System Verilogを書くぞ!
読書記録: ディジタル回路設計とコンピュータアーキテクチャを読みながら、いろいろ書いてみる時の記録。 環境設定とか適当にやってしまって記録が残ってないが、心を入れ替えてここからは記録を取る。 FPGAでLチカくらいはやった。
まずVivadoというIDEで開発していく事にする。あまりにもかったるかったらエディタでの開発環境を整えるが、ゆとりとしてはIDEでぽちぽちやりたい。
以後System Verilogを書いて行くが、面倒なのでVerilog、と記す。ゆとりなので細かい事は気にしない。
初めてのテストベンチ
細かなモジュールとかを書いて挙動を調べるのは、シミュレータというのでやる物らしい。 で、シミュレータではテストベンチというのを書いてモジュールをテストするらしい。
という事で、このテストベンチで何かをテストする、というのを書いてみる事から始めたい。 題材としては、書籍の4.9にテストベンチのコードがあるsillyfunctionでやってみる。
とりあえずプロジェクトを作る。 4章の演習問題を全部一つのプロジェクトに入れるのは取り回しが悪そうなので、3つくらいのプロジェクトに分けるかな。 chapter4_1というプロジェクトを作る。
次にsillyfunction.svというファイルを作り、sillyfunctionの実装をへこへこ書く。
テストベンチは普通はファイル分けるらしいが、今回は動作確認なので同じファイルでもいいかな。 ちょっと同じファイルにテストベンチも書いてみよう。
モジュール名はchapter4_1の前半で被らないように、testbench_sillyfunctionにしよう。長いがゆとりなので。
中身としてはとりあえず000と001のテストだけ書いて動かしてみよう。 どうやって動かすんだろう?
Runのアイコン(緑の右三角)を押して、Run synthesisというのを選んでみた。右上の所に Running synth_designって出てくるくる回ってる。しばらく待つか。 お、合成が成功した、と出てきて、三つの選択肢が出てきた。Run Implementationを選んでみるか。
おや、エラーになった。Design is emptyとPlacer could not place all instancesと言われた。
走らせたものが間違っているのか?なんか前はRun simulationというのを選んでビヘイビアがどうこう、とか選んだ記憶があるな。
左のペインにRun simulationというのがツリーのSimulationの中に入っているな。これを選んでみるか。 おー、出来た。波形が見れる。いいね。
少し変えてみた。ちゃんと動いてそう。よしよし。
一応failしたケースの挙動も調べておくか。$errorというのを使っているのだが。assertをfailするように変更。
ん?何も起こらないが。
しばらく格闘した結果、Tcl consoleに出ているが流れて気づいていなかった、という結論っぽい。
$displayというのもあるな。これは標準出力に出す、errorは標準エラー出力に出す、という所か。なるほど。
よし、これで作業を続けていけそうだな。
現状、Run Simulationとやると全テストベンチが流れてしまう。これはちと都合が悪いな。 選んで実行とかできないのだろうか? Disable fileというのがあるな。これでテストをdisableにしておけばいいのか。
演習問題 4.3 xorを実装せよ
やってみよう。xorは予約語だから使えない、と言われた。myxorという名前にするか。
4入力のxor、期待する振る舞いはなんだろう?多入力ゲートは1.5.6節にあるな。 TRUEが奇数個ならTRUEを出力するらしい。
どう実装するのがいいかしら?4入力なら組み合わせは16個か?TRUEになるだけでいいので半数の8個くらいか。 この位ならcaseで書けばいい気もするな。
caseを使う場合はassignでいいんだっけ?4.5.4を見ると、caseを使う場合はブロッキング割り当てを使うのが良さそう。 それぞれの違いを軽く見直しておく。ノンブロッキングは並列に評価されるみたいな挙動か。 一応説明を読み直したが、とりあえず心を無にしてこのガイドラインに従って、always_combの時はブロッキング割り当てを使おう。
caseでは奇数でも偶数でもどちらか一つをセットすれば良い。 奇数個と偶数個はどっちが少ないか?偶数個は2個と4個。4個は一通り、2個は4C2で6通りか? 奇数個は1個と3個でどちらも4通りか。おや。偶数個の方が一つ少ない。まぁ一つくらいならいいか。
よし、出来た。
logic [3:0] a, y;とやったらyも4bit幅になっているというバグを入れてしまっていたが、無事デバッグも出来た。
よしよし。
レポジトリを作ろう
進捗を見せるという点でも、githubに上げておく方が良かろう。という事でレポジトリを作りたい。 プロジェクトのディレクトリを眺めると、chapter4_1/chapter4_1.srcs/sources_1/new の下だけで良さそうか? newってのが何なのか知らないが。
この本の英語名はなんだっけ。DDCAでいいか。ではDDCA_exerciseで行こう。 レポジトリ一つに全部入れたい気もするが、XilinxのIDEの構成と共存するのが難しいな。
シンボリックリンクを貼ったらgitはsymlinkはadd出来んと言われる。そうか。 ハードリンクなら?と思ったがハードリンクはファイルごとにやらないとダメそう。そりゃそうだな。
うーん、逆にxilinxの方のディレクトリをシンボリックリンクにしたらどうだろう?やってみよう。 mklinkコマンド、ちょくちょく出番あるよな。
よし、ちゃんと動いているね。
https://github.com/karino2/DDCA_exercise
4.5 minotiry
少なくとも二つの入力がFALSEならTRUEを出力する。 という事は、~a~bc+~ab~c+a~b~c+~a~b~cか。 簡単化出来るか?~a~b~cがあるから、真の部分はいらないな。 ~a~b+~a~c+~b~cか。ま、この位でいいな。
あ、Verilogはアンドと縦棒か。~a&~b|~a&~c|~b&~cか。
まぁブログ的にはmarkdownに優しいブール代数表記でいいか?
よし、動いた。
4.6 hex display
16進数のディスプレイ表示。例題2.10に10進の表示があるので、変数名などはこれをベースにする。
あれ?Bと8ってどう区別するんだ?Dと0も一緒だよな。小文字にすればいいか? aとかは小文字だと読みにくそうだな。bとdだけ小文字にするか。
ローマ字の所での各セグメントのうち、1になる所だけ列記する。
- A abcef
- b cdefg
- C adef
- d bcdeg
- E adefg
- F aefg
こんなもんか。あとは心を無にしてそのままVerilogでずらずら項を書いて行くかな。 assignをひたすら並べていけばいいか。
aはだいたいあるから無い方を入れる方が楽か。 0になるケースを考えると~0001+~0100+~1011+~1110か。これの否定だな。
うーむ、これをd[0]とかd[1]とかで書くのはだる過ぎるな。case使うか。
あれ?記述例4.24に10進数の例があるな。モジュール名や変数名はこれに合わせるんだったなぁ。 変数名は今からでも遅くないか。 これだと7変数に一気に入れている。どうせcase使うならこっちのほうが楽か。真似しよう。
10進のコードを写経するのがだるいな。まぁこの位は修行と思って頑張るか。
これ、書いたはいいがテストって何書くんだ?入れた値が出てくる、としか書けないよなぁ。 表示できないと盛り上がらないなぁ。手元のFPGAを見たが7セグメントディスプレイは無いか。 LEDはあるが、数字が出ないと盛り上がらないよなぁ、やっぱ。
aの時だけテストして波形を見て満足したので次に行く。
4.8 mux8 (8:1マルチプレクサ)
前に4:1がどっかにあったなぁ、と見直すと、4.2.4の記述例4.5とか4.6でその辺をやっている。 d0とかyは3:0っぽいな。 これもcase文でずらずら書く方が早いな。というかこればっかだな。
次の4.9はy = a~b+~b~c+~abcをmux8で書け、との事。答えを全部ハードコードしろって事か? まあ大した事無いが意味は分からんな。
次の4.10では4:1を使って書け、とある。notはいくら使っても良い、とあるが、別にmux4を3つ並べればnotは使わない気がする。 逆にそれ以外の場合、何が出来るというのか? もともと一行で片付く論理回路をあえてmuxを使うとうい問題なので、何がOKで何がNGか良く分からないな…
その他、mux4版やpriority8なども作る。特に問題無し。
6:64デコーダ
2:4デコーダーを作れ、との事。 2:4ってどういう意味だっけ?と前を見直すと、2bitの値を4ビットのワンホットにデコードする、という意味らしい。 なるほど。 case文で一瞬な気がするな。やっていこう。
次に6:64デコーダを作れ、と言う。 おや、assignを64個並べれば出来るだろうが、さすがにそれは無いだろう。どうしたらいいんだろう?
とりあえず4っつくらい代入してみよう。
assign y[63] = high[3] & mid[3] & low[3];
assign y[62] = high[3] & mid[3] & low[2];
assign y[61] = high[3] & mid[3] & low[1];
assign y[60] = high[3] & mid[3] & low[0];
最後の列以外は一緒なのか。つまりブロードキャストみたいな事が出来れば良さそうだな。 条件割り当て使えば出来るのは分かるが、インストラクションはAND回路だけで出来そうな書き方だよな。
ハードの人に聞いた所、{4{high[3]}}みたいな書き方でいいとの事。なるほど。
ではこれを激しくやっていくとこうか?
assign y = {{16{high[3]}}, {16{high[2]}}, {16{high[1]}}, {16{high[0]}}} &
{4{{4{mid[3]}}, {4{mid[2]}}, {4{mid[1]}}, {4{mid[0]}}}} & {16{low[3:0]}};
相当激しい感じだが、なんか動いている風味だ。
ここまでで4章の演習問題は良しとしよう
だいたいVerilogのコード書き溜めとしては十分なくらい出来たし、デバッグ回りや波形の見方、IDEの使い方なども慣れてきたので、ここでやるべき事はマスターしたといえるだろう。 まだまだ演習問題はあるが、4章の演習問題はここまでにして、次に進もう。
5章 デジタルビルディングブロック
最初はいろいろな加算器を実装したりしようと思ったのだが、なんかこういう普通はやらない事をせっせとやる前に、普通やる事をマスターする方がいいよな、という気になる。 という事でとりあえずALUから作ってみるか。
演習5.9 図5.15のALUを実装せよ
adderとかのVerilogコードはあって途中まで見ながら書いていたが、これは回路図から実装する方がいいか。 という事で、adder, subtractor, comparatorなどを実装していこう。とりあえず32bit決め打ちで。
zero extendはどう書くのだろう?普通にbit連接でいいのかな。まぁそれでいこう。
あ、comparatorは要らないのか。まぁいい。そしてmux2とmux4が要るな。 前のプロジェクトからコピペで行こう。この辺は変に共有せずにdupする方が演習問題の記録としては良かろう。
なんか回路図の通りにつなげていったらあっさり出来てしまったな。めっちゃdeclarativeだなぁ。 むしろこの回路図を書くのを自分でやらんといけない気がするな。まぁいい。テスト書いてみよう。
最初はZZZZZZとかだったが、いろいろ直して全部動くように。 なんかALUが動くと感動があるね。ここより上の世界は結構なじみがあるので、なんかゲートからつながった感があって感動がある。
次は何をやるか
演習問題ではシフタとかいろいろあるのだが、ALUが出来たらもういいんじゃないか、という気がする。 7.3.2のmipsの単一サイクルの回路図を見ていると、組み合わせ回路で必要そうなのは全部書けそうな気がするな。
だが、フリップフロップやメモリ、レジスタファイルは書いていない。これは書いておきたいな。 という事で次は順序回路系の必要な奴を書いてみたいな。
7.3.2の図からまだ書いていないのは、
- メモリ
- レジスタファイル
- PCのフリップフロップ
の三つかな。これら三つを書いて行こう。
まずはPCの為のフリップフロップから。これは簡単なはず。リセット付きの奴を書いておこう。 4.4.2に答えがあるのでうつせばいいのだが、とりあえず見ずに書こうとしてみて、どこでつまるかを確認しておく。
命令メモリとデータメモリは線が違うな。データメモリで代用出来そうだが、練習の為に別々に作ってみるか。 ではまずは命令メモリ。coderomと名付けるか。
ROMを作ろう
という事でROMを作る。
とりあえず書いてみて思ったが、メモリの中身を初期化する方法が無いな。どうするのだろう? 書き込み可にして初期化時に書き込めばいいのかもしれないが。
うーん、本来は外部のメモリは既にあって、そこへのロードとかはCPUを動かす前にやるよな。 FPGAならなんかメモリユニットみたいなのがあって、tclとかで送れるんだよな、たぶん。 mipsの課題の模範解答のファイルを見ていると、ファイルから読みだしているな。 これではシミュレーションでしか動かない訳だが、本番は実際のデバイスのメモリに差し替えるのかね。
readmemh
普通はどうするものなのか気になったのでハードの人に聞いてみた。
どうも$readmemhでファイルから読むようなコードを書いておくと、実際のROMに合成されるらしい。
まぢで!?凄いな、Verilog。
これをどこで読むかというと、initialで読むっぽいな。この辺この本には全然説明無いが、回答例で使われているのはずるい。 ま、この位はググって調べよう。 readmemhでググって以下がひっかかる。
Initialize Memory in Verilog — Time to Explore
なるほど。ただアットマークでアドレス指定出来ると言ってた気がするな。その辺はこっちに書いてある。
Modeling Memories And FSM Part - I
なるほど、そこから先はシーケンシャルになるのか。なんかこのファイルのパーサーとか仕事で書いた記憶があるな。
まぁだいたいイメージはつかめた。
mipsのコード領域を確認
今回はOSを載せたりする訳じゃないので、コード領域はROMをそのままマップすればいいだろう。 仮想メモリもやらんだろうし。
という事でアドレスの範囲とか確認しておく。6.6.1のメモリマップによると0x0040_0000から0x0FFF_FFFCまでだって。 広いな!256MBだって。うーん、そんなROM要らん気もするが。
1ワード4バイトなので、32-8で24bitあれば全部飛べるか。でもROMそんな要らないよなぁ。 由緒正しく64kくらいにしておくか?64K byteの場合、2^6*2^10か。32 bit単位でいくと、16 K ワード。この位でいいか。 アドレッシングとしては、4+10で14bitだな。
回答例を見ると6bitになっているな。64ワード?さすがに小さすぎじゃないか?それは。まぁいい。自分は16Kワードで行こう。 アドレス線は14bit。
ROMは組み合わせ回路として、clk無しでその場で読みだされるとしよう。
一通り実装して動くのを確認。よしよし。
レジスタファイルとSRAM
レジスタファイルはコード例が無いな。SRAMとVerilog的には大差ない感じでいいか。 やってみよう。
まずはinputとoutputを図5.47を参考に決める。こんな感じか?
module regfile(
input logic clk,
input logic [4:0] a1, a2, a3,
input logic we3,
input logic [31:0] wd3,
output logic [31:0] rd1, rd2);
we3の場所をclkの下にするかwd3の前にするか悩ましいが、まぁ適当でいいか。
で、4byteのレジスタを32本用意すればいいんだな。これはlogicでいいか。
割とそのまま書いて、なんとなく動いている風味。
次はメモリ(SRAM)だが、むしろポートが少ないだけで同じだよな、これ。 サイズはROMと同様64K byteとしておくか。アドレス線は14bit。 この辺はテスト書く方がだるいな。
これで7章の単一サイクル版で必要な物がそろったと思う
とりあえずmipsを作るのに必要な要素はそろった気がする。 他にも演習問題とかいろいろあるが、とりあえずここまででmipsを作って動かしてみたいので、CPU設計に入ろう。 足りないものがあったらその都度戻って作れば良いだろうし。
ここまで書くとVerilogの書き方も大分慣れてきて、回路図があればVerilogに翻訳するのは大分出来るようになった。 回路図を書くのがハードウェアプログラミングだという話もあるが。
Vivadoで波形みたりクロックを入れたりしてテストしたり、そういう当たり前の事をあたりまえに出来るようにはなった気がする。 という事で次は一番簡単なCPUを作ろう。
7章の単一サイクルmipsプロセッサ
ここはじっくりやりたい。 個人的に、汎用のCPUを作れるようになる事にはそれほどの意味は感じていないので、 あまりCPU特有の事に深入りするよりは、一番単純な奴をしっかり理解して、 むしろSPU並べたSIMDとか作れるようになりたい。 という事で単一サイクルをまず時間を掛けてやる。
回路図を描く
既にある回路図を見ながら実装するのはやれば出来ると思うので、勉強の為に回路図を描く所からやろう。 本文の内容に沿って発展させていきたい所存。
描くのはタブレットでやりたいが、そうすると本を読むのに別の何かが欲しいな。 Paperwhiteで読めるか?お、読めるな。これで行こう。
リセットアドレス
リセットアドレスは0にしたい、と書いてあるが、NULLを読むとコードが読めてしまうのはちょっと気分が悪いので、mipsのメモリマップの先頭アドレスである0x0040_0000にする。といってもROMもメモリも14bitしか線を用意してないので、下しか使わないが。
beqまでの回路図を作る
本書に従い、まずはlwだけの回路を作る。
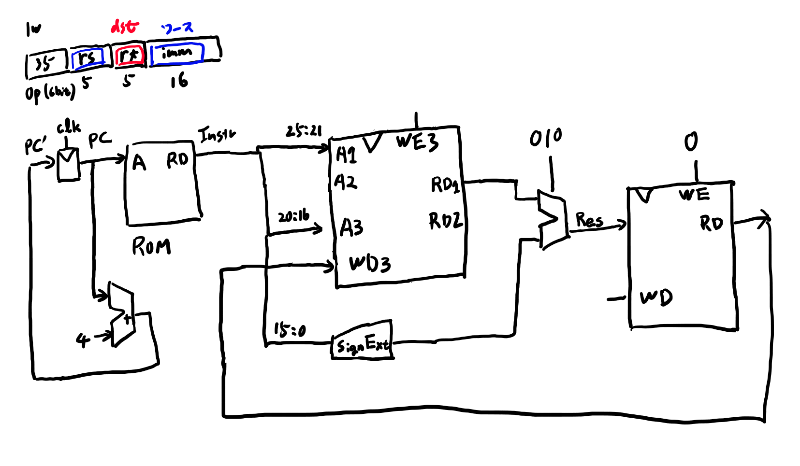
おぉ、なんかこれめっちゃ楽しいな。ではswも対応してみる。
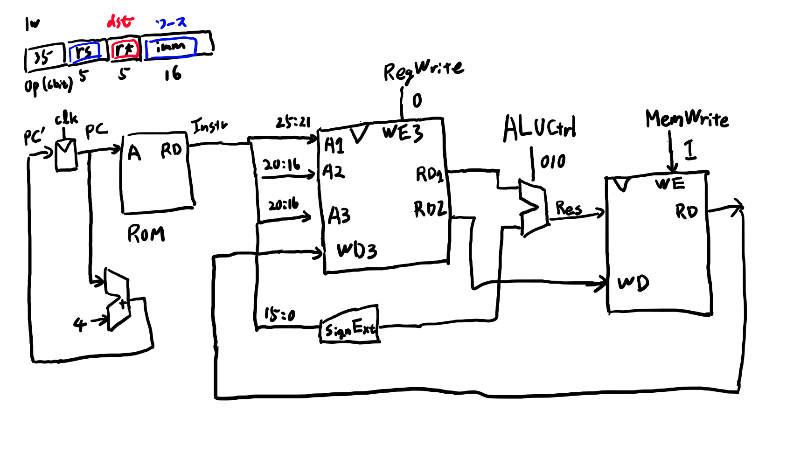
これ、ひたすら貼っていくと凄い重いページになりそうだな。まぁいいか。
次はR形式。
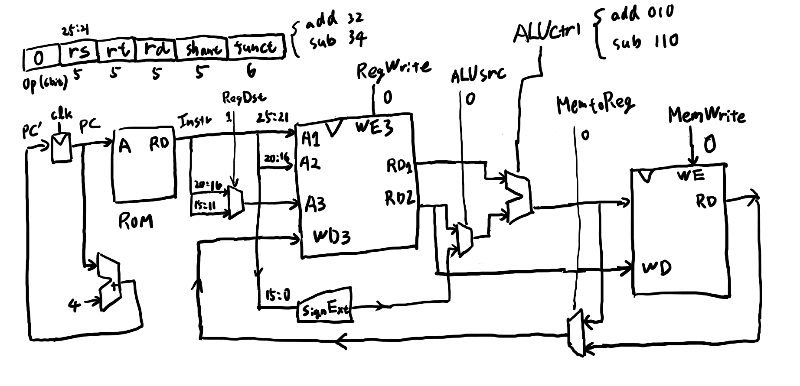
次にbeq。
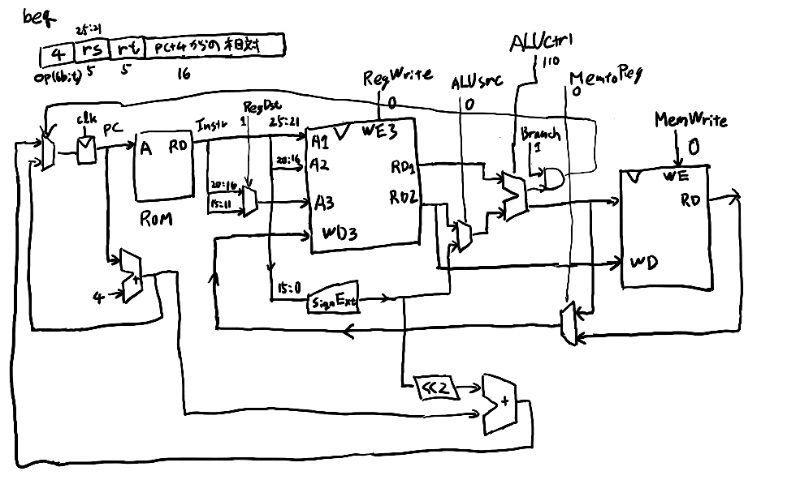
割とストレートに実装出来るな。
beqまでの制御部を作る
jとかaddiも実装してみても良かったのだが、あまり制御部が無い状態で先に進むのも不安。 ここまでの制御部を作ってみるかな。
制御信号とニモニックの表を作って埋めてみよう。
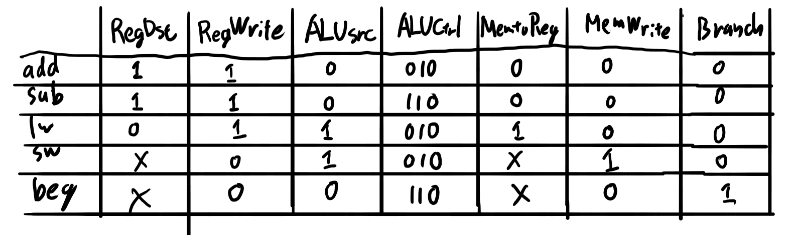
ALUCtrlは今の所2種類しか無いので3bitは不要ではあるが。
本文の解説を見るとaddとsubを一つにまとめて、ALUCtrlは別のテーブルを作っているな。 そっちの方が筋は良さそうだが、YAGNIの精神的には自分の方が良い気もする。
まぁいいや。とりあえずここまでは機械語から自力で作れそうに思える。
addiとjを考える
addiはほとんどlwと一緒だよな。違いはMemtoRegくらいか?まぁあってるかは分からんが難しい事は無い。
jはデータパス自体に変更が要るな。Instrから26ビット取ってきて2ビットシフトしたり、現在のPCの上と連接したりしてPCを作り、 PCの前の所にマルチプレクサと制御線を追加する必要があるか。
この辺はやれば出来そうなので本文の答えをそのまま使ってしまっていいかな。
System Verilogで実装してみよう
回路図はだいたい描けたので、実際にここまでの機能で実装してみよう。テスト書くの大変そうだが。
方針を考える
mipsという名前のモジュールを作ろうとしたが、これに命令メモリが入ったりするのはおかしい気がする。 PCとかフェッチはCPUの機能じゃないよな。 外部とのインターフェースはピンの接続になる訳だ。 どこがプロセッサか、というのを考えるのはちょっと難しいな。
まず全部をつなげる、allというモジュールでも作るか。名前にセンスを感じないがまぁいいだろう。 ここに全部つなげていく過程で適切なモジュールの切り分け方が分かると期待したい。
書いてみようとして足りない項目は制御部か。これは組み合わせ回路で、opとfunctを付け取って出力を生成すればいいな。
まず制御ユニットを作り、次にallにメモリやらレジスタファイルやら必要な構成要素を作ってつなげてみよう。 よし、この方針でいく。
制御ユニットを作る
表7.4でALUOpだけそのままALUCtrlを出すように変えたものをひたすら実装する。 何も考えずにANDとORでつないでassignする。これが一番直接的で良いな。
testbenchを実行するとなんか以前のaluの波形しか出ない。 なんで? といろいろごちゃごちゃやって、SourcesのSimulation Sourcesで目的のtest benchをSet as topすると動いた。
allに全部つなげて、整理方針を考える
一通り全部つなげてみた所、結構長いコードになった。 これはmain関数に全部書かれているのと同じような感じだな。 テストを書く前に、ちょっと整理する方法を考えたい。
プロセッサとはどこを指すのか。instrを食わせて、outputの線を出すのがいいな。 outputはどこだろう?模範解答をチラ見するとメモリとROMを分けていた。これは分かるな。 レジスタファイルはプロセッサの中になっている。ふむ。
入力はinstrだよな。
次のPCを返したい気はするのだが、PCPlus4が要るな。 ちょっとここは後回し。
データメモリはアドレスとwdとweを入力とする。これを生成するのはいい。 メモリからの出力はどうなるのだろう?これはレジスタファイルに書き込む場合もあるから要るよな。 つまりプロセッサから見るとメモリの出力はinputとして降ってくるように見えるのかな。 アドレスとwrite dataとwrite enableはプロセッサが出力してその結果が返ってくるはずなのにそれがinputで入ってくるってちょっと面白いな。 clkが入ってきた時に定常状態になればこのinputの値が更新される訳だよな。ふむ。
つまり、CPUのインターフェースはこんな感じか?
module mips(input logic clk, input logic [31:0]instr, pcPlus4, memReadData,
output logic [31:0] newPC, memAddress, memWriteData,
output logic [...] ctrls);
ちょっと模範解答のコードを見てみよう。
module mips(input logic clk, reset,
output logic [31:0] pc,
input logic [31:0] instr,
output logic memwrite,
output logic [31:0] aluout, writedata,
input logic [31:0] readdata);
自分のにはresetが無いな。これってPCのフリップフロップしか使わないかと思ってた。 制御線はCPUの外には出ないのか。確かに。
aluoutというのはmemAddressという奴だな。readdataがinputになっているのは自分の理解が正しい事を示しているな。よしよし。
おや?pcPlus4が無いのにpcをoutputしている。そんな事出来るのか?ちょっとコードを覗いてみよう。
あー、そうか。PCのフリップフロップも中に持っているからこの値はCPUの中にあるのか。 レジスタの他にフリップフロップも状態を持っている訳だな。
なるほど。そう考えるとmipsのoutputにあるnewPCは、フリップフロップに食わせるPC’の事じゃなくて、ROMのaddressに食わせる線か。 なるほど。
この理解を元に自分のコードをもう一度書き直して同じになるか確認してみよう。
module mips(input logic clk, reset, input logic [31:0]instr,memReadData,
output logic [31:0] nextInstrAddress, memDataAddress, memWriteData,
output logic memWriteEnable);
だいたい同じになったな。よしよし。
こうなるようにextractしてみた。 結果はmips側はまだごちゃごちゃしているな。だが、模範解答のようにdatapathを分けるといいか?と言われると、そうでも無い気がする。 回路図とマッピングが素直な方がデバッグはしやすいよな。
テスト方法を考える
本文を読んでみると、図7.60にアセンブリで書かれたテストコードとそのバイナリ値が載っていて、 これを実行したらアドレス84に7が書かれる、が期待値、みたいな事が書いてある。 このバイナリはまだ対応していないaddi, or, and, sltが使われている。
でもいろいろ足す前に、とりあえず現状の命令で動くかどうかを確認したいよなぁ。 そもそもにちょっとずつ動かすバイナリは複雑にしていきたいよな。
そう考えると、テスト用のアセンブリとバイナリをどっかにずらずらおいてテストを書いていきたいな。
まず簡易アセンブラが要るな。どうしよう。C#かgolangあたりで作るか。
あとテストを考えるとレジスタファイルは分離している方がいいな。mipsの外に置こう。
ネーミングコンベンションを決める
いまいち本文のコードの通りだとぱっとしないので自分なりに決めてみる。
- モジュール名は小文字
- モジュールのインスタンスの変数(dutとかの所)は大文字始まりのcamel
- 内部線や引数は小文字始まりのcamel
- 制御線は大文字始まりのcamel
2と4はかぶってるが曖昧性は無いだろう。4はテーブル作った時に大文字始まりにしてしまったのでそれに合わせたい、というのがある。 また制御線は一時的な物に比べて重要性は高いので目立つようにしておきたい気もするので。
簡易mipsアセンブラを作る
goのWSL環境を作っていたら、WSL1ではVSCodeからデバッグ実行が出来ない、との事。 別にデバッグ実行無しでもいいんだが、やっつけに面倒な環境を選ぶ事も無いよなぁ、という事で.NET Core SDKを入れてC#で作る事にする。
なんかOmnisharpがSDKを見つけられないとかいう。 以下の問題っぽい。
The SDK ‘Microsoft.NET.Sdk’ specified could not be found. · Issue #2937 · OmniSharp/omnisharp-vscode
結構同じようなissueが昔から出来ては消え出来ては消えしていて、 今でも数日前に普通に報告があるので割と良くある問題の模様。
以下の解決策で治る。
The SDK ‘Microsoft.NET.Sdk’ specified could not be found · Issue #3160 · OmniSharp/omnisharp-vscode
そのあとなんかnunitが解決できないとか言っていたが、NUnit Explorerを入れて設定を見ていたらいつの間にか治った。そのせいとも思えないが。 そして無事codelenseも出るようになる。
それにしても.netとは思えないほどびっくりするほど不安定だな。
ただ解決してしまえばデバッグ実行でUnit Testが動かせるようになった。 生きてはいけるな。
環境設定は苦労したが、慣れてくればまぁまぁ我慢できる環境だ。 なぜかExtract Methodが右クリックじゃなくてツールチップ的な電球の中だったりたまにinlineしてくれないケースがあったり、using足したりするのがかったるかったりライブラリをコマンドラインから追加するのがかったるかったりとかいろいろあるが、かき捨てツールを手軽に書く環境としては結構いいかもしれない。
VSCodeはC#の開発環境としてはあんま頑張ってないのね。JSの方が素直な気がした。 ただ頑張ってないと分かって使う分には我慢できるラインではある。
という事でアドレス解決無しのカスタムアセンブラが出来た。swとかlwもヘンテコなシンタックスは導入せずに普通に第三引数でオフセットを指定する。
デバッグいろいろ
リセット時の振る舞いがいろいろバグっていたりbeqの時のシフトがずれてたりバグが幾つかあって、テストを足しつつ理解を深める。 初期のころはデバッグで学ぶよな。 ついでにアセンブラ作っておいて良かった、という位には使った。
このおかげで大分System Verilogでのテストの書き方も理解してきて、まぁまぁ原始的なやり方では開発出来るくらいにはなってきた気がする。
一応本に書いてあるテストベンチは無事動いた。 感動の瞬間だね。頑張った。
7章のパイプラインmipsプロセッサ
マルチサイクルは解説を読んだら理屈は理解出来たし、 どうせパイプライン実装するならやらなくていいか、という気がしたので実装はしない。
そしてパイプライン。
まずは解説を読む
ここまではVerilogレベルで無ければもともとまぁまぁちゃんと理解していたが、 パイプラインあたりからはVerilog以前の理解もまぁまぁ怪しいので、まずは解説を真面目に読む。 昔やったはずだが忘れてるのだった。
最初はマルチサイクルを発展させたものかと思っていたが、 良く見るとALUは再利用しないんだな。コントローラは状態マシンになるのでは無くて、単一サイクルと似たような制御信号を発信する。 だがそれがフリップフロップを使って伝播していくのか。 ではリセット時はそれぞれのフリップフロップがnop的な信号を伝播するようにしておかないとダメなのかな。
ハザード回り、軽く読んだが実装出来るほどは理解出来てないな。とりあえず実装してみる必要はありそう。
DRAMとの接続は良く分からない
パイプラインの設計を理解してハザードの延長でDRAMのアクセスを待てるかと思ったが、 これを外とつなぐのはもうちょっと考えるべき事が多い。 DRAMのデータがいつ使えるか、というインターフェースがどうなっているか、 とか考えると、DRAMは別のクロックだったりするしそう楽じゃないよなぁ。 8章がメモリやキャッシュという事で読んでみたがこの辺の事はあんまりちゃんと書いてない。 うーむ。
という事でハードの人に聞いてみたら、普通は別のステートマシーンがあって、FIFOでつないだりする、との事。 へぇ、それはこの本読むだけでは良く分からない所だな。
SRAMに遅延を入れてFIFOで単一サイクルのCPUとつなげる、というのが一番単純なそっち方向の変更の模様。 DRAMとつなげるのはちゃんとやりたいが、この本ではちゃんとは扱ってないようだ。
という事でまずパイプラインのプロセッサを作り、次に単一サイクルのプロセッサをFIFO越しに外のシステムとつなぐ、というのを書いていこう。 後者はどうやったらいいか分からんのでどこかで勉強が要りそう。 AXIとか触った事無い。
パイプラインのデータパスの回路図
とりあえず単一サイクルのデータパスの図、7.45をスタート地点として、回路図や真理値表を書いて行こう。
まずは図7.45を写す。こんな感じか。
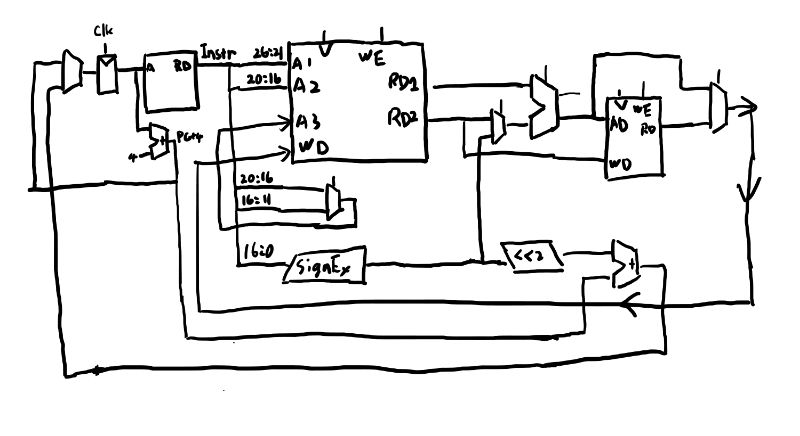
さて、これをパイプライン化していく。答えの図はあるのだが、図は見ないでやってみよう。
まず、フェッチ、デコード、実行、メモリ、書き戻し、に分けるという話だった。 それぞれの場所にフリップフロップを入れて、何を通すのかを考えてみよう。
まず、レジスタのWrite Addressについて考える。 これはWDが確定するまでもっていく必要がある。WDは一番右の書き戻しで確定するので、ここまで連れていく必要がありそう。
次にPCBranchを考える。これは、実行フェーズで確定する。 あれ?でもパイプライン的には既にフェッチはしている必要があるよな。 つまり、PCPlus4はむしろ最初のフリップフロップも持ち越さずに入るのが正しい。 あとからこれが無効になったら途中の状態を捨ててフェッチからやり直す必要がある訳だな。
ではPCBranch、つまりbeqで確定するPCはどこまで持ち越す必要があるか? beqが成立するかは実行フェーズのZero線で決まる。 だから実行フェーズまでか?という事はここまでPCPlus4も持ち越す必要があるな。
描いてみると、持ち越す必要があるのは実はRegWriteAddressとPCPlus4だけか。 こんな感じか?
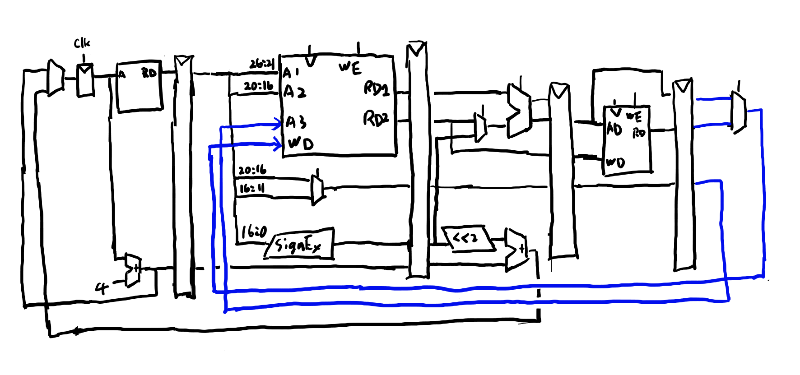
回答の図と比べるとPCBranchを回答ではメモリフェーズまで持ち越しているな。 ああ、そうか。フェッチという時間のかかるフェーズが十分に終えられるだけの猶予を与えるには、 加算という一応時間がかかる事になっている事をその前に挟んではいけないのか。
修正して以下で良さそうね。
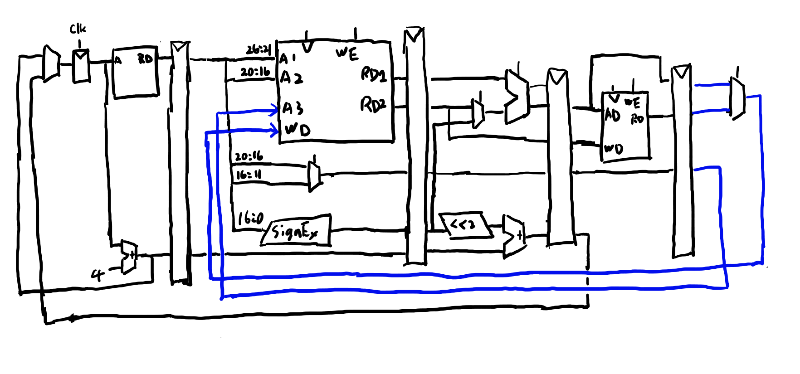
RegDstを決めるマルチプレクサはデコードフェーズでも良い気はするな。 フリップフロップ5bit分無駄をしているが、まぁどっちでもいいのか。
ハザード以外を実装してみる
制御ユニットはほとんどシングルサイクルのケースと変わらない気がするので、とりあえずハザードは無視して実装してみよう。
間のフリップフロップは汎用のにすべきか、必要な線だけを持った奴を毎回作るべきか… 汎用の方が読みにくそうなのでコピペで作るか。
フリップフロップは制御ユニットの方も必要になるので、まずは各ステージのデータパス部分を実装しよう。 ステージは_stageを名前の最後につける事にする。 中で何もせずに次のステージに流すものはステージモジュールの中は通さず、外のフリップフロップの所でつないでしまう事に。
ステージの間のフリップフロップはfetch2decodeのように、ステージの名前を2で区切るモジュール名にする。
まずはデータパスを実装して並べる
制御ユニットに何が必要かとか間のフリップフロップをどうすべきか、という事を明らかにする為に、まずはデータパスを実装して各ステージを配線してみよう。
データパスの実装は、フェッチの所はハザードを無視するとどう書いていいか分からないが、他のデータパスの実装はだいたいは出来た。 writebackは単なるマルチプレクサ一つになってしまっているが。
各配線は、ステージ名をsuffixにする事にする。
こうして必要な制御線と持ちまわるものは読み解けそうな所までは来た。
制御ユニットを考える
制御ユニットは単一サイクルと同じでいいかな? とりあえず持ってきて配線してみよう。
制御線は何を持ちまわるか考えてみる必要があるな。 ctrlunitはフェッチした後しかできないので、ステージとしてはDかな。
持ちまわる必要があるものを考えるにあたり、最後から並べていくのがいいか。
ブランチはどこで決まるのだろう?ALUのzeroが出てからだから、その次のメモリステージか。 じゃあBranchはBranchMだな。
WriteBackステージ
- RegWriteEnableW
- MemtoRegW
Memステージ
- MemWriteEnableM
- BranchM
Execステージ
- ALUCtrlE
- ALUSrcE
Decodeステージ
- RegDstD
一通り突き合わせてみると単一サイクルから新しくなっているものは無いな。 そのままで使いまわそう。 Jumpはまだ実装してないので無駄な線があるな。
よし、あとはDecodeから持ちまわる必要がある間の配線を決めてフリップフロップにつっこんでいけばいいんだな。
めちゃくちゃめんどくさいな。コントロール線はまとめるか。
つなげてデバッグして、簡単なケースで動くのは確認。 ハザードを直さないと動いているかはよく分からんなぁ。
ハザード処理を実装する
今実装している範囲だと、ハザードの対処としては
- フォワーディング
- ストール
- フラッシュ(分岐予測失敗時の、途中結果を捨てる処理)
の三つのケースがある。 本文の解説に従って順番に実装していこう。
フォワーディングを実装する
まずは理屈を理解する。図7.50を眺めながら考える。 読みだしたレジスタの値が間違えていた時に、それを先のステージから横流しされてきたデータに差し替える、というのがやるべき事。
lwは間に合わないのでlwのケースはストールで対処するから、ここではR形式などのケースを考える。 つまりExecが終わった時点で本当の値が確定している。
decode時点でレジスタを読む時に、そこより先のフェーズは
- Exec
- Mem
- WriteBack
の三つがある。 しかしWriteBackではそのサイクル内で書き込みが起こり、同じタイミングで読みだす場合は正しい値が読める実装になっているのが期待値。
本当になっているかはそこまで自信も無いが、writeはlockのposedgeで書くがreadはassignされる。 だから一定時間たてば書かれた値が反映されるから平気か。
という事で考慮すべきはExecとMem、という事になる。
現在Execを実行している、ハザードを解決すべき命令を3と呼ぶ。 その時点でMemを実行している命令を2、writebackを実行している命令を1と呼ぶ。
基本的には3が使っているレジスタが、2か1が書き込む予定のレジスタとかぶっていると横流ししてもらう必要がある。 書き込む必要のあるレジスタはRegWriteAddrで、これはdecodeステージで決定している。 だから命令2も命令1も何に書く予定かはわかる。(変数名は私の実装のコードに準拠)
横流ししてもらうのは、aluResMとaluResW。よし、だいたい理解出来た気がする。 (追記: これはバグってた。aluResWはアドレスなのでmemReadDataWが正しい。regWriteDataWがより適切)
実装してみよう。 結構バグったが無事動いた。かなり理解も深まった。やはりこうやって試行錯誤して理解するのだよな。
ストールの実装
次はlwのストールの実装。まずはテストを作る。 作っておいて良かった簡易アセンブラ。こういうのをやっつけで作るスキルって大切だよな。 C#という選択はもうちょっといいの無いかな、という気もするが。 動かない事を確認。
次にどういうストール処理が必要かを理解する。図7.52を眺めながら考える。 データが使えるようになるのはwritebackのフェーズだ。 その間に次の命令はMemまで行ってしまうが、 これではALUに間違った値が入ってしまう。
という事でForwardingする前提でも一期ストールする必要がある。
ストールをする時はそれ以前も全部止める必要がある。 止めるのは、fetchとdecodeか(execまで行っているのはforwardingで対処できるので)。 execはバブルにしないといけない。
よし、必要な挙動は理解した。次にそれの実現方法を考えよう。
ストールする条件は、lw命令がレジスタに書く事が分かっている時だよな。 lw命令がレジスタに書くのはMemtoRegで決まる。これはDecode時には確定する。 書き出しアドレスはregWriteAddrで、これは本ではExec時に決めているが自分はDecode時に決めている。 という事で全部でコード時に決まるな。
ブランチはちょっと複雑だがあとで分岐予測の所で対処するので置いておこう。 そうするとブランチの処理自体はこれで良い。 デコードは誤った値を読む事もあるが、これはフォワーディングで解決するので構わない。 問題となるのはexecで、これは新しい値でやり直す必要がある。
こう考えると、ストールさせるのは本当はexecだけで良い。 だがどうせ一サイクルは無駄になるが、これだと次のexecにもforwardingしなくてはいけない。
それよりはデコードの時点で止める方がforwardingが必要なのは一つだけになるので楽か。 ふむ。デコードを止めるには、fetch2decodeをもう一回同じ値で動かせばいい。 またfetchをもう一回やるには、PCの所のFFも止める。
decodeの時点でストールかどうかが決まり、この時のdecodeは次のexecには伝播させない。
つまり、lw命令だと分かったら、
- decode2execのレジスタの内容を捨てる
- fetch2decodeの書き込みを無視
- PCの書き込みを無視
で良いか。
ストールする条件は、デコードが終わって使うレジスタが確定しないと分からない。 rsはいつも使うからいいが、rtは使わない事があるか。 使うかどうかはALUSrcで判定出来るか。
つまり以下のどちらかか?
- RsDとregWriteAddrEが一致かつMemtoRegEが真
- RtDとregWriteAddrEが一致かつMemtoRegEが真かつALUSrcDが0
教科書の記述ではALUSrcDが無いな。自分を信じるか。
では実装してみよう。
これまでのバグを踏んだりもしつつ直していって、無事動いたヽ(´ー`)ノ
制御ハザードの解決
beqが確定するのはEステージの最後か。 と思ったが本の解説を読んでいたら、decodeフェーズで等値判定をしてしまう、と書いてある。 となるとデコードフェーズか。捨てるのはフェッチの結果だけね。
ただbeqのRAWが新たに発生してしまい、これはフォワーディングで解決できる場合とストールが必要な場合がある。 RAWを考える必要があるのは、ALUの結果を書く場合(R形式など)と、lwで書く場合がある。
ALUの結果を書く場合
- 実行ステージ…ストール
- メモリステージ…フォワーディング
- writebackステージ…そのままでOK
lwの場合
- 実行ステージ、メモリステージ…ストール
- writebackステージ…そのままでOK
本にはlwの実行ステージの時にRAWが起きないように書かれているが、そんな事無いよな? errataにも訂正が無いが、、、まぁいい。自分の信じるように実装しておこう。
よし、動いた。
なんかjの対応もデコードステージなのでほとんど一緒だな。やってしまうか。
パイプラインでも本のテストベンチを動かす
本に書いてあるテストベンチを動かした所動かない。 テストベンチはいろいろな事をやりすぎているので、 もっと細分化したテストを追加する事に。作ってよかった簡易アセンブラ。
レジスタファイルの書き込みをnegative edgeでやるようにしないと、 書いたものが同じステージでは読めない、という事らしい。 assignしておけば間に合う物だと思ってたがそうでも無いらしい。 ふむ、そういうものか。
で、無事本に書いてあるテストコードが動く。 とりあえずパイプライン化したmips完成!
SIMDな拡張をやりたい
本に書いてある範囲はここまでだが、 せっかくなのでSIMDっぽいものを作りたい。
という事で以下に続く。