第一回蛇足 Parserのラッパでexec arrayを実行する
第一回のeval_exec_arrayの実行において、 パーサーにラッパをかましてexec arrayの時にもトークンのフリをするのが一番手抜きな実装かな、 と思っていたのですが、やってもらったところ、継続をあらわに実装する必要があり、 あんまり楽ではありませんでした。
そういう訳で解説の方は二人目以降の人向けに直すつもりですが、せっかくなのでこのパーサーのラッパの方針がどうなったのかの記述も残しておきます。
eval_exec_arrayを作ろう
さて、これを実装する為には、exec arrayのstruct Elementを渡して実行する関数を作る事になります。 これはevalと凄く似ているけれど、parse_oneの所だけ配列の要素を順番に見ていく、という関数になります。 ただしすでにコンパイルされているので、”{“などの記号が出てくる事はありません。
これを実装する方法は幾つか考えられます。
- 心を無にしてevalをコピペする
- parse_oneの所と、その結果を評価する部分を分離して、評価する方だけを共有する
- parse_oneの所にラッパをかませて、バイトコードを設定出来るようにする
- 関数ポインタでparse_oneに相当する物を渡せるようにする
- そもそもにトップレベルのevalもバイトコード化する
1は一見するとひどいですが、他の選択肢と比較すると結構アリかな、という気もします。 この場合、概念的にはevalはインタープリタ、eval_exec_arrayは仮想マシンとなります。 コードの重複は多くなりますが、勉強目的に両方あるのも悪くないかな、という気はする。
2でうまくいけばそれが一番簡単ですが、これはちょっとどう実装したらいいのか、ぱっとは自分では思いつかない程度には難しそうです(中からparse_oneが呼ばれちゃうのをどうにか上に引き上げる必要がある)。
最初に自分が考えたのは3ですね。これが一番簡単でC言語的かな。 4も昔実装した事があります。これも悪くない。
5は実行可能配列じゃないトップレベルのコードもすべてバイトコードに一回変換してから実行する、というスタイルです。eval自体はシンプルになりますが、慣れてないとコードは分かりにくくなるのと、 ここまでのコードの大きな変更が必要になります。 実際の処理系だとだいたいこの方式ですが、今回の勉強目的だと読みにくさの悪影響が大きいのでいまいちかなぁ。
今回は一番簡単そうな3で行きましょう。
eval_exec_arrayさえ出来てしまえば、あとはプリミティブの所でC_FUNCTIONを呼んだのと似たようなコードを追加すれば良いだけなので自分で出来るでしょう。
なお実行可能配やC_FUNCTIONなどのような関数として使われるexecutable nameをPost Scriptではオペレータとも呼びます。
ネスト無しでのeval_exec_arrayの実行
まず簡単の為、ネストは無い前提の実行から説明します。
parse_oneと同じシグニチャの、get_next_tokenという関数を作る事にします。 これはparser.cに実装する事にしましょう。 概念的には以下のようなコードになります。
static struct ElementArray *exec_array = NULL;
int get_next_token(int prev_ch, struct Token *out_token) {
if(exec_array == null) {
return parse_one(prev_ch, out_token);
} else {
exec_arrayから一つElement取り出して返す
}
ただexec_arrayはElement、parserはTokenなのでちょっとミスマッチがあります。 ここは適当に辻褄を合わせます。だいたいはElementに対応する同じ物がTokenにあるので、それを入れればいいはずです。
以上の事を実際に実装しようとすると、もうちょっといろいろやる必要が出てきます。 感じとしては以下みたいなコードになるでしょう(説明の為にイモっぽく実装してあるので、理解したらもっと普通に実装して良いです)。
static struct ElementArray *exec_array = NULL;
static int operation_pos = 0;
// EOF以外ならなんでもいい。
#define CONTINUE 1
int get_next_token(int prev_ch, struct Token *out_token) {
if(exec_array == null) {
// TODO: prev_chがCONTINUEの時の処理をする
return parse_one(prev_ch, out_token);
}
// TODO: ここで空の実行可能配列の場合のエラー処理を入れる
struct Element *cur = exec_array->elements[operation_pos];
operation_pos++;
// TODO: ここでcurの内容とほぼ同じになるようにout_tokenを偽造する。
if(exec_array->len == operation_pos) {
exec_array = NULL;
operation_pos = 0;
return EOF;
}
return CONTINUE;
}
TODOと書いてある所は自分で考えて実装してみて下さい。
で、外から実行可能配列をセットするAPIも足します。名前はset_exec_array_to_parserにしましょう。
基本的なアイデアはcl_getcで文字列を外から設定出来るようにしたのと似ているので、それを参考にしてください。
この後evalのparse_oneをこのget_next_tokenに置き換えます。
これらが終わると、ネスト無しのeval_exec_arrayはだいたい以下のようなコードに出来るはずです。
void eval_exec_array(struct ElementArray *elemarr) {
set_exec_array_to_parser(elemarr);
eval();
}
一文字先読みしている文字などの辻褄あわせはちょっと気をつける必要があるかもしれませんが、 だいたいこんな感じで実装出来るはずです(たぶん)。
まずネスト無しのテストを足してちゃんと動く所までやってみてください。
ネストした呼び出しの実行
さて、eval_exec_arrayでは一つ難しい事があります。それはネストした実行の場合です。 以下のようなコードを考えてみましょう。
/ZZ {6} def
/YY {4 ZZ 5} def
/XX {1 2 YY 3} def
このXXを実行すると、スタックには何が入るでしょうか? 答えは「1, 2, 4, 6, 5, 3」だと思います。 このケースのテストがちゃんと通ればここで述べる事は理解出来なくても先に進んでOKです。 このXXを実行してスタックの中身を確認するテストを、ちゃんと追加してください。
ここでXXを実行する時に何が起こるかを考えてみましょう。まず1をスタックにプッシュし、次に2をスタックにプッシュする。 ここまでは良いのですが、次にYYを実行しろ、と言われます。
YYはdict_getすると実行可能配列のようなのでこれを次に実行していく訳ですが、 このYYの実行が終わった後もまだXXにはやる事が残っています。そう、3をプッシュする事です。これをYYの実行が終わった後にやらないといけません。
つまり、YYを実行する時には、それが終わった後にXXの続きをどこから再開するかを覚えておいて、YYの実行が終わった後にXXの続きの実行を再開する必要があります。 下の図で言う、赤の矢印がどこに戻るかを覚えておいて戻ってくる、という事ですね。
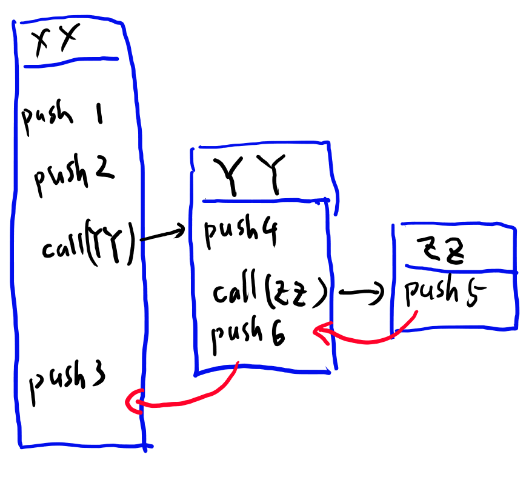
これは先程のAPIで言うと、XXを引数にset_exec_array_to_parser()を呼び出してevalを実行していくと、 その途中でYYを引数にset_exec_array_to_parserが呼ばれちゃうので、 operation_posとexec_arrayが上書きされちゃう、という話になります。
このoperation_posとexec_arrayという2つの情報が戻ってくる為には必要な訳ですね。 ただYYの中でもさらにZZでoperation_posとexec_arrayを上書きしちゃうので、 ネストの数だけとっておく仕組みが必要です。つまりスタックが必要になります。
継続とスタックを使った実装(今回の最難関!)
プログラムにおいて、現在どこを実行しているか、という情報を「継続」と言います。 英語では「Continuation」と呼ばれています。
継続はSchemeなどの一部の言語には言語仕様として存在しますが、普通はインタプリタなどの内部実装に隠れているものです。
これまでoperation_posと呼んでいた物を、継続のメンバとして第二回のアセンブリの内容と近づける為、以下ではpcと呼びます。プログラムカウンタの略です。
まず、現在実行している場所は実行可能配列とそのインデックスの組で表せます。 実行可能配列はElementArray型とすると、以下のような構造体で現在実行している場所が表せます。
struct Continuation {
struct ElementArray* exec_array;
int pc;
};
この2つの情報があれば基本的にはそこから再開する事が出来ます。
例えば以下みたいなコードです。
static struct ElementArray *exec_array = NULL;
static int operation_pos = 0;
void set_cont(struct Continuation *cont) {
exec_array = cont->exec_array;
operation_pos = cont->pc;
}
これでいつも指定した場所に戻れるようになりましたが、この実行可能配列が終わった後にどこに戻るかは分かりません。 そこでそれを覚えておく為に、このContinuationをスタックに入れる必要があります。(普通はこのスタックとpcを合わせた物を継続と呼びますが、今回はコードの都合で継続とそのスタックと呼ぶ事にします)
PostScriptのスタックと区別する為に、これをcontinuationのスタック、略してco_stackと呼ぶ事にしましょう。co_push、co_popなどで対応する命令を書きます。
すると、eval_exec_arrayはだいたいこんな疑似コードで書けます。
void eval_exec_array() {
while(co_stackに要素が入ってたら) {
struct Continuation* cont = co_peek();
set_cont(cont);
while(get_next_token()が取れる間){
switch(token->ltype) { // 注:1
case 実行可能配列以外なら:
普通の処理をする; // 注:2
case 実行可能配列なら:
struct Continuation next_cont = {exec_array: token->byte_codes, pc: 0};
co_push(&next_cont); // 注:3
1つ目のwhileから抜ける // 注:4
}
}
co_pop();
}
}
peekというのはスタックから削除せずに先頭要素を覗き見る関数のつもりで書いてます。
eval_exec_arrayを呼ぶ時は、呼ぶ前にco_pushで対象の実行可能配列をpushする前提でコードは書いてあります。
つまりeval_exec_arrayはいつもスタックトップの継続から続きを実行していき、 その実行可能配列の実行が終わったらスタックの次の継続の実行を再開していきます。 これはC言語を始めとした多くのプログラミング言語の関数呼び出しと同じ仕組みを手動で実装してる事になります。
今回の疑似コードはこれまでよりも擬似度合いが高くて、そのままでは実装出来ない形になっています。 良く意味を理解した上で実装は疑似コードと大きく変えた、もっと自然な形で実装するのが理想です。 細かい所についてもうちょっと補足をしておきます。
上記の注1のtokenは、その一行上のget_next_tokenで得られるtokenです。
注2の所はevalが一つのTokenを処理するのと同じになりますが、evalを呼び出すとどんどん次のtokenまで取っていってしまうので駄目です。 ここではtoken一つ分だけ処理します。 まずevalのtokenを一つ処理している所から必要な物をコピペしてきてテストまで動かすのが簡単でしょう。 それをcommitして、リファクタリングとして2つの関数の構造を見直すのがいいと思います。 eval_exec_arrayとevalは大部分は一本化出来るはずです。
注3の所では、現在まで進んだoperation_posをまたトップの継続のpcに戻す処理も必要です。 これはco_pushをする時はいつも必要なので、co_pushの中でやってしまう方がいいかもしれません。 するとget_next_token周りはcontinuation.cに移す方がいいかもしれません。 またはそもそもoperation_posなどのグローバル変数は廃止して、 いつもco_stackのトップのContinuationのpcに対して操作をするようにget_next_tokenを変えてもいいかもしれません。どちらでもOKです。
注4は、単にbreakとするとswtichから抜けるだけでwhileからは抜けません。 このまま実装するならgotoになりますが、関数化したりswitchでなくしたりなどでgotoを使わなくするのは可能なはずですので、考えてみてください。
C関数から実行可能配列を実行したい場合
後述のexecやifelseなどでは、Cで実装したprimitivesから実行可能配列を実行したい、 という場合があると思います。 こういう時にeval_exec_arrayを呼び出すと、eval_exec_arrayが再帰呼び出しになってしまいます。
このeval_exec_arrayの中から呼ばれるcfuncの中でeval_exec_arrayや継続に関わる事を直接操作すると、かなり何が起こっているのか難しい事態になります。 そこで、cfuncからは、直接co_stackを操作したり、eval_exec_arrayを呼んだりはしないようにしましょう。
その代わり、そうした処理はすべてeval_exec_arrayの中でやるようにします。 そして、cfuncからはやって欲しい事をリクエストする、という形にしましょう。
execの実装の為に実行可能配列を実行して欲しい場合は、
void request_execute(struct ElementArray *execarr);
という関数をcfuncから呼ぶ事にします。
すると、eval_exec_arrayは、元のコードが以下のような感じだったら、
void eval_exec_array() {
...中略...
if(辞書をlookupしたらcfuncだったら) (
cfunc();
}
...中略...
}
以下のような疑似コードに変更します。
void eval_exec_array() {
...中略...
if(辞書をlookupしたらcfuncだったら) (
cfunc();
if(もしrequest_executeが呼ばれていたら) {
その引数のexec_arrayを継続としてco_pushして、whileの先頭に戻る
}
}
...中略...
}
request_executeは渡された実行可能配列のポインタをグローバル変数にとっておく感じでしょうね。
一旦ここまで出来たら見せてください。
C関数でループを実装したい場合
さて、次に実行する実行可能配列を指定するだけだと、ループが実装出来ない事に気づきます。 repeatなら、例えば
5 {123} repeat
なら、
{123} exec {123} exec {123} exec {123} exec {123} exec
という実行可能配列をmallocで作ってrequest_executeすればとりあえずは動きますが、 whileみたいな物はこの方法では実装出来ません。
whileのようなループを実装する場合は状態を持つ必要があるので、
- 辞書にこっそり適当な変数で状態を持つ
- 関数の実行を関数オブジェクトの実行に変える
- 実行可能配列を動的に生成する(ジャンプが必要)
の3つくらいの方法が考えられます。 ここでは3の方法を考えてみようと思います。
その為には、まずジャンプを実装する必要があります。
以下の2つの命令を実装しましょう。
| num1 | jmp | - | num1だけ先の実行可能配列の要素の実行に飛ぶ(マイナスだと戻る) |
| num1 num2 | jmp_not_if | - | num1が0だったらnum2だけ先の実行可能配列の要素の実行に飛ぶ(マイナスだと戻る) |
jmpとjmp_not_ifは、同じ実行可能配列内しかさしません。 実行可能配列の「最後+1」をさしてる場合は、この実行を抜けるという意味になるとします。
このjmpとjmp_not_ifは、eval_exec_arrayの中で実行します。 cfuncとして登録するのでは無く、この2つはstreqして特別処理としてeval_exec_arrayの中で処理するのが良いでしょう。 なお、辞書にこの2つを、特別なELEMENT_TYPEとして登録する(ELEMENT_PRIMITIVESとかで値をjmpは1、jmp_not_ifは2にするとか)と、無駄なstreqを減らす事は出来ます(別にやらなくてもいいです)。
これを用いると、例えば
{dup 5 gt} {hoge} while
というコードは、ジャンプのアドレスを見やすくする為縦に並べて書くと、
{dup 5 gt}
exec
5
jmp_not_if
{hoge}
exec
-7
jmp
というコードで実行出来ます。 while_opではこういう実行可能配列を作ってrequest_executeすれば良いと思います(本来はcompile_exec_arrayの段階でこの変換をやってしまう方が良いのですが、今回はevalも残している為こんな実装の方が両方で動いて良いでしょう)。
基本的に、上記の0行目と4行目以外は毎回同じで、 コード上は0行目と4行目は実行可能配列のポインタに過ぎないので、 この変換は見た目ほど難しくは無いと思います。(malloc(sizeof(struct Element)*8);とかやって順番に入れていけば良い、exec、jmp_not_if、jmpは定数で良いのでmallocせずに”exec”とかを代入するだけで良い、たぶん)。
repeatも、対象とする実行可能配列がスタックをいじらない物だと分かっていれば同じような方法で実装が可能ですが、 PostScriptにはそういう制限は無いのでこの方法では実現出来ませんね。 とりあえず毎回実行可能配列を動的に生成する方法にしましょう。(なおJavaVMなどではこの手のbody部はスタックをいじらない、という決まりになっているのでこの方法ですべて実装出来ます)。
get_next_tokenをなくす
ここまで来てなんですが、eval_exec_array専用の命令が出てきてしまった以上、parserのラッパとしてevalとeval_exec_arrayを統一するのは無理になりました。 自分の見落としです。すみません。
そこで、get_next_tokenは廃止して、素直にcontinuationのElementArrayを順番に実行していくコードを書く方がもはや楽でしょう。
void eval_exec_array() {
while(co_stackに中が入ってたら) {
coからelemarrayと現在位置、posを取り出す。
int i = pos;
while(i < elemarray->len) {
Element *cur = elemarray->elements[i];
// 以下これまでの処理
i++;
}
}
これなら、このiを操作するだけでjmpとjmpifが実装出来るので簡単だと思います。
継続をあらわに実装すると、whileの独自拡張は当初私が思ってたよりも本格的なバイトコードにしないと実現出来ない事に気づきました。
おまけ:コンパイルについて考える
以下は試して無いで適当に書くので間違いもあるかもしれません。
簡単の為、ここではevalの事は考えないでおいてeval_exec_arrayだけだとします。
考えてみれば、そもそもcompile_exec_arrayでwhile_opをjmpとjmp_not_ifに展開する事が出来ます。 ifelseもjmpとjmp_not_ifに展開出来ると思います。
するとeval_exec_arrayの方ではwhileやifelseの実行可能ワードの処理は必要無い事になります。 こちらの方が実行は早いし、実行時にmallocなど使わなくて良いので良いと思います。
jmp, jmp_not_if, execをenumの型として実行可能ワードとは別の扱いにしておくと、 これらのコードは辞書のlookupをせずに実行出来ます。 辞書のlookupは遅いので、やらなくて済むのならやらない方が良い。
さらに考えてみると、このcompile_exec_arrayとeval_exec_arrayは、何も同時にやる必要はありません。 あらかじめファイルを読んでElementの列に直すコンパイラと、このElementの例を実行していくだけのvmに実行ファイルを分ける事が出来ます。
もっと言えばこの2つは同じマシンで実行する事もありません。 ホストのマシンでコンパイルを実行し、VM部分はもっとリソースの少ないマシンで実行する事も出来ます。
その場合、文字列の部分を(本編の最後の方に書いてある)シンボルにする事で、辞書以外はだいたいmalloc無しに出来るはずです。 辞書もある程度実行するコードに制限を設ければ、配列で実装する事は出来るでしょう(もともと配列にstreqで実装していたのと同じような物にすれば良い)。
するとmallocが無いような環境でも実行出来ると思います。
ElementArrayをファイルにする為には、ElementArrayから別のElementArrayを参照しているところをどうにかしないといけません。 たぶん実行可能配列を順番に並べて1から順番にインデックスを降って、このインデックスで参照するのが良いと思います。 この辺は普通のJavaのクラスファイルやelfなどの実行ファイルの形式を参考にすれば実装自体は難しく無いと思います。
おまけ: repeatの実装方法について考える
現状のrepeatは結構無駄が多く、例えば10000回くらい何かをrepeatしようとすると、10000要素の配列を作ってしまいます。 1万でも数十kバイト程度なので、現実的にはどうという事も無いのですが、 本来はループの回数分の配列なんていらないはずです。 何より現状の方式では、実行時にmallocが必要になってしまう。
でもrepeatを実行時にコードを生成せずに正しく実装するのが、考えてみたらなかなか難しい。 この難しさを理解するのは勉強になるので、考えてみても良いと思います。
repeatという命令は、ループのカウンタをどこかに持っておく必要があります。 これがwhileと違うところです。
whileはコードをjmpしていくだけで実行出来る。condをexecした時に結果の数値は出てきますが、 これはスタックの一番上にある事が保証されている。 repeatはbodyがスタックに何をおいているかを一切知らないので、スタックをこの目的に使うのが難しい。
この、コードとメモリ上の変数の区別、というのは、プログラム言語においてはかなり重要なところでありながら、 入門時にはなかなかわかりにくい所だと思います。 このrepeatの実装の難しさは、コードではカウンタが保持出来ない、という所に本質があるので、これを考えてみるのに良い題材になっていると思う。
さて、repeatのカウンタを適当な変数として持っておこう、と思ったとします。 でもrepeatのbodyの中でもrepeatは呼ばれうるので、2つのrepeatでは別々のカウンタを持つ必要があります。 さらに同じコードの場所でも再帰呼び出しなどで頑張ると同じ場所のrepeatを二度呼ぶシチュエーションも作れるかもしれません。(あんまり真面目に考えてないので本当に出来るかは知りませんが)。
こうして考えると、このrepeatの呼び出しごとに変数が作れる必要があります。 それは概念的には、continuation stackの位置ごとに別々の変数が作れれば良い、という事になります。 これは普通の言語処理系での関数呼び出しのローカル変数と同じ事です。
一番手抜きな実装としては、Continuation構造体にこのループのカウント用変数も持たせてしまう事だと思います。
struct Continuation {
struct ElementArray *exec_array;
int pc;
int local_var;
};
このlocal_varはループが無い時も持たれるので無駄ですし、repeatでしか使わないので、いかにももったいない。 ただ、PostScript的には他に使う事も無いので、これで良いかもしれません。
この変数への保存とこの変数からの取り出しを、例えば以下のような命令として実装したとします。
| num1 | save_local | - | num1を現在の継続のlocal_varに保存 |
| - | load_local | num1 | 現在の継続のlocal_varをスタックにプッシュ |
これを使えばたぶんrepeatは、コンパイル時にこれらの命令やjmp_not_ifなどに展開する事で実装出来るでしょう。(やってみてないので出来ないかもしれませんが)
このsave_localとload_localに相当する命令さえ作れれば、実装方法は他の方法でも構いません。 構造体に入れるのでは無く、継続の位置を名前にした名前をキーにdictに入れる、とかでも同じように実装出来るはずです。
ただこういうのを頑張るのはもはやPostScript的では無いな、と思うので、今回はやりません。 例えばJavaのバイトコードなどではrepeatのbodyを実行したらスタックがどうなるかはコンパイル時に決まっています。 この制約があればjmpで実装出来るので、仕様の方を考え直す方が良い気はする。
ただこの継続に何かぶら下げざるをえない、というのは良くある事で、大抵の言語処理系に、普段は使わないけどある特殊な時に使う何かがContinuation構造体にぶら下がってる、というのを見つけられると思います。