Tiny SIMTを作ろう
あらすじ。
System Verilogを書くぞ!でmipsを作ったが、せっかくFPGAをいじるならもっと並列度の高い事をやりたい。
という事でおもちゃのSIMDプロセッサを作ろうと思う。これをTiny SIMDと名付ける。
追記: SIMDなのにスレッドあるっておかしくない?と言われて調べたら、これはSIMTと呼ぶのが正しい用語らしい。知らなんだ。という事でTinySIMTと呼ぶ事にします。
何を作るかを考える
まず作ろうと思ってる物を何も考えずに書き出してみる。
漠然としているが、4スレッドのSIMTを作ろうと思う。 データパスは4つの複製を持つ、という感じで。 目標としてはDRAMにJTAG越しか何かであらかじめ置いた画像データのヒストグラムを計算するプログラムを動かす、くらいにしておこう。
用語としては一つのスレッドをSPと呼ぼう。
コードはROMから読む事にし、DRAMはSRAMとの転送を明示的に行って使う事にする。 だからキャッシュは無しで。
ブランチ処理を考える
ブランチの処理はSIMTっぽくどっちも実行される、という風にしたいのだが、 アセンブリ的にはどういう動きになるんだろう? 無制限のジャンプでは実現できないような? 考えてみるとCUDAレベルでしか挙動を理解してないな。
for文とif文が出来れば良いので、この命令から考えるか。
先へのbeqは間の命令をnop化する事で全SPで同じpcが使えるな。 そうか。前に戻る時も自分が動くまではずっとnopしてればいいのか。 つまり各SPは次に実行すべきpc(これをpcCandと呼ぼう)を用意していて、自分のpcCandより小さい命令はnopしていけば良いか。
branchとしては各SPのうち、一番小さいものが優先される。 そこからPCPlus4の間は順番に進み、branchの都度4つのSPの一番小さいpcCandが優先される。
おぉ、詳細は考える必要があるが作れそうな気がするな。
ジャンプは全SPが必ず一緒に動かなきゃいけない、という制約をつければいいかな。
追加する命令についてざっくり考える
他のSPがSRAMに書き込んだものが見えるようになる為には、バリアが要るな。 単一サイクルならその場で見えるから平気か。
パイプライン的には4回nopすれば良さそうかな。何にせよアセンブリ的には疑似命令でもsyncを足そう。 これを実行するとそれ以後は全SPのSRAMへの書き込み結果が見えるとする。
あとはSPのidが要るな。これは命令というよりはレジスタでいいか。31番をSPのIDとする、とかでいいか。
あとはDRAMからSRAMへの転送が要るな。 イメージ的には各SPが二次元画像の適当な行の範囲をコピーする事でSRAM上にタイルを作り、それを処理したい。 この転送ははみ出した時には勝手に0でも詰めておいて同じ幅をコピーすると割り切ってしまって良い気がする。
DRAMの開始アドレス、SRAMのコピー先アドレスの二つがあればいいか?一応幅も指定するか? 雰囲気としてはlw命令みたいなのでいいよな。
DRAMに戻す場合は端の端数の処理が要るから幅が要る気もするが、その位はパディングしてしまえ、という気もするか。DRAMはどうせ余ってるだろうしな。 SRAMにコピーする場合は幅は要るか。
じゃあimmは幅にするか。
d2s $sramaddr, $dramaddr, #width
こんな感じか。逆はこうか。
s2d $dramaddr, $sramaddr, #width
拡張アセンブリまとめ
作業しつつ間違いに気づいて直していったりしているので、最新の情報が分かりにくい。という事でここでは時系列では無く最新の情報をまとめる事にする。
opコードとニモニック
mipsで自分がサポートしてない命令のオペコードを、DMAなどの為に使っている。
| 使い方 | オペコード | メモ |
|---|---|---|
d2s $sramaddr, $dramaddr, #width |
110001 (49) | DRAMからSRAMへのコピー。widthはワード単位(1widthで4バイト) |
s2d $dramaddr, $sramaddr, #width |
111001 (56) | SRAMからDRAMへのコピー。 |
halt |
001110 (14) | CPUを終了する。DRAMアクセスをjtagに切り替える。 |
muli $rt, $rs, imm |
001010 (10) | [rt] = [rs]*imm sltiのopコードを流用。 |
DRAM回りを調べる
DRAM周辺は良く分かってない。
クロックが違うから注意が必要だよ、と教えてもらう。
通信はシンクロナイザ的なのを挟まないといけないのだろう。 普通はFIFOを挟んで来るまで止まるように書く、とか言われたが全然分からん。
JTAGでDDRに書き込むコードは昔書いた事があるとの事なので、教えてもらう。以下。
shuntarot/arty-mig: Arty FPGA sample
全然分からん。まずはこの辺といろいろ聞いた事をググる所からか。
IP生成回りの資料
とりあえずAXI4でつなげるものらしい、との事だが、これを知らんので、まず以下を読む。(追記:これはハズレ)
Xilinx: AXI Reference Guide(pdf)
良く分からん。 AXI4のpdfを読むのが先決っぽいが、もうちょっとこう、ゆとりっぽく始められないかなぁ。
お、動画発見。
https://www.xilinx.com/video/hardware/creating-memory-interface-design-vivado-mig.html
なるほど、こういう感じか。さらに同じようなハウツー的なpdfを本家で発見。
Zynq-7000 AP SoC および 7 シリーズ デバイスメモリ インターフェイス ソリューション v2.3
だいたい上の動画と同じような内容だが、とにかくこういう感じでIPを作ってつなげる、という事は理解出来た。
さきほどのJTAG越しにDRAMに書くコードも読めば分かりそうという気分にはなった。 ただコードを読む前に実際にウィザードで作ってみて結果を眺めたいね。
AIXの資料
AMBAの仕様書も読む。リンクがいかにも変わりそうな奴だったので自分がダウンロードした手順を。 まず以下に行く。
そしてLatest AMBA Specificationsというリンクをたどり、AMBA 4のAMBA AXI and ACE Protocol Specificationというのを読んでみた。 どうもこれで正解っぽい。
これは大変良く書けていて、最初からこれを読んでおけばよい、というたぐいの奴。 ただちょっと一般的すぎるので、もうちょっと軽くまとまっているのを途中で参照したくなり以下を見る。
AMBA 3.0に追加された高性能バス用のAXI仕様 ―― チャネル方式を導入し従来のAMBAバスから大きく変更|Tech Village (テックビレッジ) / CQ出版株式会社
だいたい基本は理解出来たかな。
ただAXIの仕様の上限と実際のDDR3の上限はたぶん一致してないよな。 まずIP生成して叩いてみるのがいいのかなぁ。
FIFOとかclock domainとか
FIFOとか非同期
- http://www.sunburst-design.com/papers/CummingsSNUG2002SJ_FIFO1.pdf
- http://www.sunburst-design.com/papers/CummingsSNUG2002SJ_FIFO2.pdf
概要は1を読む。実際の実装は2の奴を実装するのが良さそうか?FIFOはこの二つだけで良さそう。
なんかググってたら見つかった講義のスライドだが、10ページ目あたりを見るとどういう物かわかる。
そのほか幾つかyoutubeでググってみてみたが、いまいちなのしか引っかからなかった。
必要な物について漠然と考える
FIFOを作ろうと思っていたが、よくよく考えるとDRAMとの転送は全スレッド同時に起こるのだから、CPUは全部止めていいはずだ。 だから必要なのはFIFOじゃなくて、同じSRAMなりBRAMなりをDMAっぽく転送する仕組みだよな。
もっと理想を言えば、lwとかswが来るまではばんばんs2dやd2sを発行して、 バースト長まで行ったらプロセッサ側を止めて転送をする、みたいな挙動がタイルを埋めるなら理想だよなぁ。 それってどのくらい難しいだろう?
むしろDRAMとの送受信は明示的に待つか。dsyncとか作って。 ただバースト長を計算して毎回そこでdsyncを書くのは辛いので、バースト長いっぱいになったらプロセッサは止まって欲しいな。 いっぱいになったら止まる、というのは結局FIFOか。ただ結果を置くのは共有SRAMでいいよな。
これならfor文でd2sでタイルを埋めて、dsyncし、以後はsramでいろいろ作業をして、 最後にs2dで結果を戻す、という感じで書けるので、かなりCUDA世代的にも納得のプログラムモデルだな。
ワープに相当するものが一つしか無いので、理想的にはタイルを処理している間に次のタイルをロード出来る方が良い。 イメージ的には、以下のように書ける方が望ましいが、、、
for(最初のタイル) {
d2s();
}
dsync;
for(次のタイル) {
d2s();
}
for(最初のタイル) {
最初のタイルの処理
}
dsync;
だがこれはプログラムする側的にも複雑すぎるよな。 もっと初歩的に、
for(全タイル) {
// タイルを埋める
for(今のタイル) {
d2s();
}
dsync;
// タイルの処理
for(今のタイル) {
処理;
}
ssync;
// 結果の書き戻し
for(今のタイル) {
s2d();
}
dsync;
}
くらいで十分か。 なんかだんだんと収拾がつかなくなってきたな。
この辺でとりあえず動かす目標を決めるか。
目標とするアセンブリを考える
いろいろとやりたい事が膨らんできてるが、そもそもこれは勉強目的のおもちゃプロセッサだ、という事は忘れてはいけない。 そもそもに掛け算とか剰余とかjalとかjrが無い。 必要に応じて実装しても良いが、学習効果が低いものはなるべくやりたくない。
そこでとりあえず実装する気になるサブセットを考える為に、具体的に動かすものを先に決めよう。
今考えているのは、matmulとヒストグラムの二つ。
ヒストグラム
疑似コードで書くと以下みたいな感じか?
$result_base = 64K-256*4;
$result_cur = $result_base + $tid*256;
for($i = 0; $i < 256; $i++) {
$sram[$result_cur+$i] = 0;
}
for($block = 0; $block < 640*480/(BARST_WIDTH); $block++) {
if($tid == 0) {
$dbase = $block*BARST_WIDTH;
d2s($0, $dbase, BARST_WIDTH);
}
dsync;
for($idx = 0; $idx < BARST_WIDTH/4; i++) {
$bin = $sram[$idx*4+$tid]; // 1byteロード
$sram[$result_cur+$bin] += 1;
}
}
ssync;
$origin = $result_base+$tid*256/4;
for($i =0; $i < 256/4; $i++) {
$i = $sram[$origin+$i];
$i += $sram[$origin+$i+256]
$i += $sram[$origin+$i+256*2]
$i += $sram[$origin+$i+256*3]
$sram[$rogin+$i] = $i;
}
結果はdramに書き戻すのが普通だが、今回はホストとか無いのでsramのままでもいい気はする。
対応してないのとしては、4で割るのと掛け算があるな。 掛け算は要るなぁ。 畳み込み出来ない奴は、4と256とBARST_WIDTHを掛けてる奴か。 シフトで行けるか?BARST_WIDTHがまだ分かってないが。
multを実装するのはいいんだが、hiとかloを使う気は無いので、レジスタに下半分入れる感じにする。 定数しか掛けないならmuliでいいか。
右シフト(srl)、muli、lbくらいか。この位なら大きな変更なしで行けそうだな。 いや、lbほんとうに要るか?各スレッドが4バイトずつ処理すればいい、という気もするな。これなら右シフトとandでandはもう実装してある。これでいいか。 じゃあ要るのはsrl, muliの二つだけか。
なかなかSIMTっぽくて、この位動けばいいよな。 1スレッド版と両方作って時間を比べたいね(まぁ転送コストがほぼ全てだろうから違いは出ないか?)
あとdramとの転送をしている間にsram上の処理を回すように直すと早くなるかとかも見てみたいな。
matmul
とりあえず昔書いたCudaのコード
Matrix Multiplication for CUDA explanation
を参考に、変更してみる。
#define TILE_WIDTH 16
// Compute C = A * B,
// DRAM上に、行列A, 行列B, 行列Cと連続で置かれているとする。Cは結果。paddingとかは適当。
// 4K境界とかは今は考えない。
// この辺はとりあえず定数とする。あとでDRAMの先頭に置くかも。
int numARows, int numACols,
int numBRows, int numBCols,
int numCRows, int numCCols
int sizeA = numARows * numACols;
int sizeB = numBRows * numBCols;
int numTiles = (numACols - 1)/ TILE_WIDTH + 1;
/*
この三つはsram上で16*16*4バイトの領域。
*/
$tileA, $tileB, $tileC;
// trowとtcolはC上のタイルのインデックス。
for ($trow = 0; $trow < numCRows/TILE_WIDTH; $trow++) {
for($tcol = 0; $tcol < numCCols/TILE_WIDTH; $tcol++) {
/*
Aは上から$trow番目のタイルを左から右に動かし、Bは左から$tcol番目のタイルを上から下に動かす。
この動かすインデックスが$tile。
*/
for ($tile = 0; $tile < numTiles; $tile++)
{
/*
Aの上から$trow番目を横にタイルを埋めていく。横方向に何番目かは$tileが表す。
*/
for($i =0; i < TILE_WIDTH/4; $i++) {
$inTileLine = $i*4+$pid;
$tileLineABegin = ($trow+$inTileLine)*TILE_WIDTH*numACols+$tile*TILE_WIDTH;
d2s(A[$tileLineABegin], $tileA[inTileLine], TILE_WIDTH));
}
/*
端よりはみ出している部分は0で上書き。省略。
*/
/*
Bの左から$tcol番目のタイルを下に向かって埋めていく。下方向に何番目かは$tileが表す
*/
for($i =0; i < TILE_WIDTH/4; $i++) {
$inTileRow = $i*4+$pid;
$col = $tcol*TILE_WIDTH+$inTIleCol;
$row = $tile
$tileLineBBegin = ($tile*TILE_WIDTH+$inTileRow)*numBCols+$col;
d2s(B[$tileLineBBegin], $tileB[$inTileRow], TILE_WIDTH));
}
/*
ここも同様に端からはみ出た所を0で埋める。省略。
*/
dsync;
/*
$xと$yはタイルの中のインデックス。
*/
for($iy = 0; $iy < TILE_WIDTH/4; $iy++) {
$y = $iy*4+$tid;
for($ix = 0; $x < TILE_WIDTH; $x++) {
for (int i = 0; i < TILE_WIDTH; i++)
$tileC[$y][$x] += $tileA[$x][i] * $tileB[i][$y];
}
}
}
ssync;
for($iy = 0; $iy < TILE_WIDTH/4; $iy++) {
$y = $iy*4+$tid;
$globalY = $trow*TILE_WIDTH+$y;
if ($globalY < numBCols) {
s2d(C[$globalY*numBCols], $tileC[$y*TILE_WIDTH], min(TILE_WIDTH, 端までの幅));
}
}
}
}
うーむ、出来たは出来たし、頑張ればこれをフルアセンブリ書くのも出来るとは思うが、 それを動かしてプロセッサの方までデバッグするのは辛いなぁ。 実装的にはレジスタ同士の掛け算、multくらい追加すればいけそうだが。
これはちょっとおもちゃの域を超えてしまっている気もするな。 命令セット的にはこれをサポート出来るような物を考えるが、ここまでの実装はたぶん無理かな。
とりあえずヒストグラムを動かそう。
最初に作る物を考える
さて、いざ作ろう、と思ったが、DRAM周辺がなかなか難しく、手が動かせないでいる。 とりあえず動くまでに必要な事が多すぎるので、 もっと小さく始めたい。だがどう始めたらいいか分からない。 という事で少し時間を掛けて方針を考える事にする。
DRAMは外からデータを置く為の方法(jtag越しの接続)とCPUに転送する方法という二つのやる事がある。 だからまずこの二つを最低限動く形にするのが良かろう。
ヒストグラムでは転送は1スレッドだけで十分なので、最初は一リクエストでも良いはず。 ただ長さはまとめて送りたい。
XilinxのDRAMアクセスではコードが生成されるのだが、ここにはAXI4とUIという二つのインターフェースが選べるようになっている。 UIは単にデータを読み書きするだけの簡単なインターフェースになっているが、バーストとかは無い、という感じ。 最初はこのUIで転送する方がいいかもしれない。
コントローラにDRAMのアドレス、SRAMのアドレス、長さを置いておくと、ステートマシーンで1単位ごとコピーしていく、その間CPUは止める、という感じで良かろう。
うむ、まずはDRAMのコントローラとjtagでの転送を作る所からだな。 これならテストも出来そうな気がする。
単一サイクル単一スレッド版
という事でmipsのサブセットに独自命令を追加してdmaを足そう。 プロセッサはパイプライン版だといろいろ面倒なのでまずは単一サイクル版を使う。
IP回りの試行錯誤1
とりあえずUIを作ると決めたので、migを使ってDRAMのIPを生成する。 基本的には以下の動画を参考に。
https://www.xilinx.com/video/hardware/creating-memory-interface-design-vivado-mig.html
Vivadoのフォルダの中にdata/boards/board_files/arty-a7-35/というサブフォルダがあり、 この下にmig.prjというのがある。 自分のFPGAはarty-a7-35なので、これが自分のFPGAのメモリインターフェース生成の設定っぽい。 という事で分からない所はこのファイルの中身を真似する事にする。
以下ウィザードでやった事を簡単にメモ。
IP CatalogからMIG 7のウィザードを起動する。
Component Nameはmig7で。 AXI Interfaceはとりあえずdisable(UIしか使わないので)。
次のPin Compatible FPGAsは何もチェックせずに次へ。 次はDDR3 SDRAMを選ぶ。
次のOptions for Controller 0は分からない項目も多いので上記prjファイルの内容をほぼそのまま真似る。 PHY to clock controller ratioは4:1に変更。Memory PartはMT41K128M16XX-15Eに変更。 Memory Voltageも1.35Vに変更。Data Widthは16に。 Number of Bank Machineは良く分からないので4のままにしておく。 OrderingはNormalで。Memory Detailは以下になった。
Memory Details: 2Gb, x16, row:14, col:10, bank:3, data bits per strobe:8, with data mask, single rank, 1.35V,1.5V
次のInput Clock Freqはprjファイルでは166.6666 MHzになっているが、この値はなんだろう? 動画では500MHzを選んでいるので、DDRのクロックではないと思うんだよなぁ。 外から入れるクロックであって、内部では適当に変換されて166MHzになるんじゃないかな?
ちょっと分からないのでこのままデフォルトの310.078MHzのまま進めてみよう。
Output Driver Impedance ControlとRTTはprjファイルの真似をしてRZQ/6に変更しておく。 意味は分かってない。 他はそのままで次へ。
次のSystem ClockとReferential Clockは良く分からないのでDifferentialのままにしておく。 Internal Vrefはprjに従いチェックする。他はそのままで。 こういうデフォルトとprjの設定を変に混ぜるのは大丈夫なのかなぁ、とちょっと不安にはなるが分からないので仕方ない。
次は50オームのまま。
Pin/Bank selectionモード。ここはNew Designを選んでみる。ここが一番分からない所なのだが。 次のBank settingはそのままで次に進む。ここは動画を信じる。
次のSystem Signal Selectionはさっぱり分からないが、適当にかぶらないように以下のように選ぶ。 clk_ref_pにはA10/A9。 sys_rstはA11。init_calib_completeはA15。tg_compare_errorはA16。
次はOut of context per IP。
生成したものに何を入れたらいいか良く分からないな。 まずprjファイルを参考に、TimePeriodを3000に変更し、Input Clk Freqを166.6666MHzに変更、System Clockとref clockをno bufferにしよう。
でこの二つのクロック、どちらかはDRAMのクロックでどちらかはUIとかを動かすクロックなんだよな、たぶん。 教えてもらったjtagで転送するコードを見るとsys_clkに166Mhz, ref_clkに200MHzを入れている。 sys clkはInput Clk Freqで指定したものか。数字的にはDRAMのクロックっぽい?
ref_clkはなんだろう?Time Periodで指定されているクロックに見える。 このTime Periodってなんなんだろうな。良く分からん。まぁいいや、clock wizardでこの二つのクロックを生成してつなげてみよう。
clk_out1に166Mhzを、clk_out2に200MHzを指定しよう。これはいい。 問題はinputだな。CLK_INをsys clockにし、EXT_RESET_INをresetにする。CLK_IN2はそのままいじらず。 そのままgenerateしてみた。まぁ平気か?
次はjtag。あれ?jtagはaxiとつなぐ感じになっているな。 UIとはつなげないのか?ID_WIDTHだけ4にして他はデフォルトのまま生成してみる。
そしてなんとなくつないでみて、合成してみる。
とりあえずエラーで合成出来ない。 メッセージは以下のように出ている。
[DRC BIVC-1] Bank IO standard Vcc: Conflicting Vcc voltages in bank 35. For example, the following two ports in this bank have conflicting VCCOs:
ddr3_ck_p[0] (DIFF_SSTL135, requiring VCCO=1.350) and led[1] (LVCMOS33, requiring VCCO=3.300)
ddr3_ck_pとledでVccが違う、と言っているように見える。 聞いたらどうもbankというので電圧は揃えてないといけなくて、普通ledは35、DDRは34とかじゃないか、みたいな話に。
以下のpdfにpinとバンクの関係が載っている。
https://japan.xilinx.com/support/documentation/user_guides/ug475_7Series_Pkg_Pinout.pdf
確かに自分のmigウィザードではbank 35にassignされている。 このピンはfixedらしい、という事で、Pin/Bank selectionモードでNew Designがダメだったらしい。 全部手で設定するのはかったるいなぁ、と思ったら、手作業で生成したxdcファイルをもらってこれを読み込んだらピン指定が出来た。
で、Run Implementationしたら、
[Timing 38-282] The design failed to meet the timing requirements. Please see the timing summary report for details on the timing violations.
とか言われた。
warningでなんかresetピン回りの所で何か出ていて、ボードのmig.prjはNo connectionになってるな。 ウィザードに戻ってこのアサインをなくしてみる。
Bitsteramの生成までは出来たヽ(´ー`)ノ
プログラムしてみよう。どうやるんだっけ? Open Hardware ManagerでデバイスにAuto connectする。 次にProgram Deviceを選び、 TinySIMT.runs/impl_1/tiny_simt.bit を選ぶ。
で、なんかプログラム出来たっぽいが動作確認方法が無いな。
なんとなく上記jtagでDDRをテストするレポジトリのmwとかmrを動かそうとしたが、
> get_hw_axis
WARNING: [Labtoolstcl 44-226] No matching hw_axi were found
とか言われる。 ltxというのを設定してrefreshしたら、以下のメッセージが。
INFO: [Labtools 27-1434] Device xc7a35t (JTAG device index = 0) is programmed with a design that has no supported debug core(s) in it.
何故debug coreが見つからないのかはよく分かってないが、とりあえずここまで来た結果割と理解が高まり、 教えてもらったjtagとDDRのテストのレポジトリの中身を大分理解出来るようになったので、次はこれを動かして違いを見てみよう。
jtagとDDR接続するサンプルコードを動かす
友人が公開してくれてる、jtagと通信するコードのサンプルが以下にある。
shuntarot/arty-mig: Arty FPGA sample
当初はいまいち理解出来てなかったが、同じ作業をGUIでやった結果、それぞれの手順が何をしているかは割と理解出来た。 あとtclとmakeをインストールするのが面倒、と思っていたが、 このtclはvivadoの内部にあるtclで、vivadoにオプション渡すと起動するという事を理解した。 他の言語だと言語環境をインストールしてライブラリをロードするので無意識にそうだと思っていたが、 tclは組み込む形式の方が多いのだった。
まず、ipディレクトリに行き、powershellからvivadoをtclモードで立ち上げる。 以下の感じ。
C:\Xilinx\Vivado\2019.1\bin\vivado.bat -mode tcl
そしてMakefileを見るとarty.tclを実行する模様?sourceコマンドでやってみよう。 outputディレクトリが無い、と怒られた…作っておこう。
なんか14分もかかった…まぁいい。 次はBitstreamの生成。synの下に行って、outputをmkdirしてからtclを立ち上げて、またarty.tclをsourceで実行。
出来たっぽい?次はFPGAをつなげてprogram.tclを実行。出来たっぽいな。
さて、この時点でltxを指定すればjtag越しにmrやmwが動く、というのが自分の理解。試してみよう。
まずtest/01_axi_rwの下にcdしてtclを立ち上げる。
そしてrun.tclの冒頭のコード片を、PROGRAM.FILEをスキップして実行する。
set dev 0
set bit "../../syn/output/arty_top.bit"
set ltx "../../syn/output/arty_top.ltx"
open_hw
connect_hw_server
open_hw_target
current_hw_device [lindex [get_hw_devices] $dev]
set_property FULL_PROBES.FILE ${ltx} [lindex [get_hw_devices] $dev]
refresh_hw_device [lindex [get_hw_devices] $dev]
そうしたら以下のような出力に。
INFO: [Labtools 27-2302] Device xc7a35t (JTAG device index = 0) is programmed with a design that has 1 JTAG AXI core(s).
お、ちゃんと認識しているな。自分のケースと何が違うのかはまだ理解出来てないが、別にウィザードを使わないといけない理由もない。 次にjtag越しのmrとmwが動くかを試してみよう。
source io.tcl
mw 0 1234
mr 0
1234が帰ってきた。よしよし。
マシン語とアセンブラを決めて、対応する
まずは単一サイクルのプロセッサでデバッグとかしつつ動かすので、それに最低限必要なマシン語だけ決める。 d2s、s2d、dsyncだけあればいいか(dsyncは要らないが、コードの互換性の為決めておく)。
付録BのMIPSのアセンブリを眺めると、FPコプロセッサへのロードとストア、というのがあるな。 これは今回の例では要らないので、このバイナリ値を使わせてもらおう。 という事で、
d2sはオペコードが110001(49)、s2dはオペコードが111001 (56)としよう。
dsyncはsyscallを使うか。ssyncはbreakかでいいか。 という事でdsyncは001100 (12)、ssyncはまだ使わないが001101 (13)としておこう。
d2s、s2d、dsyncを簡易アセンブラに実装する。 ここはあとで上で書いたアセンブリのメモと統合しよう。
アセンブラは完成。
単一サイクルのプロセッサを持ってきて動かす
とりあえず一番簡単な、単一サイクルのプロセッサをつなげる。 以前作った奴を持ってきて手直ししてテストベッドで動かす。
今回のコマンドラインの環境で動かす為にいろいろ整備。 元のgithubではmakeを使っているがそんなものは無いので、PowerShellファイルで簡単なスクリプトを作る。
compile.ps1でコンパイルとelaborateをやる(後者が何かはよく分かってない)。 run.ps1で実行する。clean.ps1でクリーン。
一応単純なaddが動く所までは確認。 おぉ、GUIより大分早いな。こちらの方が良さそう。
シミュレーションではDRAM回りはめんどくさそうなので、プロセッサ回りだけやっておいてipが絡むのはFPGAで動かしてしまう事にする。ゆとりなので。
単一サイクルプロセッサとDRAMのつなげ方を考える
次にこのプロセッサをDRAMとつなげる方法を考える。 プロセッサからはsrc_addr, dst_addr, widthとコマンドの線を出す。 アドレス自体は32bitも要らないはずなんだが、まぁ32bitにしとくか。
で、リクエストが来たらプロセッサをストールさせて、状態マシーンが転送の面倒を見る、という感じでどうだろう。 ストールから再開する時に同じ命令が来ないようにする必要があるな。 ストールしたらinstrを0(nop)にしてPCのフリップフロップを止めれば十分か? 再開した時もう一回メモリの命令が呼ばれそうな気もするな。ここはちょっと考える必要がありそう。
DMACのような物を作れば良さそう。 DDRの読み書きはとりあえず4バイトずつ、jtag越しに読み書きするのと全く同じ仕組みでやろう。 jtagの線とDMACの線をマルチプレクサでつなげる感じ。
d2sとs2dは分けて考える方が良さそうだな。
書いていて、jtagとCPUの切り替えはCPUのhalt的な状態が欲しくなる。 halt命令も追加して、haltピンを出すかな。
haltはsyscall, breakの次という事で001110にしよう。
d2sのwidthはワード単位(4バイト単位の幅)としておく。 本来はバイト単位が良いのだろうけれど、どうせやらないと思うので、ミスの余地が無いように。
実機でのテスト方法を考える
構成要素のテストはシミュレーションでは一応動いた。 そろそろ実機でテストしたいが、どうしたもんか。
テストが成功してたらLEDを光らせる、みたいなのを考えていたが、これはtopでやるのは意外と面倒。 それよりはアセンブリからLEDを光らせる方が良さそう。
という事で、sw命令の0x8000_000Xはledにマップする。
- 0x8000_0000:
led[0] - 0x8000_0004:
led[1] - 0x8000_0008:
led[2]
lwはいいだろう。
なおled[3]はhaltしているかどうかにつなげる事にする(halt中はjtagに切り替わる)。
現状はシフトを実装していない事に気づく。lui実装する方が簡単か? luiの場合はluiとoriが要るな。oriは別にaddiでもいいか。いや、ビットがめんどくさいか。oriが要るな。
実装しよう。実装した。
デバッグ作業
という事で一番シンプルな、DMAの間はCPUを止めて、DMA要求は一度に一つで、 CPUはmigのui_clkで動かす、という構成でコードを書いてみた。
いろいろ合成時のワーニングを消したりしている。
こんなシンプルな構成でも思ったよりも大変だなぁ。 DMAはこのままこの単純なのだけで行き、プロセッサの方をSIMTに出来たら終わりでいいかなぁ。 両方ちゃんとやるのは大変過ぎるし、この手の物は、あくまで勉強目的という事を忘れてはいけない。
dmacでfound timing loopというCRITICAL WARNINGが出ているなぁ。 見た感じ状態マシンっぽいが。
リセットボタンの振る舞い
どうもリセットがずっと1だな。 一方で自分のコードは全部リセットが1の時にリセットされると書かれている(教科書の通り)。 うーむ、逆にすればいいのか?
ググっていたら、リセットは普通1で、ボタンが押されている間は0と以下のサイトに書いてあった。 Arty Reference Manual [Reference.Digilentinc]
なるほど、そういうものなのか。どうしようかな。とりあえず自分が書いた所では!ui_clkを食わせてみるか。
一応最後までいってhaltを表すledがついた。
ただそのあとjtagでDDRにつなげると動かない。
ボタンを押したらddr contollerとjtagだけリセットしてみるか。
>ダメだった
シミュレータでddrを動かす
シミュレータではipは動かせないか、動かせるにしても凄くめんどくさい、と思ってあきらめていたのだが、シミュレータ用のモデルがあってmigは動かるよ、と教えてもらう。 しかも元のレポジトリでやってるとの事。
ほぉ、それが出来れば大分いろいろ調べられるな、という事で、真似をしてシミュレータでddrを動かす事にする。
確かに真似してシミュレーションで走らせると動いているように見えるのだが、 calibrationが終わるまで結構時間がかかり、そのあとストップ呼んでからも結構止まらない。 やはり複雑なIPが絡むとテストは大変だなぁ。
最初の段階でarreadyが立ってないとかいろいろ予想とは違う振る舞いを見て、AXIとはそもそもどういう物かを調べている。 この手の正しい挙動を調べる対象があるって大切だよなぁ。答えを知らずにテストを書いても意味が薄い。 DDRをシミュレータで動かすのはたぶん自力ではできなかったと思うので、ここまでは自力ではこれなかったな。
そしてあるチャンネルでreadyが立ってvalidが立った後に、他のチャンネルのvalidを待ってる時にreadyが倒れる、みたいなケースがある事を理解する。 一度でもハンドシェイクが成立したらそれを覚えておく必要があるのだな。
さらにハンドシェイクというのは成立したクロック数だけリクエストが発行されるとみなされるので、 1リクエストの時は一クロックしか成立しないように書かないといけない、という事を理解。なるほど。これはなかなか組み合わせ回路的だな。 fifoの挙動を誤解していたのでこの辺を読み解けていなかった。
ハンドシェイクは1クロックだけ成立するように直してシミュレーションが無事通る。長かった。
実機でもhalt後にjtagで読み書き出来るようにはなった。 だが、ここで期待する値をdramに書き込んでCPUをリセットしても、ledの光り方がfailの時のなので、sramへのコピーは失敗している?
理解が深まったのでシミュレータ上で期待するddrの振る舞いをハードコードしたテストを追加してみると、ちゃんと動く。うーん。これが動くなら実機でも動きそうだけどなぁ。
実機でのトラブルシュート
挙動を理解すべくもっと単純なプログラムに差し替えていろいろjtagから書く値を変えて試したところ、どうも変な値がコピーはされていそう。 なんか0004から読み込むはずが0008や000Cから影響を受けているな。 ビットはばらばらで規則性は良く分からない。
もう少し解析しやすいように、逆にsramからddrへのコピーのテストコードを書いて動かしてみよう。 途中でswのバグを見つける。ALUのctrlにfunctを見ているがopcodeが0の時じゃない時に、immなどを間違ってfunctと思って動く事がある。 まぁいろいろバグはあるな。
という事で直してシミュレーションで動いたので実機に合成してみる。
お、こちらはちゃんと意図通りに動いていて、期待した値が書き込み出来ている。 どういう事だ?さっき直したバグは問題が出るならシミュレーションでも見つかるはずなので影響は無いはず。
とにかくs2dは動いた。d2sのデバッグを続けよう。
s2dが動いたので、DDRからの読み込みでは無くその先、というか切り替えのあたりとかSRAMへの書き込みとかで変になっている可能性も出てきた。
まずddrから読んだ物を別のddrのアドレスにコピーするコードを書いてみよう。 これでビットパターンがどうコピーされるかをjtagで調べられるのでledで1bitを検証するよりはヒントが多くなるはず。
ddrー>sramー>ddr のコピーは正しく動いた!どういう事だ?
sramからいったんレジスタにロードして別のsramの場所に書き込んで、それをddrに書いてもちゃんと書かれている (ただし順番は変えた)。 これは間にbeqとかledへのswが無いだけで動いていないテストコードとほとんど同じ事をやっていると思うのだが… 動かない場所をより詳細に確認すべく書いたコードが動いてしまった。
とにかく、当初思っていたよりもDMAはずっと動いているようだ。ただ何故か最初に書いた二つのテストコードだけが良く分からないバグをつくらしい。
動いた物
- s2d_test.s
- dram2dram_copy_test.s
- dram2dram_register_test.s
動かない物
- d2s_test.s
- d2s_simple_test.s
- d2s_simple_writeback_test.s
どうしようかな。 現状は何か試す都度2時間くらいかかるので、あまり再現条件を絞り込んだりできる気はしない。 一方でより複雑にしていくともうどうにもならなくなる未来も見える。
うーん、もうちょっと他のコードもいろいろ書いてみるかなぁ。
タイミングViolation
その後友人からTiming violation起きてるぞ、と教えてもらう。 おぉ、以前合成した時は起きてなかったが、バグを直している過程で起きるようになったか。
ちらっと見ると回路を少し変えての解決は難しそう。
クロックを落としたいがddrのクロックはいじり方が良く分からない。
方針としては3つ考えられて
- CPUは遅いクロックで動かし、DMACとの間を非同期通信にする
- 真ん中くらいで切った二段のパイプラインを作る
- CPUを以前作ったパイプラインの物に載せかえる
何もない所からやるなら1か2なのだが、3は手元に教科書を見ながら作ったのが一応ある。 なかなか複雑なのでより解析は大変になるが、既にある、というのは大きい。
2は一番簡単な気はするが、ハザード回りとかを教科書の助けなしで作り直す必要がある。そんな難しくない気はするが…
1は変更量は一番少なさそうだがリセットとかをちゃんとsyncするのはやや難しい。 非同期とかの理解度がより要求されるので、いかにもハマりそうな気がする。
ちゃんと理解して進められるという点では2だが、3の方が手元にあるのでハマらなければ楽という気もする。うーむ。
とりあえずパイプラインを持ってくる路線を考えてみよう。
パイプライン、1スレッド版
パイプラインのプロセッサのファイルを見て方針を考える。
- インターフェースをそろえる
- DMAのIO
- stall
- SRAMを外に出す
- haltを追加
- シミュレーションのテストを持ってくる
- もともとのテスト
- 単一サイクル版のテスト
やっていこう。
シミュレーションを一通り通す
対応してない命令とかちょくちょくあったり、dmaのストール時にflushしてしまったりとかハザード回りは考えないといけない事がそれなりにあったが、なんとか丸一日かけてシミュレーションを一通り動かす所までは出来た。 インターフェースはシングル版と全く同じになったので、結構テストを持ってくるのは簡単になった。
ただddrのモデルはまだ試してない。なんかもう動くんんじゃね?という気分になってきたので合成を仕掛けてみる。まぁだいたい動かないんだが。
トラブルシュートはパイプライン化されると大分複雑になったが、結構ちゃんと理解出来た気がするので、動かせそうな気がする。
もともとパイプラインはやらなくていいかな、と思ってたが、タイミングの問題という実際的な理由でやる事になるのは、ちょっと現実の問題と戦ってる感じがしていいね。
Timing Violation対策
パイプランにしてもちょこちょこviolationがある。へぇ。 見ていくと、いろいろと学びがある。
まずレジスタにすれば良いのにassignにしている結果、前のステートで確定している値なのに間に合わない可能性がある、と言われたりする。 レジスタに直す。
また、ALUは意外とギリギリ。aluの結果にいろいろ処理をするのを次のステートの頭に移動。
regfileはnegative edgeで書き込むようになっているので猶予が半分になる。 この結果、分岐予測回りの処理で間に合わない事がある。これも次のステージに流してその頭で処理する。
その他program.tclでbitファイルが古いままだったりトラブルはいろいろあったが、無事動くようになった!
パイプライン、4スレッド版
現状はDDRを動かすにはパイプライン化するしかなかったので、SIMT化もこのパイプラインで行う方針になった。
作る物をなんとなく書き出す
まずレジスタの31番をtidとしよう。これが一つ目のコアは0、二つ目のコアは1、という風に3までのidとする。
アセンブリでは$tidと書ける方がいい気もするが、まぁ$31でいいか。
分岐の時に自分が実行しないパスはnopとして振る舞う所を考える。 次のPC、というのを各コアが申告して、そのうち一番小さい物が次のPCになる、というのでどうだろう? つまり次のPCは上から降ってくる。
そして自分の次のPCは各コアが保持しておいて、それより小さいPCが降ってきている間はnopとして振る舞う、という感じで良さそうか? instrもSIMTだから上から降ってくるんだよな。
pcとinstrが上から降ってきて、nextPCと比べて小さければ0、そうでなければinstrの処理、でいいか。
共有メモリの実現
4ポートのRAMが欲しいが、普通に書き込みを4つ並べて合成してみたら、それじゃBRAMにならないよ、みたいなエラーで合成出来ない。ふむ、そういうものか。
そもそもに複数のコアから見えるオンチップのメモリって普通はどうやって実現するものなのだろう? 少し考えてみたがあまり分からない。 ググってみると論文とかが当たる。意外と難しいのか?
とりあえずフリップフロップを並べる、という方針で行ってみるかな。 BRAMの説明ではフリップフロップはあまり数が増やせないからBRAMがある、みたいな話だったが、どの位増やせないのだろう? 当初のプランでは64KByteくらいの共有メモリのつもりだったが、最低ラインとしてはどのくらいあればいいのだろうか?
まず256のヒストグラムの結果を置くのだから、256バイトは必須。8ビットではちょっと少ない気がするので、32ビット置きたいな、と思えば1Kバイトとなる。さらに作業用にDDRからコピーする範囲が必要だ。 1KByteくらいあればとりあえずはいいか。という事で2KByteあればとりあえずおもちゃは動かせる。 32バイトのフリップフロップ512本か。うーん、いけるのか?無理な気もするなぁ。 32ビット置くなんて贅沢だ、と思えば16ビットでもいいか(だが16ビットロードやストアを実装する必要が出てくるが)。 これならヒストグラムの結果を置くのに512バイト、作業用にも同じくらいで512バイトとすれば、256本。
行けるかどうかが全然分からないな。
どうせプロセッサは4つしか無いのだし、4bankでバンクがぶつからないように気を付ける、という路線はどうだろう? それだけだとちょっと辛いので、4bank + 4FIFOの構成にして、適当にnopを挟めばやがて終わる、という感じに出来ないか?
プロセッサの数だけfifoを用意し、いつもより若いプロセッサ番号の書き込みを優先する。 一番酷い所は以下みたいになるが、
// fifo3
if(empty3)
cur_re3 <= 0;
else
begin
case(cur_addr3[1:0])
2'b00:
if((!empty0 & (cur_addr0[1:0] == 2'b00))
| (!empty1 &(cur_addr1[1:0] == 2'b00))
| (!empty2 &(cur_addr2[1:0] == 2'b00))
)
cur_re3 <= 0;
else
begin
BANK0[cur_addr3[13:1]] <= cur_data3;
cur_re3 <= 1;
end
2'b01:
...
この位なら動くか?ちょっとやってみよう。 副作用としてswしたあとすぐlwすると古い値が読まれる。まぁ使う側がやさしさをもって使おう。 TinsySIMTの半分はやさしさで出来ている。
swした時はfifoのpushに1 clk、fifoから取り出してbankに書くのに1 clkなので2 clk待たないと正しい値が取れない。まぁnopを挟もう。
追記: これではダメだったので組み合わせ回路で書き直した。クロックの最初の時点でemptyをチェックしても次のクロックの開始時点では変わっている可能性がある。だから開始時点でこれをチェックしてreを立てるのは、その前のreを立てた結果が見れずに空popしてしまう可能性があってこれではダメそう。
制御ハザードについて考える
制御ハザードは、他のコアの事も考える必要が出てくる。何をすべきか考えてみよう。
beqで他のスレッドが先に飛ぶ場合
前へのジャンプの場合、ジャンプするスレッドだけ正しく無視すれば良い。この場合そのコア内でのこれまでのハザード処理で良かろう。
beqで他のスレッドが後ろに飛ぶ場合
他のスレッドが後ろに飛ぶと、先読みしているfetchを捨てる必要がある。 これは現在のpcが自分のpcよりも後ろになる事で分かる。beqはDecodeステージの最後で判明し、 この時はbeqで後ろに飛んだのと同じ処理になる。 つまり、どれか一つのスレッドが後ろに飛んだら後ろに飛んだとみなして読んだ命令を捨てる。
jの場合
jが他のスレッドで実行されて自分が実行されない場合、自分のpcが現在のスレッドより後ろでやってくる命令を無視している状態のはず。 jはデコードステージで決まるので、この時点で実行されてないスレッドは、誤ってfetchが走っている可能性は無い…かな?
と考えると他のスレッドがjした場合は自分は降ってくるpcに応じて処理をするだけで良くて特別なハザード処理は要らない。
まとめ
他のスレッドが前に飛んだ場合だけ、自身がbranchしたのと同じ処理をする必要がある。それ以外は特別な処理は必要無い。
実装
実際に実装していこう。 まずはシミュレーションでちゃんと動かしてからタイミングの問題をつぶしていく。
シミュレーション実装
まずは4コアで、上記のアイデア通りの4 port RAMにつないで動かしてみる。 もともとタイミング違反を回避する為に変な所でフラッシュをしたりしている都合でかなり混乱したが、 最終的には変更量はかなり少ない。
無事出来たので、いろいろスレッドごとに別々の場所にジャンプさせたりするようなテストコードを書いて動かすが、一通り動く。 おぉ、凄いな。 これも感動がある。
なお、テストコードを書く時に、コアidごとに別のアドレスにストアする時に4を掛けたかったので、muliという独自拡張を追加。 オーバーフローするような事はしないのでこれで良かろう。
合成してエラーをつぶす。
動作確認をする前に、実機向けに合成してタイミング違反とかコンパイルエラーをつぶそう。
まず4 Port RAMがその実装ではBRAMにならん、と言われて、途中でレジスタを使い果たしてエラーになる。 16KByteまで減らしてもダメ。8KByteまで減らしたら通りはした。なんかpipelineの時に64KByteまで通ってたので16KByteまで減らせば通りそうな物だが…
で、予想通りPCを申告してminimumを採用して動く所がtiming violation。 いろいろ頑張ったが間に合わず友人に相談した所、pcのビット数を減らせ、と言われる。 減らしてみると確かに間に合うように。おぉ、ビット数減らすってすごい効くな。
あとは掛け算の時のRAWハザードがなかなか間に合わないが、こちらも掛ける側のimmのビット数減らしたりしてなんとか間に合う。 掛け算が結果を特別なレジスタに入れるのは桁があふれるだけが理由じゃないんだなぁ、と知る。なるほど。
そのあといろいろ調整したら一度間に合ったのだが、 デバッグ等で変更するとすぐあふれてしまう。 やはりギリギリ過ぎて開発が辛い。
パイプラインをもう一段増やして抜本的に解決を目指す(後述)。
ヒストグラムを動かす
最終目的のヒストグラムのコードを動かす事を目指す。 必要な事をざっくり考えると以下くらいか。
- アセンブリを書く
- データを用意する
- colbaで適当な写真から32x4バイトのバイナリを用意し、jtag越しにtclで書き込むコードを生成
- readmemhで読み出せるようにもしておく
- 期待値が何になるか、Pythonで計算しておく
- シミュレーションで動かす
- readmemhで読んだ値をsramに書き込んで動かす
- readmemhで読んだ値をdmacに渡して動かす
- 実機で動かす
シミュレーションで動かす
アセンブリが相当複雑だが、reg writeだけdisplay文で出してデバッグしていく。 非効率この上ないが、ハードの方のバグも多いので結局ハードの上でデバッグする方が曖昧さは少ない。
一日くらい掛けてハードのバグを直しつつアセンブリのバグも直した。
すると合成の時にタイミング違反が出るようになってしまい、小手先の調整ではどうにも収まらない。
そこで抜本的に解決すべく、パイプラインをもう一段増やす事にする。
パイプラインをもう一段増やす
これまでは、Fetch, Decode, Exec, Mem, WriteBackの5段のパイプラインだったのだが、 SIMT化の結果Fetchの所がきつくなっている。
4コアから申告されるPCから一番小さい物を選んでROMから値を読みだすのだが、PCの決定で半分以上掛かってしまってROMからの読み出しが間に合わない事が多い。
そこで、FetchをPCの決定とROMからの読み出しの二つのステージに分ける事にする。 これまでFと呼ばれていたステージを、AddressステージとFetchステージに分ける事にする。 Addressステージの略称はAで。
制御ハザードを考える
なんとなく実装してみたら、分岐のあたりがおかしい。 という事で真面目に考える。
だいたい下図のようになるのだよな。
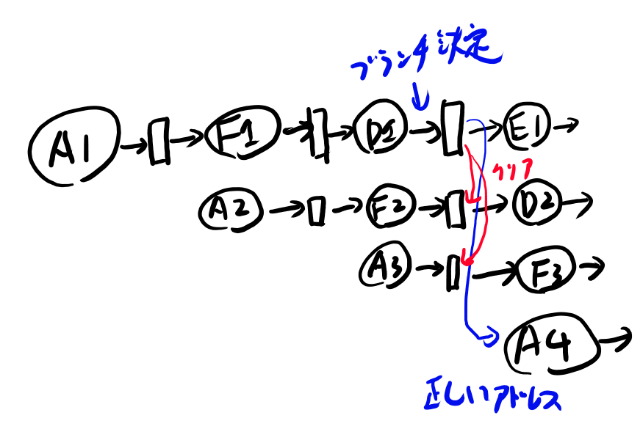
だから、F2のクリアとA3のクリアがしたい。 F2のクリアはこれまでも入っているロジックなので問題はない。
新しいのはA3の所だな。クリアというが、アドレスは0にするともう一回同じのが読み込まれてしまう。 一回Fを無視する、みたいな処理が要るよなぁ。
他のスレッドがブランチした場合を考える
他のスレッドがブランチした時も、制御ハザードと同じような事が起こる。 ただ、他のスレッドはそのまま実行し続ける場合もある。 他のスレッドが後ろに飛んだ場合は自身には影響が無い。 他のスレッドが前に飛んだ場合(戻る場合)は制御ハザードと同じような事をする必要がある。
core0とcore1の二つで考える。 core0がブランチしてcore1がしない場合。 上記の図でA4の時点で正しいアドレスがcore0に来る。
するとcore1はA4の最後では、今選ばれたPCと自分の申告したPCが違う、という事に気づく。
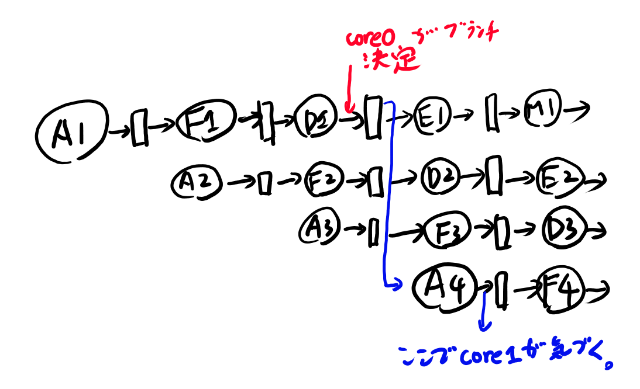
するとcore1は、D2とE2の間、F3とD3の間、A4とF4の間を無効にしたい。 A4の無効はアドレスの無効値が無い問題によりF4の最後でnopに差し替える。
他のコアが、prefetchしてる範囲に分岐した場合
上記の処理を書いた所、core1が例えばA2で、core0のA4と同じアドレスを処理しようとしている場合に、命令が消えてしまう事に気づく。
現在のpc、という概念が中途半端で、本来は現在のdステージのpcが現在のpcの決定版のはずだ。 だが、prefetchの所では二つ先まで進めてしまうので、 まだ終わってない所よりも先にaddressステージのpcは行っていて、そのあとそのprefetchがキャンセルされると、現在のpcとして実行してない空白が出来てしまう。
データステージにたどり着くまでは、そのpcは暫定的な物として扱って前に進めてはいけないのか。
そもそもに、各コアはdecode stageでどのpcを処理するか、だけに興味を持っていて、prefetchがどうこうとかは外に任せるべきだよな。 pcのアドレス計算とfetchはコアの外の仕事で、コアは降ってくる命令にだけ反応すべき。 ただストールとかに必要な情報はコアから出さないといけない。
そう直した。
他のコアのデータハザードによるストール
他のスレッドがデータハザードでストールしている時、 自分はその命令より先のPCにいる為ストールをせずに先に進んでしまう事がある事に気づく。
どれか一つのスレッドがデータハザードのストールをする場合は、自分もデータハザードのストールのようにふるまわないといけないんだな。
実機で動いた!
DDRは一切統合してテストしてなかったので動かないと思ってたが、あっさり動いた。 まぁDMA自体は既に動いていた物なので動いても不思議では無いが。
なんか本当に4コアが動いてて凄いね。 共有のSRAMもキャッシュじゃなくて2クロック遅延で他のコアの作業が見えるし、 割とCUDAっぽい。
今回のパイプラインを一段増やすのは結構抜本的な解決方法だったのでちゃんとやればちゃんと動くとは思っていたけれど、 思った通りにちゃんと動いてちょっと感動した。
割と当初作りたいと思ってた物に近い物が出来たかな。
まとめ
完成したのでなんとなくここまでのまとめを。
作った物の構成
jtag+DDR3+4コアのSIMT。
プロセッサのSRAMとDDR3の間はDMAコントローラがやりとりをする。その間は完全にプロセッサは停止する。 DMAは動けばいいや、という事で非常に低速。
SRAMは4ポートの同時書き込みが出来るBRAM。 バンクがぶつかると次のクロックに書き込みが遅延していく。 FIFOがあふれると変な挙動をする。
プロセッサは
- アドレス決定
- 命令fetch
- デコード
- 実行
- メモリ読み出し
- 書き戻し
の6段のパイプラインで動く。 PCはタイミング違反をつぶす過程で8ビットまで縮めてしまったのでROMは1Kまで。 たぶん今ならもう少し増やしても動くはずだが。
コアはSIMTなので全部同じ命令の上を動く。 分岐などで自分が通らない分岐の時はnopが来たかのようにふるまう(NVIDIAのGPUと同様)。
レジスタ31番にはコアのidが入っている(0~3)。
動かした物とか試し方とか
せっかくなのでREADMEを少し書いてみた。動かし方も以下を見ればわかる人は分かると思う。
karino2:DDCA_exercise/TinySIMT
動かしたアセンブリで一番代表的なのは以下。 結構4コアちゃんと使ったヒストグラムで、 各自の領域に結果を入れた後に、役割を変えて全部足していくのは結構CUDAっぽくて気に入っている。
DDCA_exercise/asm/asm_files/simt_histo32.s
苦労した所
何よりDMAの所が一番苦労した。 AXIが初めてだったのでいろいろ誤解があったとか、FIFOとか初めて使うとか、本質的に難しい部分も多かった。 また周波数が早いのでいろいろシビアだし、ipの回りのウィザードなどの複雑さなど、ちょっとハード屋の友人のサポートが無ければ乗り越えられないレベルだったと思う。(ありがとうございましたm_ _m)
あと4ポートのSRAMもまぁまぁ苦労した。 そもそも何か自分で作らないと実現できない、という事すら分かってなかった。 どういうアクセスだとBRAMになるかが分かってない、という所と、 FIFOでつなぐ、という時の定石を良く理解してない為、一見正しそうだが実はいろいろ問題がある、とう挙動に良く巻き込まれた。 ただ最終的に出来た物は結構良いんじゃないか?と思う。 普通はどうやるのか知らずに適当に思いつきを実装したので、自分で考えて作ったぜ!という感じが強い。 そのうち普通はどうやるかもちゃんと勉強してみたいな。
パイプラインを一段増やす過程でハザード回りを再設計するのもなかなか難しかった。 もともとのパイプラインは教科書に載っている通りだったのであまり深く考えていなかったのだが、 自分で新しく変える為には結構既存の部分もちゃんと考え直す必要があって、かなり良い勉強になった。
全体の感想
VerilogもFPGA開発も初めてだったが、大分慣れた。もう結構普通に書けるとは思う。 やはり自分で考えた(そもそもに間違っている部分を含む)物を作ってデバッグするというのは学習効果は高いですね。 もともとはVerilogとかもっと分かるようになりたい、と思って始めた今回の一連のFPGAいじりだが、予想以上に習熟した。 こんな苦労すると思ってなかったという事でもある(^^;
Verilogとかハード側の理解、という点では、 もうソフト屋としては十分なレベルには到達したかな、とは思う。 今後低レベルの仕事をやる機会があるか分からないが、もしまたやるならこの位理解してるといいやね。
FPGAの開発は思ったよりもハードウェア開発っぽかった。 エミュレータ上で何か作る、というのとはだいぶ違う。もっとゆとりっぽいのをイメージしてたけど、やはりFPGAも実機ですね。 いろいろ動かないし時間はかかるしタイミングやLUTなどのリソースは思っていた以上にシビアだしデバッグの手段は限られている。 一方でASICよりはずっと気楽に進められるので、ありがたみは凄い。 やってて一生ASICは作れんな、と思った。
レポジトリのログから察するに開始が10月2日、今日が25日なので三週間ちょっと掛かった計算になる。 この前にやった、単一サイクルのプロセッサを作り始めてから4段のパイプラインが動くまでが4日だった事を考えると、単純計算では5~6倍くらい大変だった計算になる。 毎日やってたわけでは無いけれど、体感的にもその位の大変さの違いではあった。
他人に言うとパイプラインのプロセッサを動かした、との差分がほとんど伝わらないのでこの前の4日程度の作業量に思われてしまうのが悲しいが、他人に自慢する為にやってる訳でも無いのでいいのです。分かる人にはわかるだろうし。