TPUEstimatorでのregularizationとtf.layersとtf.kerasについて
TPUEstimatorでは、真ん中のグラフは何もいじらずによきに計らってSynchronous SGDしてくれる。 だが、入力とlossのあたりはまぁまぁ専用のコードが要る。
公式にはkerasのモデルをコンバートして行う、という事になっているが、 入力とlossのあたりのコンバートはかなり不完全で、例えばencoder-decoderなどのように入力が二つあるケースだと動かなかったりする。
そこで、Inputなどは使わずに入力回りは普通にtf.placeholderを使い、 間のレイヤはkerasの物を関数のように使いたい、というシチュエーションは結構あるだろう。
この時に、普段はmodel.fitがいろいろやってくれる所を、自分でやらなくてはいけなくなる。 公式ドキュメントは建前のコンバートを推すので、それが使えない時の情報があまり無く、stack overflowなどでは結構間違った事が書かれているので、 自分が調べた事を書いておく。
tf.layers.Conv1Dとtf.keras.Conv1Dがある
tensorflowにはtf.layersの下に、幾つかkerasのクラスをそのままラップしただけに見えるクラスがある。 だが、tf.layersには一部のクラスしかないので、全部がラップされている訳では無い。 たとえばGRUなどいくつかの重要なクラスはtf.kerasの下にしか無い。
tf.layersの方の実装を見てみると、例えばtf.layers.Conv1Dは以下みたいになっている。(引数は…で省略している)
class Conv1D(keras_layers.Conv1D, base.Layer):
def __init__(self, filters, ...):
super(Conv1D, self).__init__(
filters=filters,
kernel_size=kernel_size, ...)
つまり、kerasのConv1Dとbase.Layerというのの多重継承になっていて、中身はinitだけで何も定義してない。 stack overflowなどでは以上から両者は同じと言っている答えしかないがこれは間違っている。(と日本語で指摘しても仕方ないが)
tf.layers.Conv1Dの継承関係
ここからは多重継承の話になるが、keras_layers.Conv1Dは、必要な所だけを見ると、以下のような継承ツリーになっていて、
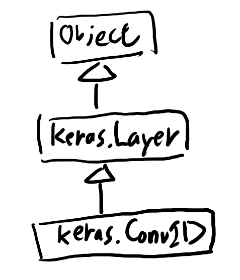
baseの方のLayerは以下。
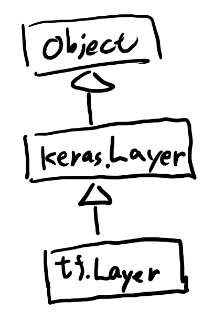
同じkeras.Layerが親にいるのでこの多重継承の解決はちょっとややこしくて、公式チュートリアルの多重継承から紹介されているドキュメントの多重継承の解決の記事を読むと、以下のように解決される。
[keras.Conv1D, tf.Layer, keras.Layer, Object]
add_loss関数
さて、ここで、add_lossという関数が問題になる。 kerasのLayerにはadd_lossという関数があって、これがregularizationのロスなどを蓄積していって、最後にfitでロスに加えてくれる。
だが、今回のようにModelクラスを使わないと、fitでいろいろやってくれる事はやってくれない。 kerasじゃない素のtensorflowだとこの辺はops.GraphKeys.REGULARIZATION_LOSSESに追加していく、という約束になっているが、kerasのadd_lossはそんな事をしてくれない。
という事で、tf.layersの方のLayerはこのadd_lossを横取りしてREGULARIZATION_LOSSESに加えてくれている。
# tf.layers.Layer
class Layer(base_layer.Layer):
...
def add_loss(self, losses, inputs=None):
...
super(Layer, self).add_loss(losses, inputs=inputs)
...
_add_elements_to_collection(
new_losses,
ops.GraphKeys.REGULARIZATION_LOSSES)
という事で、tf.keras.Conv1Dを使っていると、weightのregularizationなどのロスを取得する手段が無いが、tf.layers.Conv1Dを使っているとこのロスをREGULARIZATION_LOSSESコレクションとして取得できる。
このロスは以下みたいに加えれるのが普通の処理っぽい。
loss = tf.losses.sparse_softmax_cross_entropy(laels, logit)
regularization_losses = tf.losses.get_regularization_losses()
loss = tf.add_n([loss] + regularization_losses)
これだと自分のパラメータ数だと、l2の引数には1e-6とか入れないとまともな値にならないが、 世の中見回すとそういう物なのでそういう物っぽい。
BatchNormalizationは別の配慮も必要
regularizationとは別件だが、BatchNormalizationは移動平均を更新する為、kerasではupdate_opを溜めてfitでよきにはからう、という作りになっている。同じ理由でこれもtf.keras下の物を使っていると取得の方法が無い。 BatchNormalizationも関数として使うにはtf.layers下のを使う必要がある。
この時はupdate_opの方を細工する必要があって、それはtf.contrib.training.create_train_opを使う、とある。 tf.contrib下は廃止という話だったがこの辺がどうなるかは良く分かってない。
train_op = tf.contrib.training.create_train_op(loss, optimizer)
全部がtf.layersにある訳では無い
例えば自分が使っているものだと、以下はtf.layers下には無いのでtf.keras下を使う必要がある。
- Activation
- GlobalMaxPooling1D
- SpatialDropout1D
- GRU
ちなみにGlobalMaxPooling1Dはtf.layers下には無いが、MaxPooling1Dはある。 全部tf.layersにあってそれだけ使え、とかなら分かりやすいのだがなぁ。
ちなみにtf.layers.MaxPooling1Dは、tf.keras.MaxPooling1Dには認められていたstridesにNoneを指定すると怒られるチェックが入っている。(なんで!?)