には)。
そして上記のbufの定義は以下だったので、
int buf[2];
これは、bss領域に作られるので、実行可能属性がついていません。
なので、JITなどの特殊な用途の場合はこういう配列の作り方では無くて、mmapシステムコールを使ってメモリ保護を実行可能にしておく必要があります。
具体的には以下のようなコードで1024バイトの実行可能領域を作ります。
(int*)mmap(0, 1024,
PROT_READ | PROT_WRITE | PROT_EXEC,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
引数がいっぱいあって難しそうなので、細かい事は考えずにこれをmallocみたいな物と思ってください。 重要なのはPROT_EXECのフラグがついている事です。
詳しく引数の意味を知りたい人はman mmapを読むと良いけれど、ゆとりはそういうのは気にせずに先にすすむ。
こうやって作ったバッファ、binary_bufにバイナリを詰める
// mov r0, #5
binary_buf[0] = 0xe3a00005;
// mov r15, r14
binary_buf[1] = 0xe1a0f00e;
そして関数ポインタにキャストする。
int (*funcvar)();
funcvar = (int(*)())binary_buf;
そして呼ぶ。
res = funcvar();
assert_true(res == 5);
これで動的に関数に相当するバイナリを作って実行出来ました。
課題: sum_till_jit.cを完成させよ
sum_till_jit.cのjit_sum_tillを埋めて、sum_till_inline相当の関数を動的に生成してみましょう。
ヒントとしては、全部気合でバイナリを心の中で生成してみるのは辛いので、まずこのままの状態でa.outを作ってみて、objdumpします。
そしてsum_till_inlineを見ると以下のようになっているはずです(細部は違うと思うので各自の環境に合わせてください)。
000104c0 <sum_till_inline>:
104c0: e52db004 push {fp}
104c4: e28db000 add fp, sp, #0
104c8: e24dd014 sub sp, sp, #20
104cc: e50b0010 str r0, [fp, #-16]
...
一番何も考えないやり方だったら、このバイナリの所を何も考えず代入していけば良い。 例えば以下。
binary_buf[0] = 0xe52db004; // push {fp}
binary_buf[1] = 0xe28db000; // add fp, sp, #0
binary_buf[2] = 0xe24dd014; // sub sp, sp, #20
binary_buf[3] = 0xe50b0010; // str r0, [fp, #-16]
...
ただ、我らは第二回でこのバイナリの生成をやってきたので、もうちょっと詳細が分かっているはずです。 fp関連の処理やsp関連の処理は、この場合は要らない事を知っている。
だから上記のやり方でとったobjdumpの該当箇所を抜粋しつつ、要らない所を削ったり、不要に一旦スタックに入れているのを直接目的のレジスタに入れるように直していくのが良い。
例えば最初から
binary_buf[0] = 0xe3a01000; // mov r1, #0
binary_buf[1] = 0xe3a02000; // mov r2, #0
binary_buf[2] = 0xe1500001; // cmp r0, r1
のように始めてしまって良いでしょう(r0には引数が入っています)。
または第二回でやってたように、アセンブリで目的の関数を書いてみてバイナリを作ってバイナリエディタなりobjdumpなりで見れば、ほぼ答えが得られると思います。それをひたすらコピペして代入していく、というやり方でもOKです。好きなやり方でやってください。
ただ、採点する側の私の気持ちにも少しは配慮して、各バイナリの元となったニモニックはコメントで書いておいてくれないと(私が)辛い。
JITについて考える
JITはようするに、配列にARMのバイナリを詰めて、関数ポインタにキャストして、呼べば良い訳です。 このうち、関数ポインタにキャストして呼ぶ所はだいたい同じです(引数とかがちょっと違うかもしれませんが)。
だからJITのキモは、配列にバイナリを詰める所になります。 バイナリと言っているのは、例えば以下のような奴です。
0xe3a01000; // mov r1, #0
このバイナリをいちいち考えるのは大変ですが、 第二回の「簡易アセンブラ」を作った時に、このプログラムはすでに作っているはずです。
簡易アセンブラはメモリにバイナリを詰めてファイルに書き出していましたが、 JITはメモリにバイナリを詰めた後キャストして呼ぶ、という所が違うだけで、アドレス解決が無ければほとんど同じ物だという事が分かります。
そこで、アドレス解決無しで出来そうなもうちょっと面白い物を最後に作ってみる事にしましょう。
超簡易PostScriptもどきをJITしよう
最後の課題として、VMのJITに相当する物を実装してみましょう。 第一回でやったバイトコード版の実行可能配列を実行する所をJITに置き換えればかなり本格的なJITありVMが作れます。
ですがJITの本質的な所だけを学ぶなら、そこまで大きい物でなくても十分でしょう。 そこで第一回にやった簡易PostScriptを、さらに簡単にして電卓くらいにした物をJITしてみる事にします。 電卓といってもスタックがあるので結構いろいろな事が出来るプログラムです。
超簡易PostScriptの仕様
primitiveとしてはadd, mul, div, subだけのあるPostScriptのサブセットを実装する。 スタックはあって、数字もある、くらい。
例えば以下が実行できる。
3 4 add 2 sub 4 mul
結果は20。
スクリプトとしては実行すると必ず最後にはスタックに一つ値が残るような入力だけを受け入れるとし、この最後に残った数字を結果とみなす。 (なおエラーチェックとかは無しでいいです。入力をちゃんと気を付けて書く、という事で)。
さらに、実行可能ネームとしては、r0とr1という二つの変数があるとする。 この値は外から与えられるもので、実行してみるまでPostScriptとしては値は分かってない物とする。
数字はmovの即値に入る範囲だけでいいです。
C言語側から見たJITの仕様
超簡易PostScriptのスクリプト(以下スクリプトと呼ぶ)の文字列から、「変数がr0とr1の二つの引数をとって、intの結果を返す関数」を生成する。 このJITする関数はjit_scriptと呼ぶ事にしよう。
シグニチャは以下。
int* jit_script(char* script);
そして、例えば以下のようにして得られるfuncpは、
int *funcp = jit_script("1 2 add r1 sub 4 mul");
キャストして呼ぶと、以下のような関数として振る舞うとする(関数名は便宜上generatedとつけました)。
int generated(int r0, int r1) {
return ((1+2)-r1)*4;
}
このr0やr1はC言語としては引数として見えて、PostScript側からは実行可能ネームとして見える訳です。
この関数からは、スクリプトを実行して最後に(PostScriptの意味で)スタックに残った結果をreturnするとします。
以下では sources/casm_link/06_jit_ps で作業します。
説明が分かりにくければ、コードを見てもらう方が良いかもしれません。 eval.cのmainのコメントアウトを外してリンクして、ちょこちょこいじればPostScript側はだいたいわかるはずです。
おおざっぱな方針
おおざっぱには以下みたいに進めます。
- emitter的なのを作る
- 第二回から簡易ディスアセンブルを適当に持ってきて修正し、binary_bufをデバッグ出力できるようにする(オプショナル。やらなくても良いけどせっかくなので)
- 第二回の簡易アセンブラから使いそうなコードを持ってくる
- eval.cのevalの構造を真似し、第一回のcompile_exec_arrayみたいな感じでバイナリを出力
- デバッグ用にinlineアセンブリで特定のケースのコンパイル結果になりそうなアセンブリを書いてみたり、配列に直接バイナリを詰めて実行してみたりして動かない原因を切り分けていく
書かれているコードを理解する
ここまでの説明は結構雑なので、ソースコードを読んで課題の意図を理解する必要があるかもしれません。
まずparser.cのmainのコメントを外してparser.cだけで実行してみる。 次にmainをコメントアウトしてeval.cの方のmainを入れて、parser.cとeval.cをコンパイルして実行してみる。
そのあとはeval.cの中身を理解します。 だいたいは第一回でやった物をちゃちくした物なので、見ればすぐわかるでしょう。 なお、私が手抜きで実装したものなので、細かい所で手抜きなのは見逃してください。
実装する対象を理解する
実装するのはps_jit.cにある、jit_script関数です。 このmain関数にテストが書いてあるので、これをパスするようなものを作ります。
jit_scriptは割とちゃんとしたインタープリタになるし、このmainのインプットはまぁまぁ複雑なので、最初に突然これが動く、というのは難しいかもしれません。
そこで、これを順番に実装していきます。
コードとしては、第一回のcomple_exec_arrayと同じような事をします。 覚えていますかね? ようするに入力をパースしていって、それぞれのtokenに応じてコードを生成していく訳です。 構造としてはeval.cのevalと似た物になるので、まずはこれをコピペして中を書き換えていくのが早いでしょう。
基本的な構造
実装する物としては、スクリプトを読んで解釈する部分と、 解釈した結果バイナリを吐く部分に分かれるはずです。
前者は第一回のcompile_exec_arrayやevalに似た物で、後者は第二回の簡易アセンブリに似た物になります。
eval.cのevalをjit_scriptにコピペして中を書き換えれば完成なのですが、 最初に動かすと、普通はsegmentation fault、と言って落ちるだけだと思います。
そこで、簡単な例から順番に進めます。具体的には
- 3を返すだけの関数のJITをハードコードで生成する(上でやったhello_jit.cと同じ事)
- 3を返すだけの関数を、第二回から持ってきた関数でやって動かす
- 3をスタックに積んで返すだけの関数を、ハードコードで生成する
- 3をスタックに積んで返すだけの関数を、第二回から持ってきた関数で生成する
というように、簡単な例から ハードコードー>第二回の関数を使った生成 という風にやっていって、一つずつ動かしていきます。
ある程度動いたらjit_scriptにスクリプトを食わせて動かしてみて、動かないケースがでる都度「それを解釈したら生成されるであろうバイナリを手書きで動かして切り分け」をやっていきます。 unit testも書いて行きましょう。
レジスタとかスタックの使い方
r0とr1が引数になります。結果は最後にr0に入れると返した事になります。
PostScriptのスタックとしては、普通にstmdbとldmiaでアセンブリのスタックを使えばいいと思う。
r0とr1はスクリプト上で何度も出てくる為、この二つのレジスタは最後以外はいじらないで、read onlyとしておくのが良いと思う。
addとかsubとかする時は、r2とr3を使っていけば良いと思う。
スタックに即値をpushする時はいったんr2にmovしてからstmdbすれば良いと思う。
mainでjitしている結果のbinary_bufの逆アセンブル
一応せっかくなので、第二回の逆アセンブラを持ってきて少し手直しして、binary_bufを逆アセンブルもしてみましょう。(mulとかは対応してなかったはずなので、その辺の対応を入れて下さい)
逆アセンブル結果はgitterに貼って私に見せて下さい。